1. Introducing Trino
- Trino는 다양한 Datasource에 SQL을 사용하여 쿼리할 수 있는 분산 SQL 엔진이다.
- data storage system을 포함하지 않아 database가 아니다.
- 분산 쿼리 처리를 위해 메모리 내 병렬 처리, 클러스터 노드 간에 파이프라인 실행, 모든 CPU core를 활용하는 멀티스레드 실행 모델, Java Garbage Collcetion을 최소화하기 위한 효율적인 평면 메모리 데이터 구조, Java 바이트코드 생성 기술을 사용한다.
- 클러스터를 동적으로 확장가능하다.
2. Trino Architecture
Coordinator and Worker in a Cluster
- Trino는 대규모 병렬 처리(Massively Parallel Processing:MPP) 스타일의 데이터베이스와 쿼리 엔진과 유사한 분산 SQL 쿼리 엔진이다.
- 클러스터에 노드를 수평적으로 확장하여 분산처리 할 수 있다.
- 아래의 그림은 coordinator와 여러개의 worker 노드로 구성된 Trino 클러스터의 개요이다.Trino사용자는 Client를 사용하여 coordinator에 연결한다. coordinator는 datasource에 접근하는 worker와 작업한다.
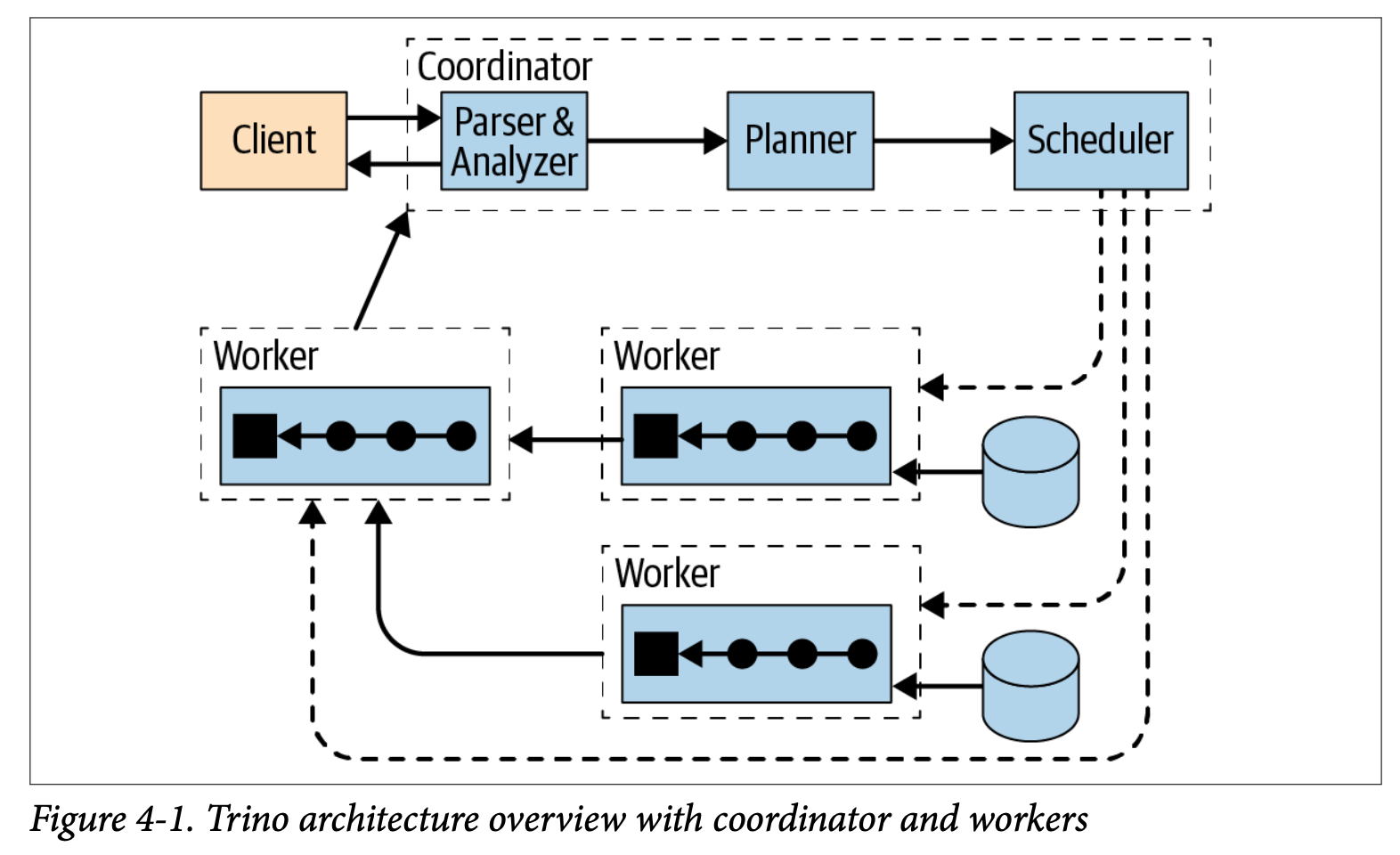
- coordinator는 요청한 쿼리를 처리하고 쿼리를 실행할 worker를 관리한다.
- discovery service는 coordinator에서 실행되고 클러스터에 worker를 등록해준다.
- client, coordinator, worker간의 모든 통신및 데이터 전송은 HTTP/HTTPS를 통한 REST방식을 사용한다.
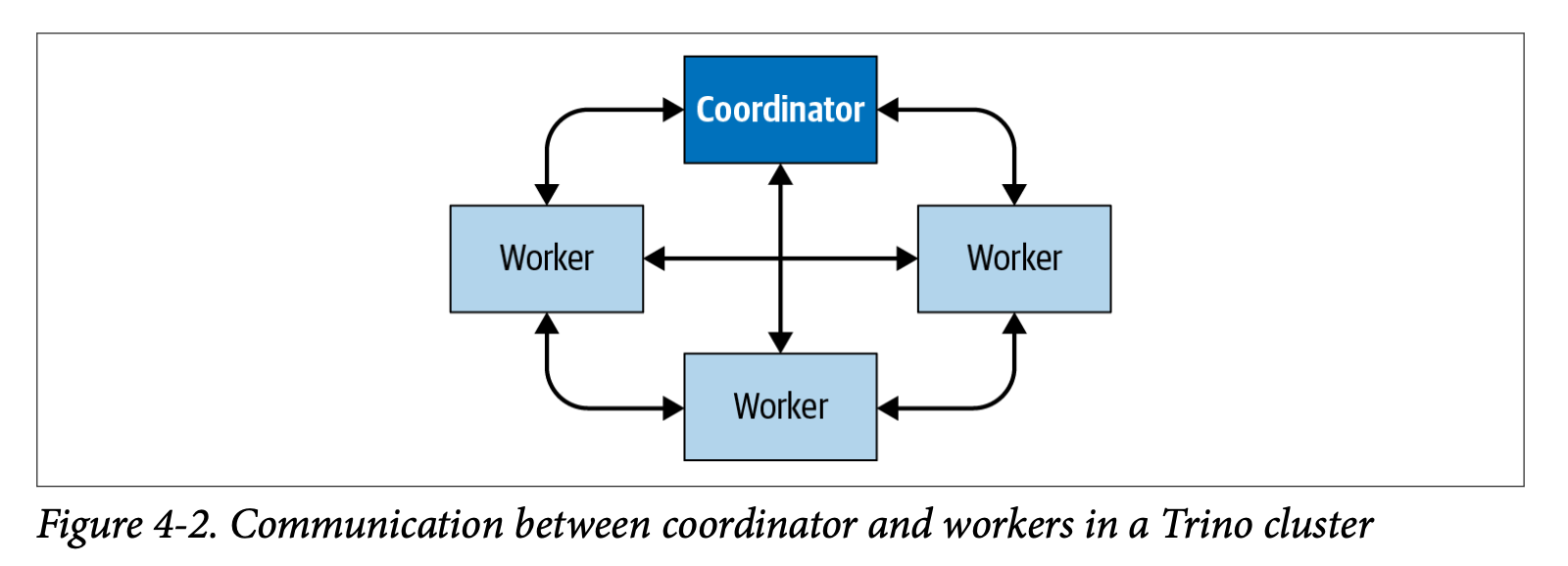
- 아래의 그림은 Cluster내에서 coordinator와 worker간의 통신, 그리고 worker간의 통신방식을 보여준다. coordinator는 worker에게 작업을 할당하고 상태를 업데이트하고 결과를 유저에게 반환한다.
