Intro
- Amazon Redshift 아키텍처 및 모범사례 - 김민성 솔루션즈 아키텍트(AWS) 유튜브 동영상을 기본으로 작성합니다.
Amazon Redshift
- 일반적인 데이터웨어하우스 관리비용의 1/10 비용.
- RI Redshift 사용료 선납 기능.
- Data Lake와의 통합.

데이터레이크와의 통합
- Amazon S3 DataLake와의 완전한 유기적인 관계.
- 초기 Datawarehouse 구성시 미래의 데이터를 고려하여 필요 이상의 노드를 구성하여 사용함. 하지만 최근 3개월의 데이터만 Redshift에 두고 3개월 이전의 데이터는 S3에 저장하는 것이 좋다. 즉, 자주 조회되지 않을 과거의 데이터를 S3 DataLake에 저장하여 관리하는 것이 좋다.
- Redshift Spectrum을 통해 Join도 가능하고 쿼리 실행시 비용발생.

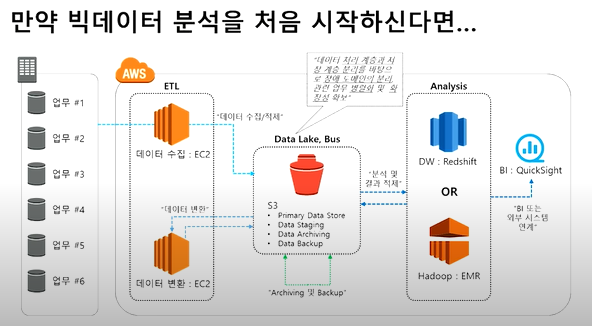
초기 구성 예시
- 프로젝트 초기에는 Redshift만을 가지고 분석이 가능하나 프로젝트가 성숙함에 따라 다른 기능을 추가하기 좋음.
Architechture
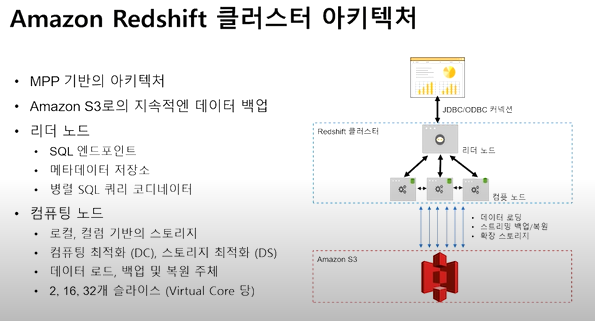
Amazon Redshift 클러스터 아키텍처
- 리더 노드 : 옵티마이저를 통해 쿼리 Plan을 컴퓨팅 노드에 전달함.
- 컴퓨팅 최적화(DC) : SSD 사용. 컴퓨팅 성능이 중요할 경우 사용.
- 스토리지 최적화(DS) : HDD 사용. 저장 성능이 중요할 경우 사용.
- 대규모 병렬 컴퓨터(Massively Parallel Computer, MPP) : 각각의 독립적인 노드들이 최소 하나의 프로세서와 자체 메모리로 구성되어 있고 작업을 병렬로 처리한다.
- 슬라이스 : 컴퓨팅 노드에 CPU에 따라 슬라이스를 가지고 쿼리 수행의 주체.
결과 캐싱 - 1초 미만의 쿼리 응답 속도
- 쿼리 실행 시간을 단축을 위한 쿼리 결과 메모리 캐싱
단기 쿼리 가속화(Short Query Acceleration : SQA)
- 장기 쿼리로 인한 체감 성능 저하 완화 및 동시성 확보
노드 선택의 기준
- 노드 타입 및 클러스터 사이즈 변경도 가능하나 변경시에는 데이터를 넣는 것은 불가능하다.

데이터 및 스키마 모델링
Columnar 스토리지
- 적절한 자료형 선택하여 메모리 낭비를 줄여야 한다.

