[고려대학교] 2021-2 기말시험 대비 자료
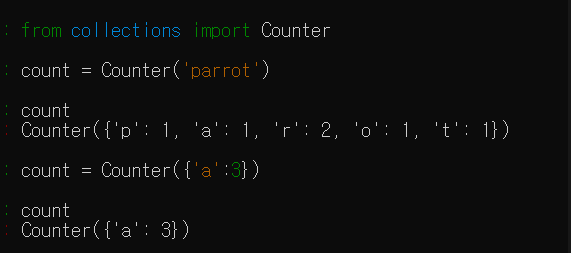
Dictionary
order of items in a dictionary is unpredictable
key immutable type - string, tuple, int, float
value any type
operator in - for keys/using hashtable(same amount of computation time, no matter how many items are in dict)
method
- len(dict) - return the number of keys
- dict.values() - return values in a dict
- dict.keys() - return keys in a dict
- dict.items() - return keys and values in a dict
- dict.get(key, value) - returns the corresponding value of the key if the key appears in the dict, otherwise returns the default value(0)
- sorted(dict) - return the keys in sorted order.*sort()는 사용 불가 immutable
- reversed(dict) - return the iterator of the keys in reversed order. *reverse()는 사용 불가 immutable
- dict.update({key:value} or [(key,value)] or zip(key,value))
🌴 Usage of dictionary
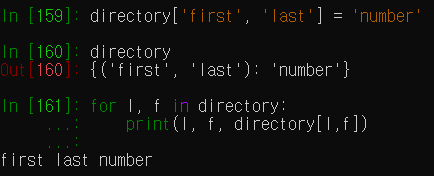
 dictionary의 key로 tuple이 사용되었을 경우
dictionary의 key로 tuple이 사용되었을 경우
🌴 Dictionary 사용 시 주의해야 할 사항
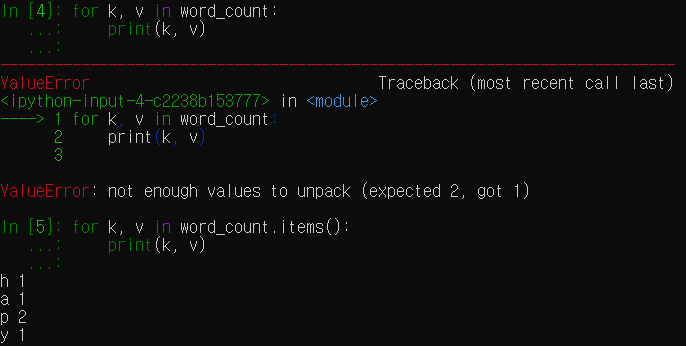
- in operator는 dict의 key에 대해서만 다루어지므로, for k, v in dict와 같이 사용시
Value Error가 발생한다.
dict의 key와 value를 함께 받고싶다면 dict.items() 메소드를 사용하도록 하자. - for statement도 dict의 key에 대해서만 다루어지로 주의하도록 하자.
🌴 Reverse Lookup
dict가 주어졌을 때, 특정한 value값을 가지는 key를 찾아내고 싶다면?
def reverse_lookup(d, v):
for k in d:
if d[k] ==v:
return k
raise LookupError()reverse lookup의 문제점 1. value v와 mapping되는 key가 하나 이상일 수 있음
reverse lookup의 문제점 2. d[k] 처럼 간단한 구문이 존재하지 않음. 위와 같은 코드를 이용해 search해야함.
🌴 Invert Dictionary
dict가 주어졌을 때, key값과 value 값을 뒤집고싶다면?
list를 활용하여 inverse dictionary를 만들 수 있음.
list를 사용하는 이유는, value는 중복될 수 있으므로 같은 value를 가지는 key들이 존재할 수 있기 때문임.
*주의 : value값이 key값으로 바뀌므로, value 역시도 immutable object여야함.

주의할 점: 이 때, list.append() method를 사용했으므로, 초기 value값의 자료형을 []를 통해 list로 만들어준다.
🌴 Fibonacci with dictionary
피보나치 수열에서 아래와 같은 방법은 비효율적이다.
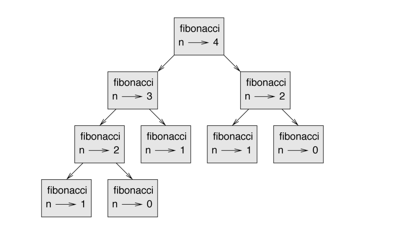
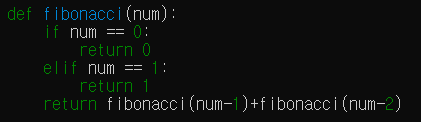
동일한 연산을 다시 수행하는 경우가 많기 때문에, 이를 개선할 방안이 필요하다.