coordinator
- 사용자로부터 SQL문을 받아 구문 분석하고 쿼리를 계획하고 worker 노드를 관리하는 서버이다.
- 각 worker 노드의 활동을 추적하고 쿼리의 실행을 조정한다. 단계를 포함하는 쿼리의 논리적 모델을 생성한다.
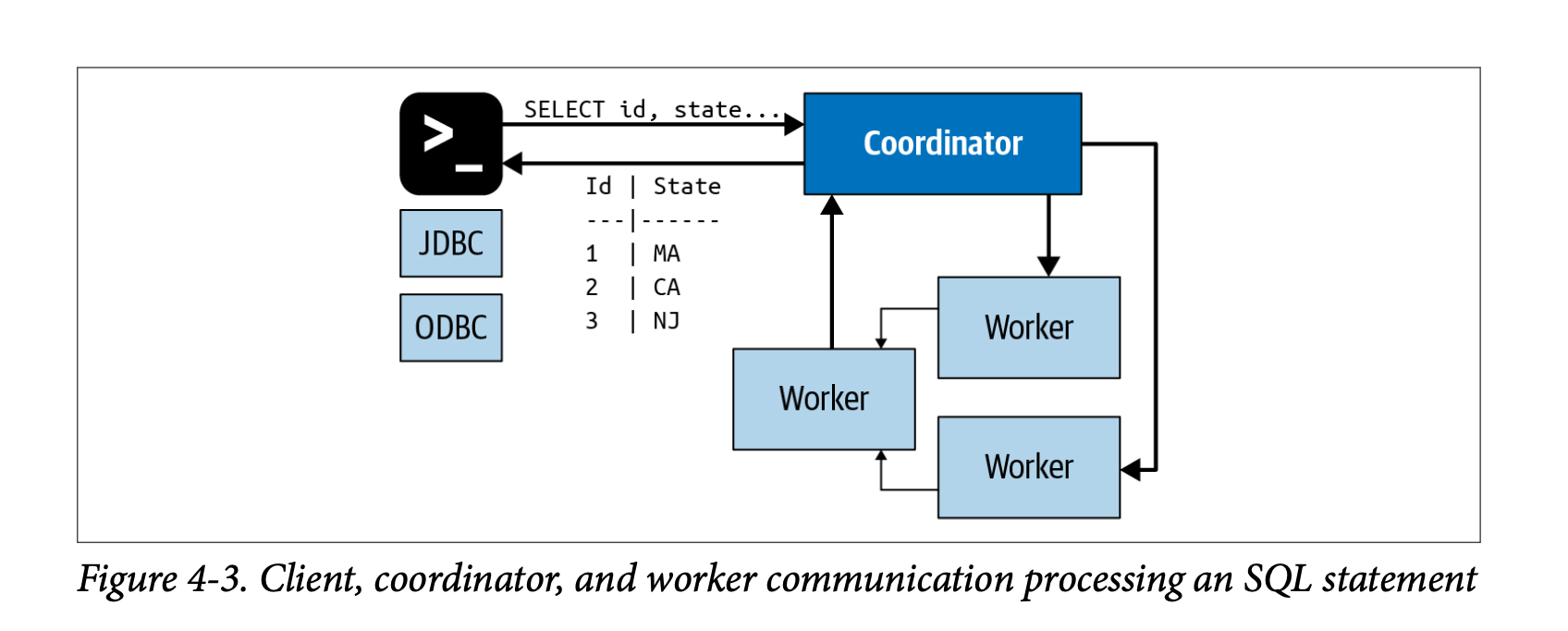
- coordinator가 SQL문은 worker에서 실행되는 일련의 연결된 작업으로 변환됩니다. worker가 데이터를 처리하면 coordinator가 결과를 검색하고 출력 버퍼에서 client에 보여진다. 클라이언트가 출력 버퍼를 완전히 읽으면 coordinator가 client를 대신하여 worker에게 더 많은 데이터를 요청합니다. 그러면 worker는 데이터 원본과 상호 작용하여 데이터를 가져옵니다. 결과적으로 쿼리 실행이 완료될 때까지 client에서 데이터를 계속 요청하고 데이터 소스에서 worker가 데이터를 제공합니다.
