Batch Pipeline Example
Airflow Graph View
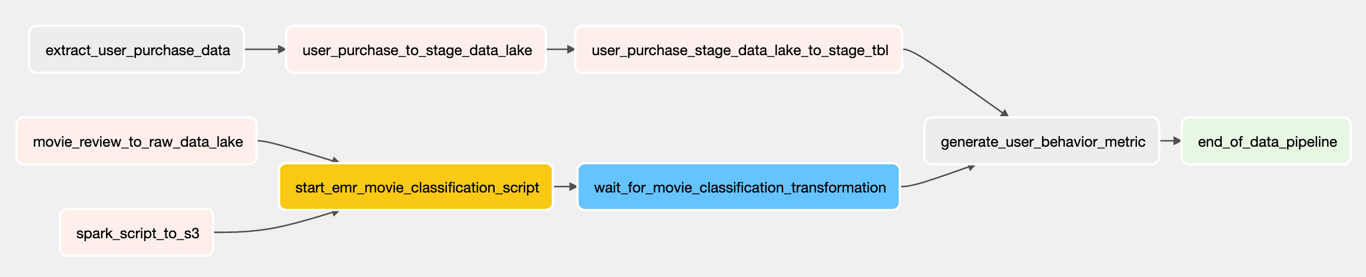
- 유저 구매 데이터를 RDB -> S3 -> RedShift Spectrum -> Redshift
- 영화 리뷰 데이터를 csv -> S3 -> EMR -> S3 -> RedShift Spectrum -> Redshift
- 최종적으로 구매 데이터와 리뷰 데이터를 이용하여 유저 분석데이터를 Redshift에 로드한다.
csv 데이터를 DataLake로 로드

extract_user_purchase_data = PostgresOperator(
dag=dag,
task_id="extract_user_purchase_data",
sql="./scripts/sql/unload_user_purchase.sql",
postgres_conn_id="postgres_default",
params={"user_purchase": "/temp/user_purchase.csv"},
depends_on_past=True,
wait_for_downstream=True,
)- extract_user_purchase_data : PostgreSQL의 user_purchase의 테이블의 데이터를 user_purchase.csv로 생성한다.
- PostgresOperator : PostgreSQL 데이터베이스와 관련된 작업을 정의한다.
- dag : 포함될 dag 이름
- task_id : task 이름
- sql : 실행해야 할 SQL문
- postgres_conn_id : PostgreSQL 연결 정보
- params : 매개변수 설정
- depends_on_pase : 이전 날짜의 task 인스턴스 중에서 동일한 task 인스턴스가 실패한 경우 실행되지 않고 대기
- wait_for_downstream : 이전 날짜의 task 인스턴스 중 하나라도 실패한 경우에는 해당 DAG는 실행되지 않고 대기.
COPY (
select invoice_number,
stock_code,
detail,
quantity,
invoice_date,
unit_price,
customer_id,
country
from user_purchase
) TO '{{ params.user_purchase }}' WITH (FORMAT CSV, HEADER);- CSV : csv 파일형식으로 파일을 생성한다.
- HEADER : csv 파일 문서 상단에 헤더를 포함하도록 한다.
user_purchase_to_stage_data_lake = PythonOperator(
dag=dag,
task_id="user_purchase_to_stage_data_lake",
python_callable = local_to_s3,
op_kwargs={
"file_name": "/temp/user_purchase.csv",
"key": "stage/user_purchase/{{ ds }}/user_purchase.csv",
"bucket_name": BUCKET_NAME,
"remove_local": "true",
},
)import os
from airflow.hooks.S3_hook import S3Hook
def local_to_s3(
bucket_name: str, key: str, file_name: str, remove_local: bool = False
) -> None:
s3 = S3Hook()
s3.load_file(filename=file_name, bucket_name=bucket_name, replace=True, key=key)
if remove_local:
if os.path.isfile(file_name):
os.remove(file_name)- s3 버킷에 user_purchase.csv 파일을 저장한다.
- S3Hook() : Interact with AWS S3, using the boto3 library.
- load_file() : 로컬 파일을 S3에 로드한다. ( filename=로드할 파일 이름 , bucket_name=파일을 저장할 버킷의 이름 , replace=key를 덮어쓸지 여부를 결정하는 플래그, key=파일을 가리키는 S3 key )
- python_callable : 호출할 Python 함수.
- op_kwargs : PythonOperator에 인자로 전달할 값.
user_purchase_stage_data_lake_to_stage_tbl = PythonOperator(
dag=dag,
task_id="user_purchase_stage_data_lake_to_stage_tbl",
python_callable=run_redshift_external_query,
op_kwargs={
"qry": "alter table spectrum.user_purchase_staging add if not exists partition(insert_date='{{ ds }}') \
location 's3://"
+ BUCKET_NAME
+ "/stage/user_purchase/{{ ds }}'",
},
)from airflow.hooks.postgres_hook import PostgresHook
import psycopg2
def run_redshift_external_query(qry: str) -> None:
rs_hook = PostgresHook(postgres_conn_id="redshift")
rs_conn = rs_hook.get_conn()
rs_conn.set_isolation_level(psycopg2.extensions.ISOLATION_LEVEL_AUTOCOMMIT)
rs_cursor = rs_conn.cursor()
rs_cursor.execute(qry)
rs_cursor.close()
rs_conn.commit()- S3의 버킷을 spectrum.user_purchase_staging 연결한다.
- PostgresHook : redshift를 연결한다.
- set_isolation_level : 트랜잭션 격리 수준에 대한 정보를 설정한다.
- ISOLATION_LEVEL_AUTOCOMMIT : 트랜잭션 사용이 필요없을 때 사용한다.
- ISOLATION_LEVEL_READ_UNCOMMITTED : 트랜잭션 처리 중인 데이터를 다른 트랜잭션이 읽는 것을 허용.
- ISOLATION_LEVEL_READ_COMMITTED : 트랜잭션이 커밋된 데이터만 다른 트랜잭션이 읽도록 허용.
- ISOLATION_LEVEL_REPEATABLE_READ : 트랜잭션 내에서 쿼리를 두 번 이상 수행할 때, 첫번째 쿼리에 있던 레코드가 사라지거나 값이 바뀌는 현상을 방지함.
- ISOLATION_LEVEL_SERIALIZABLE : 트랜잭션 내에서 쿼리를 두 번 이상 수행할 때, 첫번째 쿼리에 있던 레코드가 사라지거나 값이 바뀌지 않고 새로운 레코드가 나타나지 않음.
- ISOLATION_LEVEL_DEFAULT : 외부의 설정된 값을 사용한다.