- fibonacci의 memorized version을 이용
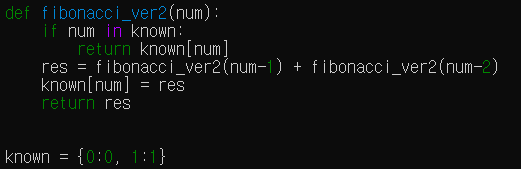
dictionary를 이용하여 fibonacci의 계산 값을 저장하면, 반복적인 연산의 수행 횟수가 줄게 된다.
Global Variable
__main__ 에 있는 variable들은 전역변수로서 어떠한 함수에도 접근이 가능하다. 예를 들어
verbose = True
def example1():
if verbose:
print('Running example1')와 같이 flag처럼 사용할 수도 있다.
만일 global variable을 함수 내에서 reassign하려면, 해당 global variable을 사용하기 전에 global을 사용해 declare 해주어야 한다. 예시는 다음과 같다.
been_called = False
def example2():
global been_called
been_called = True이렇게 하면, 해당 함수 내에서 been_called는 지역변수가 아닌 전역변수로 사용된다.
함수 내에서의 전역 변수의 update도 위와 같은 방법을 이용한다.
- 만일, global variable이 mutable한 value라면 declaring할 필요 없이 global variable을 수정할 수 있다.
Tuple
operator index slicing[:], in, relation operators - 튜플의 첫번째 element부터 차례로 비교한다. 다만, 비교하는 인덱스의 위치끼리 type이 동일해야한다.
method sorted(tuple) - sort()는 사용불가능하다 immutable, reversed(tuple) - reverse()는 사용불가능하다 immutable, enumerate(tuple) - [(index, element)] 형식의 이터레이터를 반환한다.
🌴 Replace Tuple
기본적으로 tupel은 immutavle하다.
만일, tuple의 요소 중 일부를 수정/replace 하고 싶다면 index slicing을 이용하면 된다. 사용 예시는 다음과 같다.
t = ('a', 'b', 'c')
t = ('A',) + t[1:]이때, ('A', )와 같이 작성하는 이유는 ('A')로 작성하게 되면 str tupe으로 인식하기 때문이다. 기본적으로 tuple은 , 로 구분한다.
🌴 Tuple Assignment
두 변수에 대해 swap을 하기 위해서는 일반적으로 다음과 같이 코드를 작성해야한다.
temp = a
a = b
b = temp다만, 파이썬에선 tuple을 이용하면 이 코드가 더욱 간결해진다. 예시는 다음과 같다.
a, b = b,a이러한 방법은 여러 개의 변수에 한 번에 값을 할당할 때도 쓰일 수 있다. 튜플을 이용해 여러 개의 변수에 값을 할당할 때는 등호를 중심으로 좌측 변수의 수와 우측 할당할 값의 수가 동일해야한다.
🌴 Tuples as Return Values
일반적으로 return 을 통해서는 하나의 element만 반환이 가능하다. 다만, tuple을 사용하게 되면 여러 개의 element를 반환하는 효과를 낼 수 있다. 예시는 다음과 같다.
def min_max(t):
return min(t), max(t)위와 같은 경우 min(t)와 max(t)가 하나의 튜플로 묶여져 반환된다. 실제로는 하나의 값을 반환한 것이지만 두 개의 값을 return 하는 효과를 내고 있다.
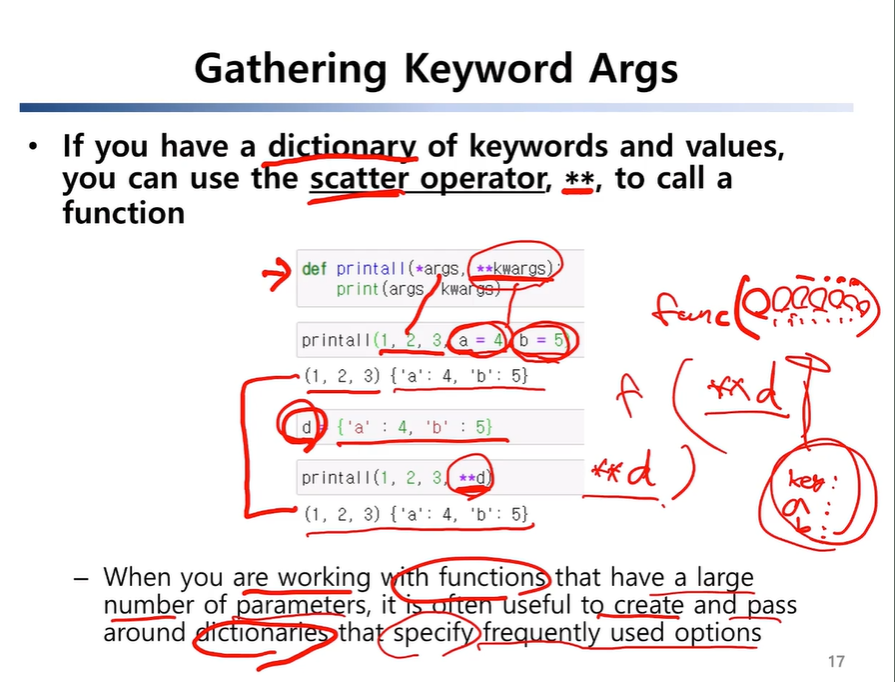
🌴 Variable-Length Argument Tuples
만일 함수를 작성할 때, 입력 argument의 수에 제한을 두고 싶지 않다면 함수의 parameter name 앞에 *을 붙이면 된다.