스키마 디자인
스타 스키마
스노우플레이크 스키마
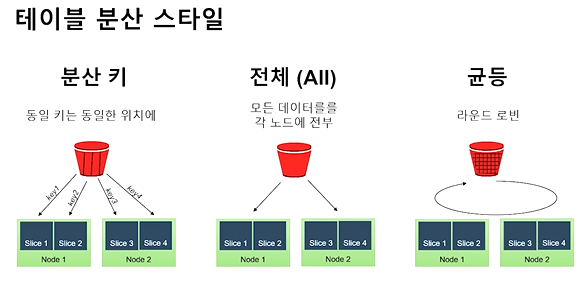
테이블 분산 스타일
- 분산키 : 동일 분산키를 갖는 레코드는 동일 슬라이스에 저장. Group By, join 사용할 때 좋음.

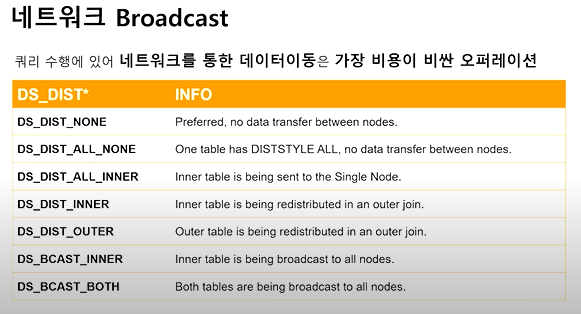
- INFO
- Preferred, no data transfer between nodes.
- One table has DISTSTYLE ALL, no data transfer between nodes.
- Inner table is being sent to the Single Node.
- Inner table is being redistributed in an outer join.
- Outer table is being redistributed in an outer join.
- Inner table is being broadcast to all nodes.
- Both tables are being broacast to all nodes.
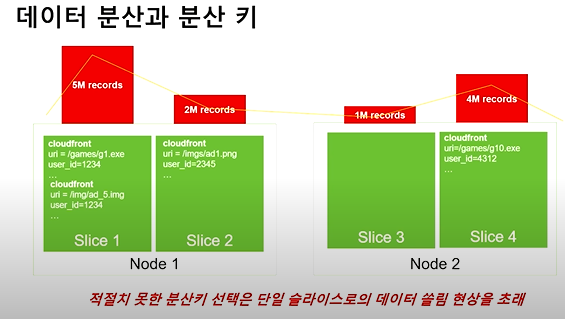
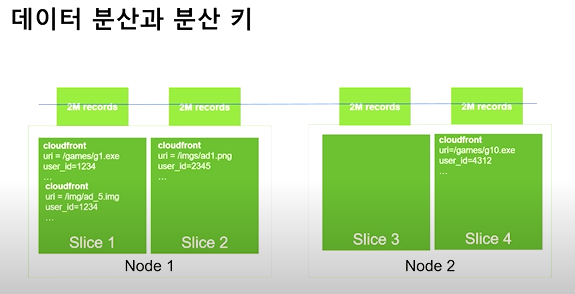
데이터 분산과 분산 키
- Redshift는 리더 노드가 쿼리 플랜을 만들어 실행파일을 만들어 컴퓨팅 노드에 배포하여 실행결과를 받아 통합한다.
- Redshift가 병렬처리가 가능하지만 단일 Slice에 데이터가 쏠려 있다면 하나의 Slice가 완료 될때까지 대기하기 때문의 대기 시간이 걸리게 된다.
- 300만개 이하의 로우의 경우 데이터 분산 타입을 전체 (ALL)로 선택해도 무방.
- 경우에 따라 모두 다르기 때문에 꼭 확인하는 것이 필요함.
- Fact Table은 Even으로 Dimension Table은 ALL로 지정하라.

데이터 정렬
- Redshift는 1MB의 블록단위로 데이터를 저장함.
- Zone Map : 각 Block에 대한 최대값 및 최소값에 대한 정보 저장.

정렬 키
- Sort Key : 1개의 컬럼만 정렬.
- Compound Sort Key : 최대 6개의 컬럼 정렬 가능. 선언 순서에 따라 정렬함.
- Interleaved Sort Key : 최대 8개의 컬럼 정렬 가능. 선언 순서에 상관 없이 정렬함.