Discovery Service
- Cluster내의 모든 노드를 찾기 위해 Discovery Service를 사용한다. instance 시작시에 등록하고 주기적으로 heartbeat signal을 보낸다. 이를 통해 coordinator는 사용 가능한 worker를 관리할 수 있다. 만약 worker가 heartbeat signal을 보고 하지 않으면 failure detector를 worker는 추가 작업을 할 수 없게 된다.
Worker
- worker는 coordinator로부터 할당된 작업을 실행하고 datasource에서 데이터를 검색하고 데이터를 처리하는 역할을 한다.
- worker 노드는 커넥터를 사용하여 datasource에서 데이터를 가져오고 서로 중간 데이터를 교환한다. 최종 결과 데이터는 코디네이터로 전달된다.
- worker가 시작될 때, Discovery Service에 자신을 알리고 coordinator에서 사용할 수 있게 된다.
- worker는 HTTP기반 프로토콜을 사용하여 다른 worker와 coordinator와 통신한다.
Connector-Based Architecture
- Trino의 Storage와 Compute분리 중심에는 Connector-Based Architecture가 있다.
- Connector는 임의의 Datasource에 액세스할 수 있는 인터페이스를 Trino에 제공한다.
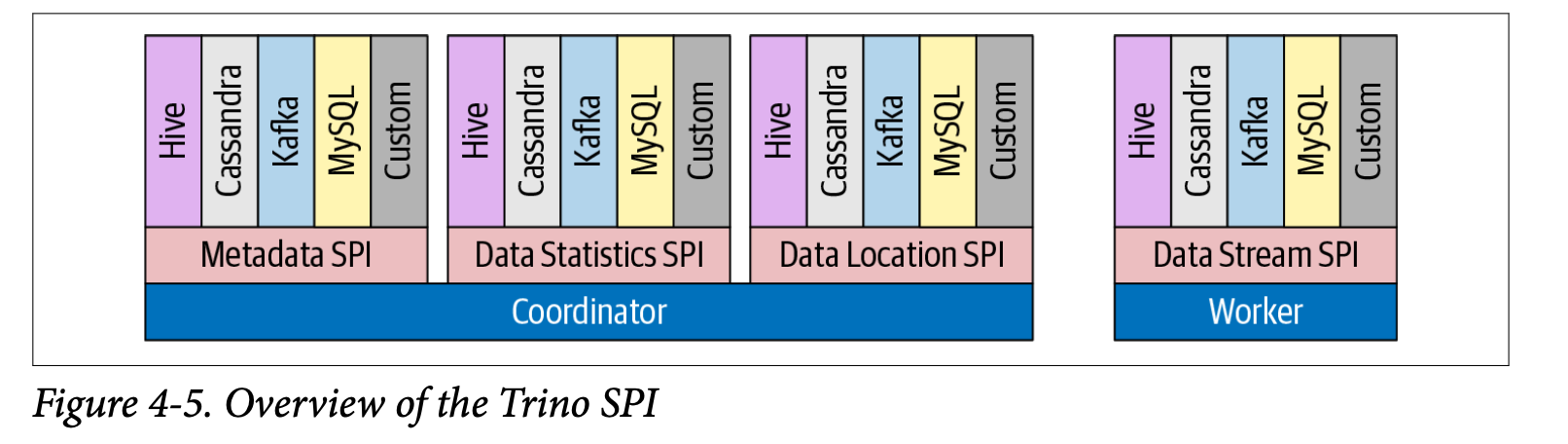
- Trino는 특정 기능에 대해 커넥터가 구현해야 하는 기능을 정의하는 Service Provider Interface(SPI)를 제공합니다.
