Parquet(파케이)
- Apache Parquet은 오픈소스로 효율적인 데이터 저장 및 검색을 위해 설계된 열 지향 데이터 파일 형식이다. 대량의 데이터를 처리하기 위해 향상된 성능과 효율적인 데이터 압축이 가능하다. Hadoop에서 사용 가능한 다른 열 저장 파일 형식 RCFile, ORC와 유사하다.
Parquet의 장점
- 모든 종류의 데이터(구조화된 데이터 테이블, 이미지, 비디오, 문서)를 저장하는 데 적합하다.
- 매우 효율적인 열 단위 압축과 인코딩 체계를 사용하여 클라우드 저장 공간을 절약할 수 있다.
- 특정 열만 읽을 수 있어서 IO를 크게 최소화 했다.
Parquet Vs CSV
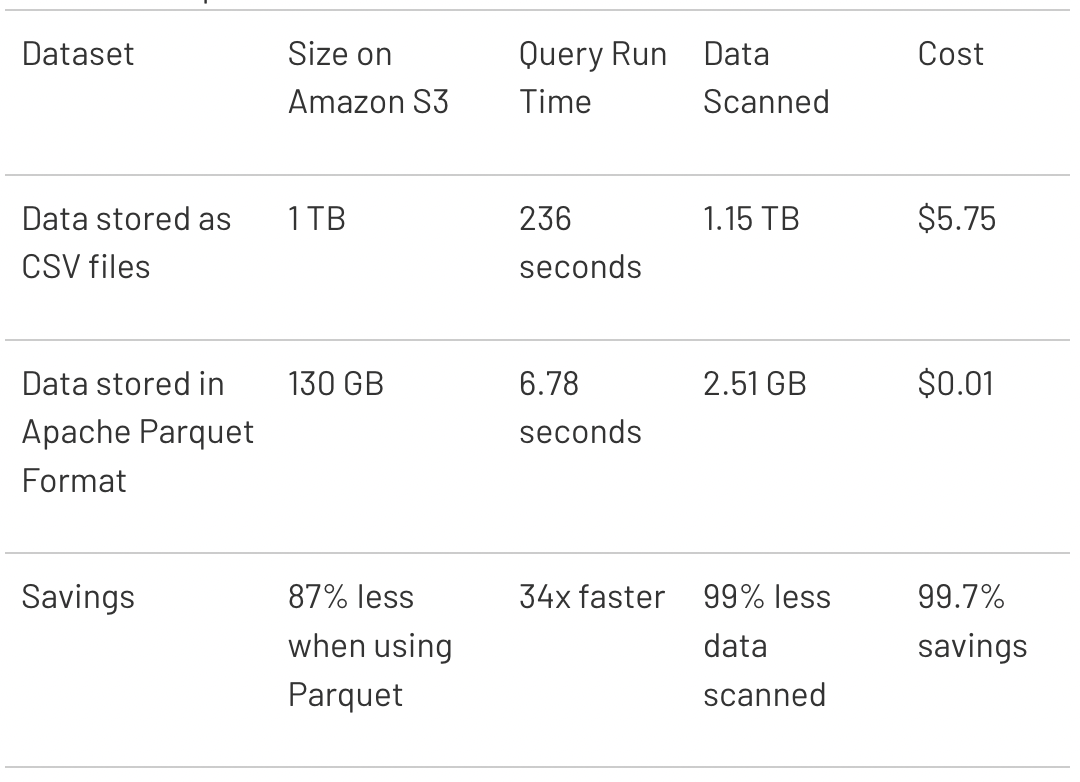
- databricks의 Parquet와 CSV파일을 쿼리 시간과 비용면에서 비교한 결과이다. Amazon S3에서는 저장된 데이터 양에 따라 요금을 청구하고 Amazon Athena 또는 Spectrum은 쿼리당 스캔된 데이터의 양을 기준으로 요금을 청구한다. 위의 그림은 파일 형식의 따라 무려 비용을 99%나 절감 할 수 있다는 것을 보여준다.
Test
- parquet을 생성할 수 있는 다양한 방법이 있지만 Pandas를 통해 확인을 해 보았다. 파일은 faker 모듈을 통해 가짜 데이터를 생성하였다.
