Primary key & Foreign key 사용 예시
1. 각 테이블의 컬럼 및 데이터 확인
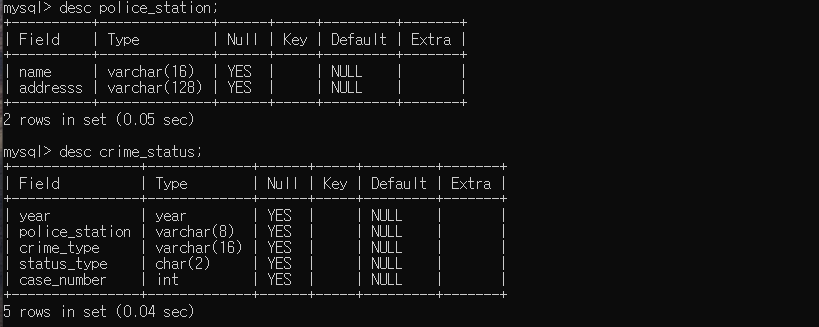
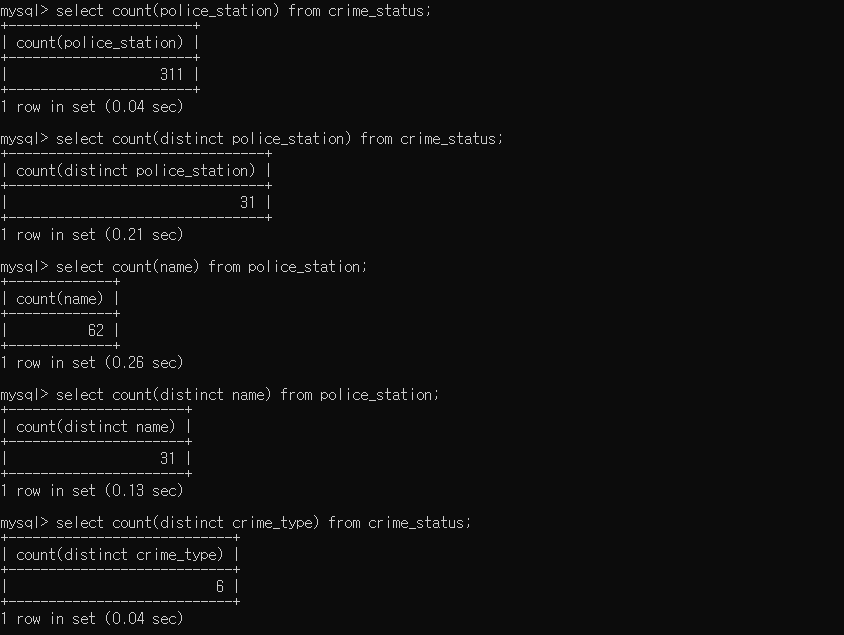
- AWS RDS에서 만들었던 zerobase 데이터베이스의, police_station 테이블과 crime_status 테이블을 사용하기 위해 각 테이블의 name, police_station 데이터의 개수를 세었다.
- 각 테이블의 name, police_staion 컬럼을 pk와 fk로 쓰기 위해서 검색해 보았고, count() 함수는 개수를 세어주는 함수이다. distinct를 사용하면 반복된 개수는 제외하고 세어준다.
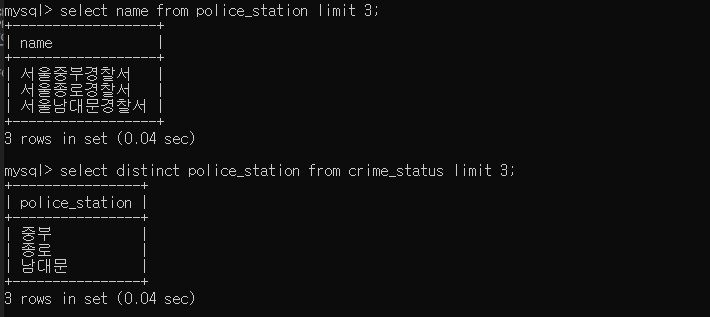
- pk 와 fk 로 사용할 두 컬럼을 조회해보면, name 컬럼이 '서울' + police_staion + '경찰서' 임을 알 수 있다.