- 모든 커넥터는 API의 세 부분을 구현해야 한다.
- 테이블/뷰/스키마 메타데이터를 가져오는 작업
- Trino가 읽기 및 쓰기를 병렬화할 수 있도록 데이터 분할의 논리 단위를 생성하는 작업
- 소스 데이터를 쿼리 엔진에서 예상하는 메모리 내 형식으로/에서 변환하는 데이터 소스 및 싱크 - Trino는 이러한 세부사항에 대해선 알 필요가 없다. Connector가 세부사항을 처리한다.
Query Execution Model
- SQL문이 coordinator에 제출되면 해당 SQL문을 구문분석(parse)하고 분석(analyze)한다. Query plan을 사용하여 실행계획을 작성한다.
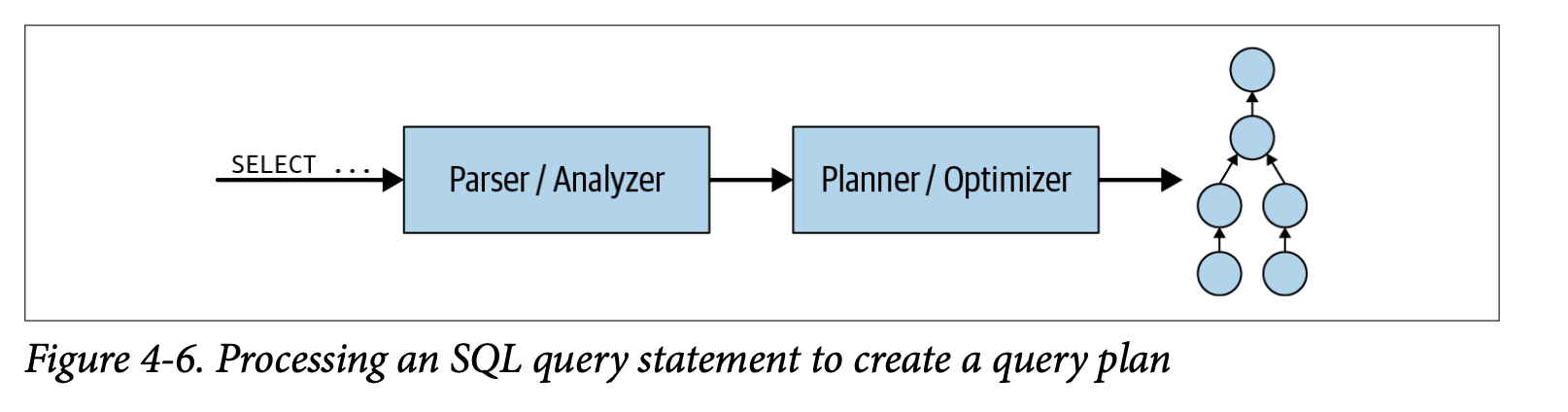
- Coordinator의 Query Plan 생성은 Metadata SPI, Data Statistics SPI를 사용한다.