- faker csv data
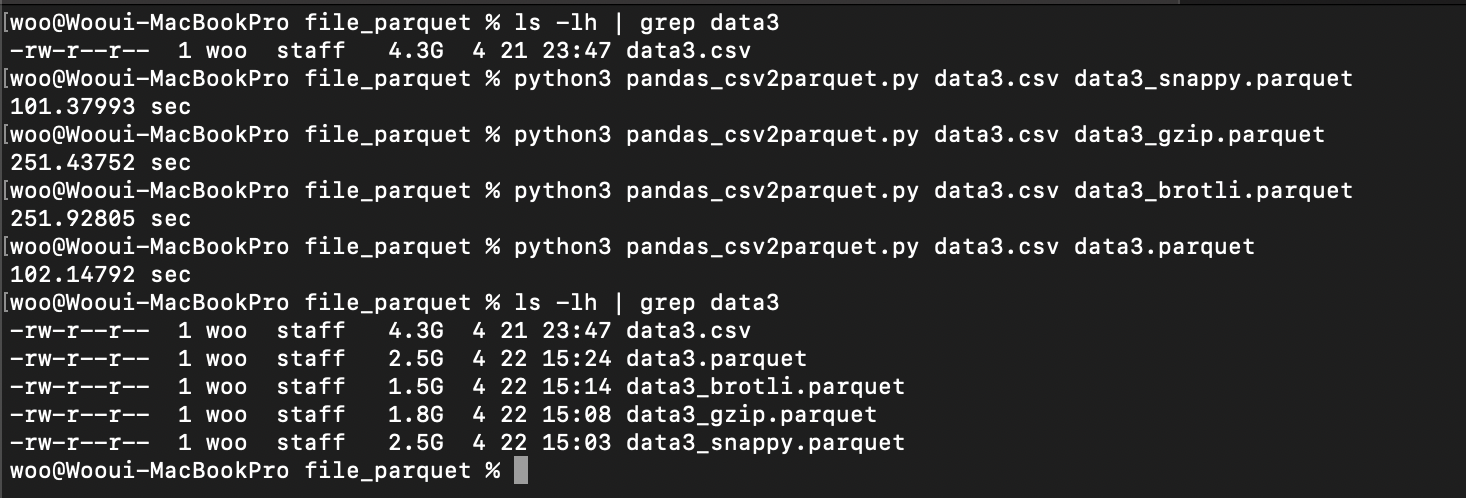
- 파일 압축 방법에 따른 용량과 변환 시간
- 파일 압축 방법에 따른 읽기 시간
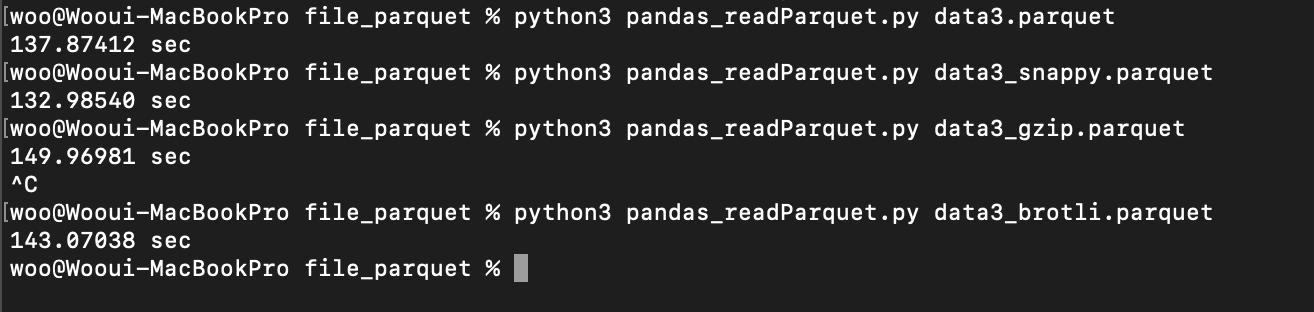
- 압축 방식 없이 parquet 파일을 만들게 되면 약 40%정도 용량이 줄어들어 pandas API 문서를 참고하여 압축 방식을 조정하여 용량을 줄일 수는 있었지만 압축을 하기 때문에 실제 파일 변환시간이 늘어난 효과가 나타난다. 파일마다 시간의 차이가 존재하긴 하지만 용량의 변화만큼 크게 차이는 나지 않는다. 어떠한 한가지 방식을 무조건 따르기 보다는 다양한 방식을 비교해 본뒤 사용하는 습관을 들이는 것이 좋을 것 같다.
Reference

2023