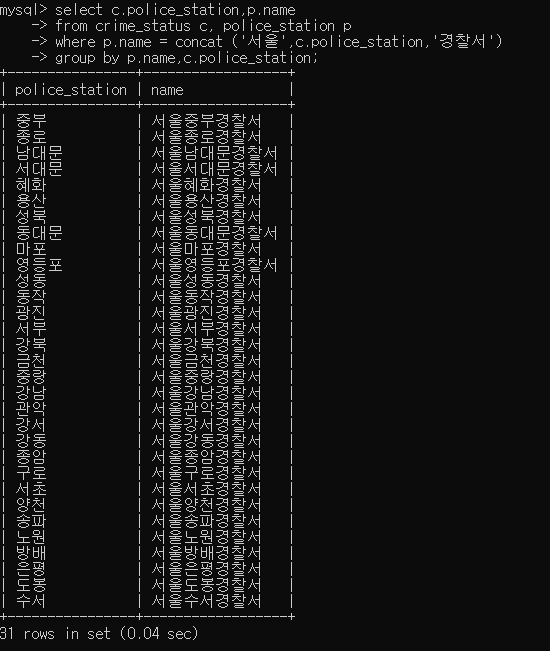
- crime_status 의 police_station 데이터값에 '서울' 과 '경찰서' 를 붙이면 name 컬럼의 데이터와 같은것을 확인했다. '서울' 과 '경찰서' 를 붙여서, 데이터 값이 같은 경우의 컬럼들을 조회하였다. 이때, 조회는 group by 를 통해 경찰서명과 이름 별로 조회를 할 수 있다.
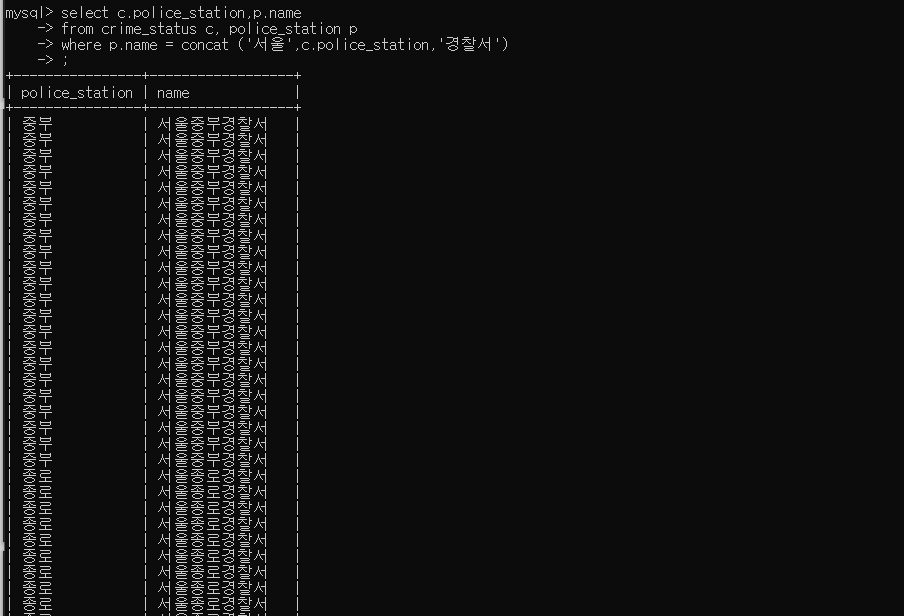
- group by 를 통해, 같은 경찰서별로 묶지 않으면 이렇게 모든 경찰서들을 조합한 행들이 전부 출력되어 반복된 행들이 많아진다.
2. pk 를 참조할 fk 새로운 컬럼 만들기

- p 테이블의 name 컬럼 값을 기본키로 지정하였고, 그 기본키를 참조하는 fk를 사용하기 위해 데이터값이 같아야한다. c 테이블에 ref 라는 컬름을 만들어서 같은 데이터값을 넣어준다. fk 는 다른테이블의 pk 를 참조하여 겹치는 값을 기준으로 쓰기때문에, 같은 값이 필요하다.