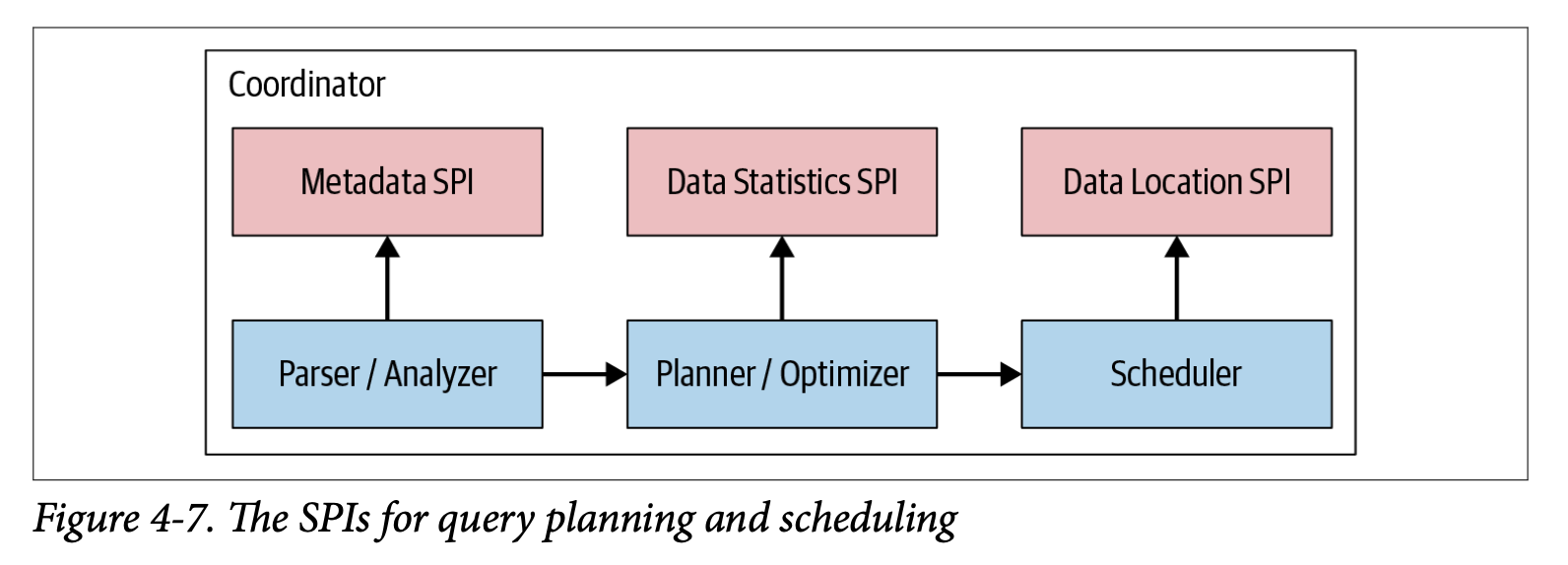
- Metadata SPI를 사용하여 Table, Column, Types에 대한 정보를 가져온다. Query의 의미가 유효한지 검증하고 표현식의 type검사 및 security검사를 수행하는데 사용된다.
- Statistics SPI는 비용 기반 쿼리 최적화를 수행하기 위해 row 수, Table 크기에 대한 정보를 얻는 데 사용된다.
- Data Location SPI는 분산 쿼리 계획 생성에 사용된다. Table 내용의 논리적 분할(split)을 하는데 사용되고 분할(Split)은 작업 할당 및 병렬 처리의 가장 작은 단위이다.
- 분산 쿼리 계획은 하나 이상의 Stage로 구성된 간단한 쿼리 계획의 확장이다. Stage의 수는 쿼리의 복잡성에 따라 달라집니다.
- Queried Tables, returned Columns, JOIN statements, WHERE conditions, GROUP BY operations, and other SQL statements는 생성되는 Stage 수에 영향을 준다.