쿼리 분석 방법
- 자료 찾아보기
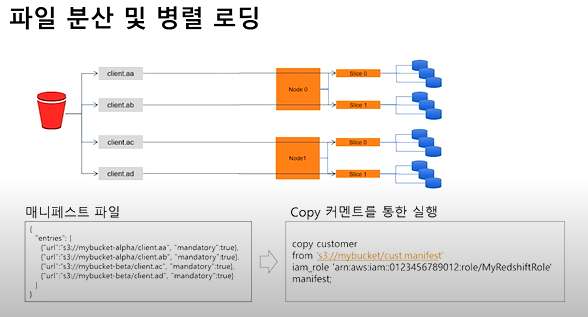
파일 분산 및 병렬 로딩
- 슬라이스 갯수 별로 파일을 만들면 더 빠르게 사용 가능.
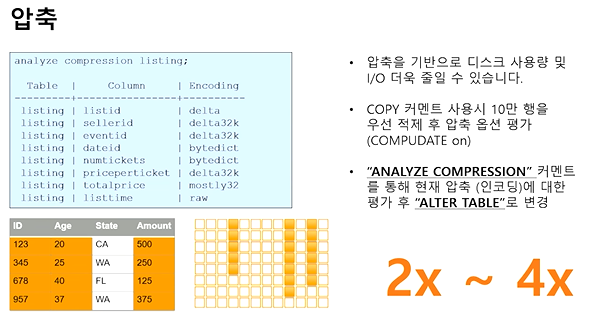
압축
- 사용방법 알아보기
기타

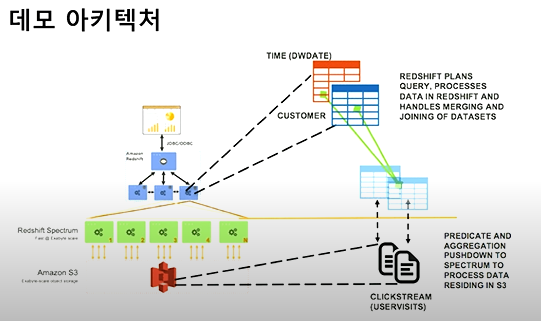
Redshift Spectrum
- S3의 수천개 이상의 노드들을 활용하여 쿼리 실행.
- S3의 prefix를 이용해 파티셔닝 가능.
- 쿼리당 비용 발생.(TB당 $5)
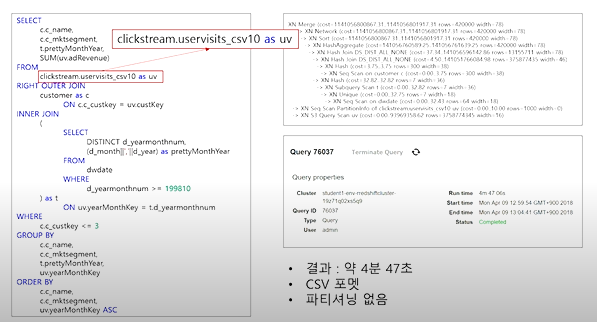
- 파티셔닝 전 결과
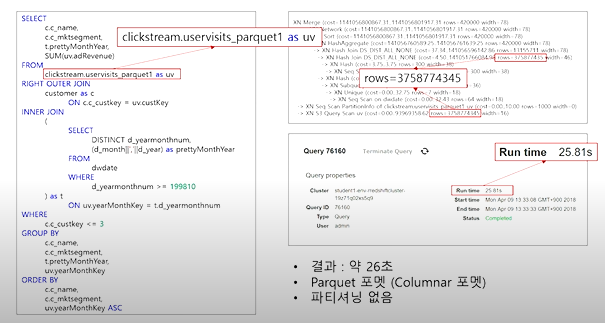
- 파티셔닝 후 결과
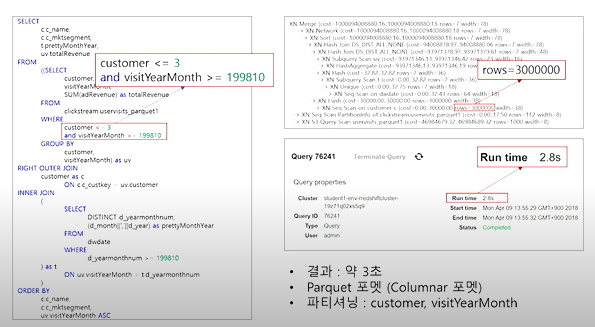
Best Practice

파일 형식 변경 방법

Reference

2023