코테 스터디를 하는 도중 팀원이 왜 Map과 HashMap을 쓰는지 물어보았다.
Map의 구현체 중 하나가 HashMap인 것은 알고 있었지만 정작 이걸 어떤 때에 쓰고, 무슨 차이가 있는지에 대해서는 생각해본 적이 없다는 생각이 들었다.
설명
Map은 Key, Value로 값을 저장하는 자료구조이고, Java Collection의 주요 인터페이스엔 List, Set, Map이 있다.
이 3개의 구분에서 중요한 부분은 순서, 데이터 중복여부가 있다.
- List: 순서O, 데이터 중복O
- Set: 순서X, 데이터 중복X
- Map: <Key, Value>로 저장, Key 중복X, Value 중복O
이 Map의 구현체로는
- HashMap
- TreeMap
- LinkedHashMap
- HashTable
이 있다.
HashMap
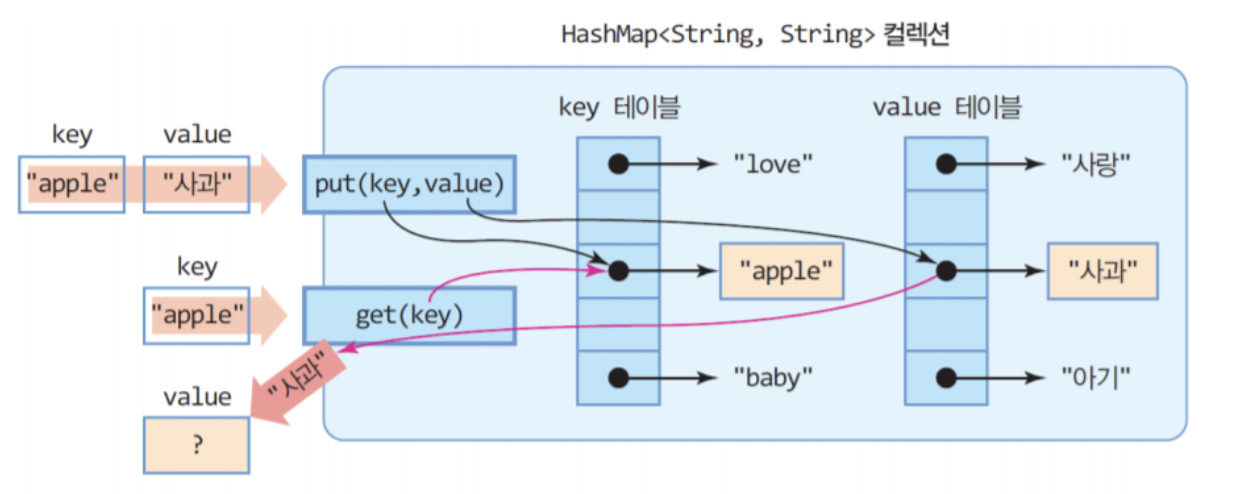
키에 대한 해시 값을 사용하여 저장하고 조회하며 사진과 같이 별도로 key 테이블과 value 테이블에 저장하게 된다.
이를 통해 key를 통해 value를 찾는 부분에서 O(1)의 속도를 보인다.
그리고 사진을 보면 알 수 있듯이 1:1로 매핑되는 형태라고 할 수 있다.
또한, 값이 들어올 시에 List 처럼 저장공간을 추가로 늘리는 동적 형태인데, List와 다르게 저장공간을 2배씩 늘린다.
그래서 map 크기를 지정하지 않았을 때 과부하가 발생할 수 있어 주의해야한다.
결론
탐색, 검색, 추가, 삭제 연산을 평균적으로 O(1)의 시간으로 처리하여 빠른 속도를 보여주고, 내부 구조가 배열과 연결 리스트로 구성되어 있어 메모리 효율적이다.
그러나 너무 많은 데이터 저장이 일어날 때는 메모리 사용량과 속도의 문제가 발생할 수 있다.
대부분의 Map의 인터페이스 구현을 위해서 사용하며, 알고리즘 문제에서 시간이나 속도에 좀 더 신경 써야하는 경우엔 HashMap을 선언하여 사용하면 된다.
참고
다른 map 구현체에 관한 설명은 아래 링크를 참고하면 된다.
https://ch-programmer.tistory.com/71