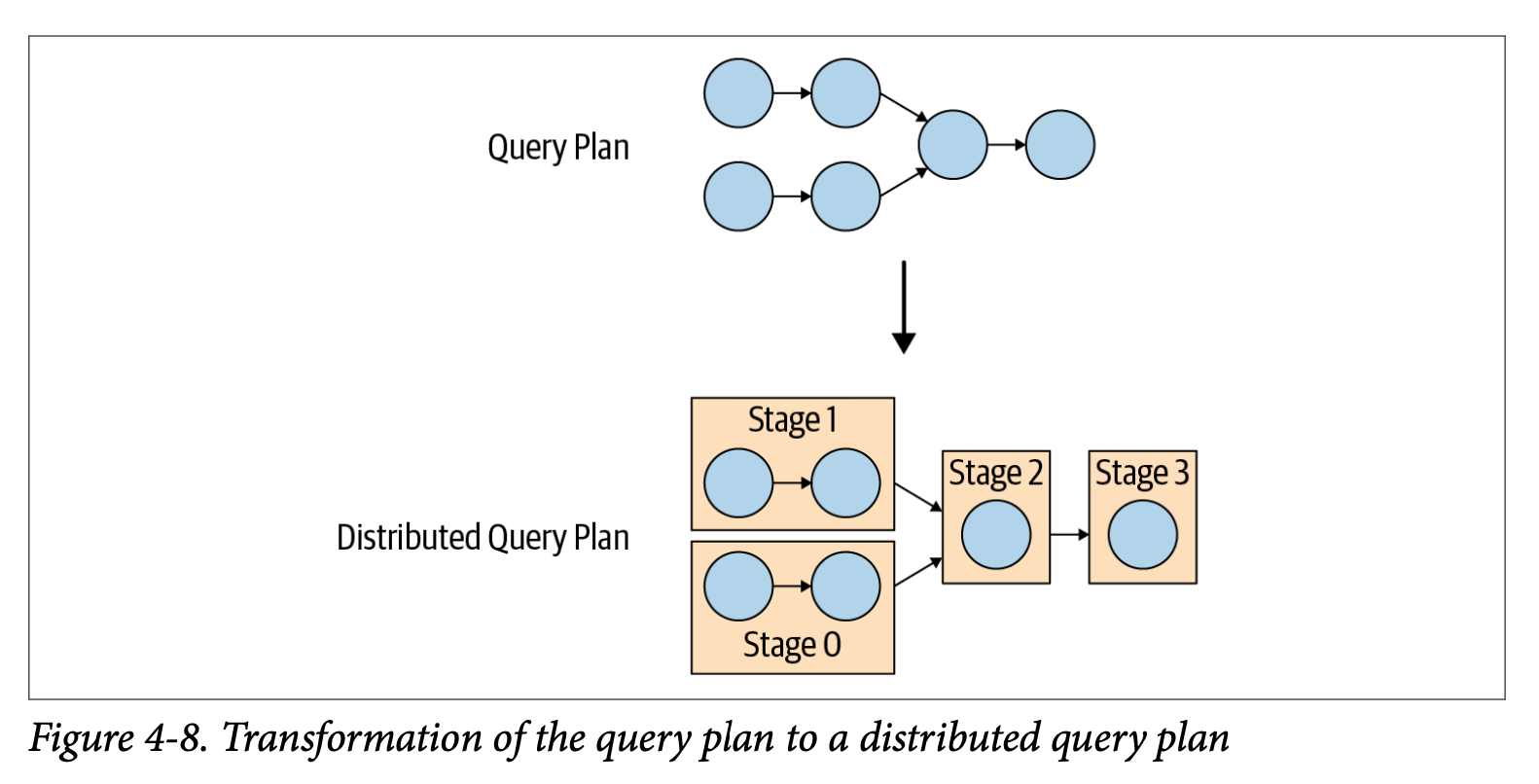
- Stage는 하나 이상의 task로 구성되고 각 task는 데이터의 일부를 처리한다. Coordinator는 Cluster의 Worker로부터 Stage의 작업을 할당한다.