movie_review_to_raw_data_lake = PythonOperator(
dag=dag,
task_id="movie_review_to_raw_data_lake",
python_callable=_local_to_s3,
op_kwargs={
"file_name": "/data/movie_review.csv",
"key": "raw/movie_review/{{ ds }}/movie.csv",
"bucket_name": BUCKET_NAME,
},
)- s3 버킷에 movie_review.csv 파일을 저장한다.
spark_script_to_s3 = PythonOperator(
dag=dag,
task_id="spark_script_to_s3",
python_callable=_local_to_s3,
op_kwargs={
"file_name": "./dags/scripts/spark/random_text_classification.py",
"key": "scripts/random_text_classification.py",
"bucket_name": BUCKET_NAME,
},
)- s3 버킷에 random_text_classification.py 파일을 저장한다.
start_emr_movie_classification_script = EmrAddStepsOperator(
dag=dag,
task_id="start_emr_movie_classification_script",
job_flow_id=EMR_ID,
aws_conn_id="aws_default",
steps=EMR_STEPS,
params={
"BUCKET_NAME": BUCKET_NAME,
"raw_movie_review": "raw/movie_review",
"text_classifier_script": "scripts/random_text_classifier.py",
"stage_movie_review": "stage/movie_review",
},
depends_on_past=True,
)- EMR에 처리 단계를 추가한다.
3개의 처리 단계를 EMR step을 추가하며 다음을 수행한다.
1) 데이터 레이크의 원시 영역 s3에서 클러스터 HDFS로 데이터를 복사한다.
2) 리뷰 분류 스크립트를 실행한다.
3) 클러스터 HDFS에서 DataLake의 s3로 데이터를 복사한다.
wait_for_movie_classification_transformation = EmrStepSensor(
dag=dag,
task_id="wait_for_movie_classification_transformation",
job_flow_id=EMR_ID,
step_id='{{ task_instance.xcom_pull("start_emr_movie_classification_script", key="return_value")['
+ str(last_step)
+ "] }}",
depends_on_past=True,
)- EMR_STEP의 마지막 단계가 완료, 중지, 스킵되었는지 모니터링 한다.
generate_user_behavior_metric = PostgresOperator(
dag=dag,
task_id="generate_user_behavior_metric",
sql="scripts/sql/generate_user_behavior_metric.sql",
postgres_conn_id="redshift",
)DELETE FROM public.user_behavior_metric
WHERE insert_date = '{{ ds }}';
INSERT INTO public.user_behavior_metric (
customerid,
amount_spent,
review_score,
review_count,
insert_date
)
SELECT ups.customerid,
CAST(
SUM(ups.Quantity * ups.UnitPrice) AS DECIMAL(18, 5)
) AS amount_spent,
SUM(mrcs.positive_review) AS review_score,
count(mrcs.cid) AS review_count,
'{{ ds }}'
FROM spectrum.user_purchase_staging ups
JOIN (
SELECT cid,
CASE
WHEN positive_review IS True THEN 1
ELSE 0
END AS positive_review
FROM spectrum.classified_movie_review
WHERE insert_date = '{{ ds }}'
) mrcs ON ups.customerid = mrcs.cid
WHERE ups.insert_date = '{{ ds }}'
GROUP BY ups.customerid;- spectrum의 user_purchase, classfied_movie 데이터를 redshift SQL 스크립트를 이용해서 redshift의 user_behavior_metric 테이블에 저장한다.
결과확인
export REDSHIFT_HOST=$(aws redshift describe-clusters --cluster-identifier sde-batch-de-project --query 'Clusters[0].Endpoint.Address' --output text)
psql postgres://sde_user:sdeP0ssword0987@$REDSHIFT_HOST:5439/devselect insert_date, count(*) as cnt from spectrum.classified_movie_review group by insert_date order by cnt desc; -- 100,000 per day
select insert_date, count(*) as cnt from spectrum.user_purchase_staging group by insert_date order by cnt desc; -- 541,908 per day
select insert_date, count(*) as cnt from public.user_behavior_metric group by insert_date order by cnt desc; -- 908 per day
\qReference

2023