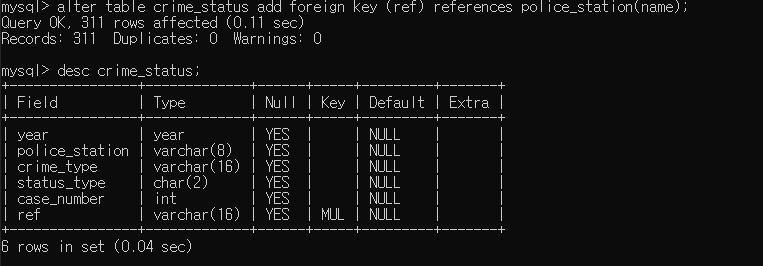
- 만든 컬럼 ref 를 fk 로 지정하고, pk 인 name 컬럼을 참조한다.
alter table crime_status add foreign key (ref) references police_station(name);
freign key가 생성된것을 할 수 있다.

- 위에서 group by 로 조회했을때, c 테이블의 police_station 데이터에 '서울' 과 '경찰서' 를 붙여서 같았던 경우의 데이터 값을 그대로 ref 컬럼에 넣는것이다.
- 즉, p.name = concat ('서울',c.police_station,'경찰서') 인 경우에 c.ref = p.name 으로, 넣는다는 뜻이다. 같은 값인 경우의 데이터를 c.ref에 넣는다!
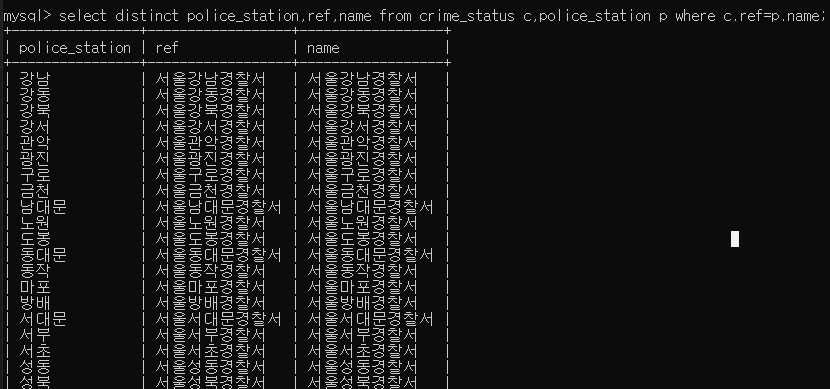
- ref 에 데이터를 넣은후, 값이 같은 경우의 데이터가 잘 들어갔는지 확인한다.
3. fk 를 기준으로 join
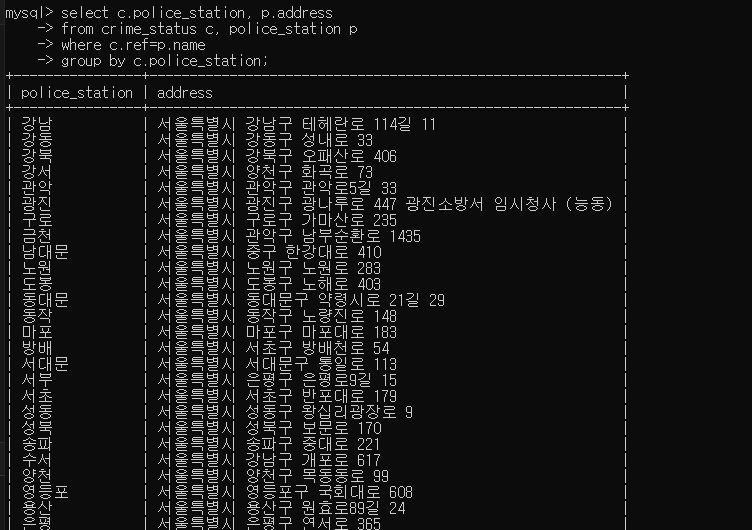
- join을 통해 출력해보고싶은 컬럼만 출력할 수 있다.

화이팅!