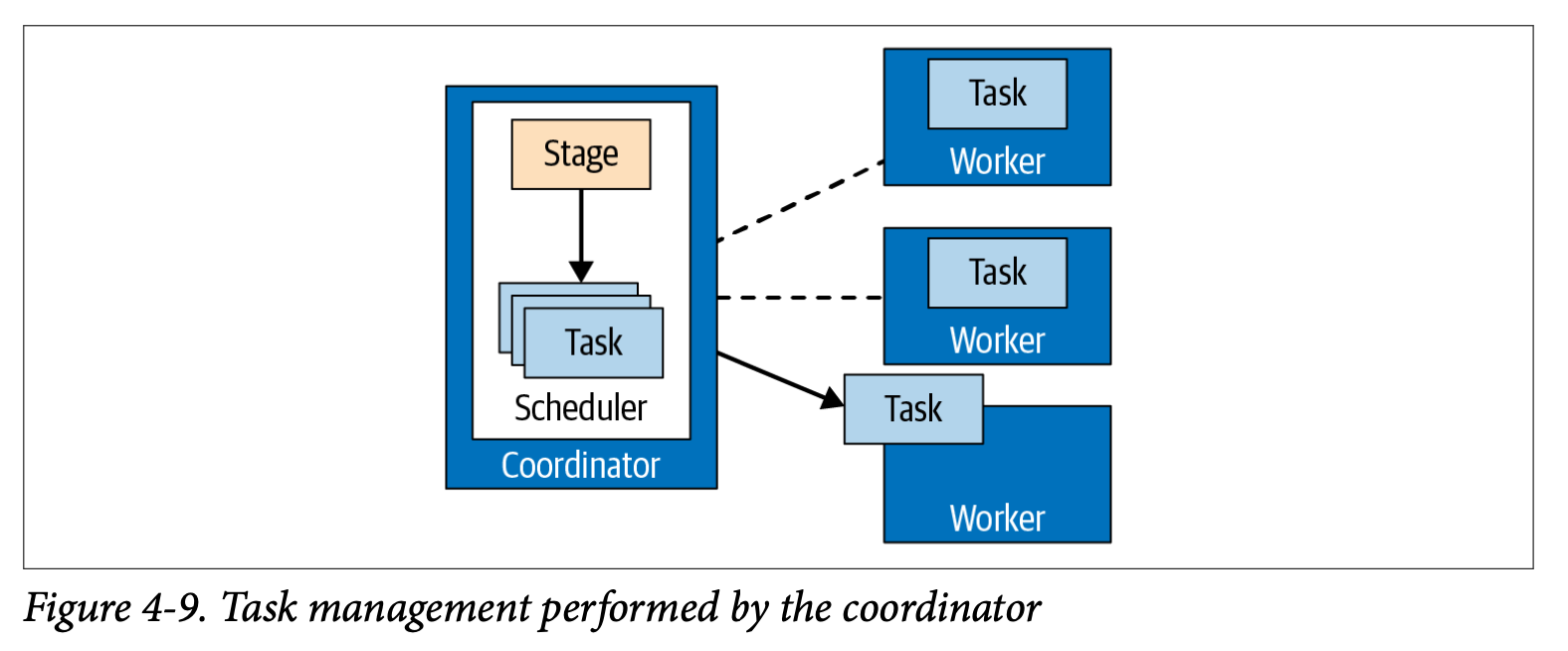
- task가 처리하는 데이터의 단위를 분할(split)이라고 한다. task들은 worker에서 병렬로 수행된다.

- 분할(split)마다 Driver를 인스턴스화 한다. 모든 Driver가 완료되고 데이터가 다음 분할(split)으로 전달된 경우, Driver와 task는 완료되며 파괴된다.

- Coordinator는 Metadata를 사용하여 분할(Split) 목록을 생성하고 분할(Split) 목록을 사용하여 worker에 task를 스케줄링하고 분할(Split)내의 데이터를 수집한다. coordinator는 worker에서 작업들을 추적하고 처리할 분할(Split)이 없을때까지 계속 스케줄링한다. 모든 처리가 완료되면 결과를 Client에 제공한다.
Reference

2023