이는 argument들을 tuple로 모아주는 기능을 한다. 사용 예시는 다음과 같다.
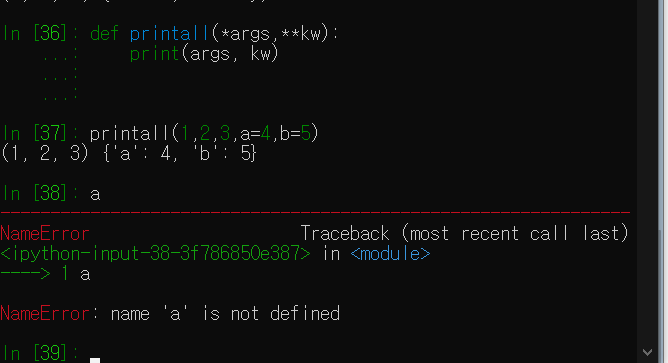
def printall(*args):
print(args)
#입력 값들이 튜플 형태로 출력된다.또한, *는 scatter 역할도 한다. 만일 a 라는 sequence of values가 있고, 이를 multiple arguments를 필요로 하는 함수에 전달해줄 때 유용하게 사용된다. 사용 예시는 다음과 같다.
t = (7,3)
divmod(t)
#TypeError : divmod expected 2 arguments, got 1
divmod(*t)
#(2,1) 출력- max(), min()은 괄호 안에 여러 개의 숫자, 문자가 있어도 무방하지만,
sum()는 괄호 안에 최대 2개의 argument만을 받는다. 이때의 해결 방법은 크게 2가지가 존재한다.
*주의 : max(), min()의 argument type은 통일되어야한다.
- argument 여러개를 받아 tuple로 모아주는
*을 이용한 함수를 작성한다.
def sumall(*args):
return sum(args)- sum함수의 argument들을 tuple로 만들어 전달한다.
sum((1,2,3))🌴 Zip
zip()은 built-in function으로 2개 이상의 argument(str, list, dict-key, set, tuple)를 받아 튜플들의 리스트[(),()]를 이터레이터(iterator) 형식으로 반환한다. 만일 list형식으로 된 zip을 보고 싶다면 list(zip())을 사용하면 된다.
- 각 argument에서 순서대로 element를 받아 하나의 튜플로 묶고, 한 튜플의 길이는 argument들의 수와 같다. 보통 for문에서 자주 사용된다.
- 만일 argument들의 길이가 다르다면 가장 길이가 작은 argument를 기준으로 zip된다.
사용 예시는 다음과 같다.
def has_match(t1, t2):
for x, y in zip(t1,t2):
if x==y:
return True
return False🌴 List and Tuples
list of tuples를 순회하기 위해, for문에서 tuple assignment를 사용할 수 있다. 사용 예시는 다음과 같다.
t = [('a', 1), ('b',2)]
for letter, number in t:
print(number, letter)Files
프로그램의 종료 이후에도 데이터가 유지되도록 하는 방법(persistence)에는 크게 두가지가 존재한다.
1. .txt 파일을 읽고 씀으로써 데이터를 저장할 수 있다.
2. 프로그램의 상태를 database에 저장한다.
🌴 Reading and Writing
파일을 읽거나 쓰기 위해서는 우선 파일을 열어야 한다.
open()을 이용해 파일을 열 수 있으며, 파일을 여는 방법은 다음과 같다.
fout = open('filename.txt', 'w')fout은open()이 return한 '파일 오브젝트(file object)'에 대한 정보를 담고 있다. fout이 아닌 다른 이름으로 설정해주어도 무방하다.
*file object는 현재 파일을 읽고 있는 위치(작업할 위치)를 담고 있다.filename.txt에는 열고자 하는 파일 이름이 들어가며, 현재 direct에 존재하는 파일이어야한다. 그렇지 않은 경우, 경로를 표시해주어야한다.'w'는 파일을 여는 목적(mode)을 뜻한다.'w'는 쓰기 모드를 뜻하며, 해당 자리에 아무 것도 입력하지 않은 경우 기본 모드인 읽기 모드'r'로 파일을 연다.- 만일 읽고자 하는 파일이 이진 파일(binary)이라면
'w'또는'r'뒤에 이진파일임을 뜻하는'b'를 붙여주어야 한다.
ex)wb,rb
파일을 읽어 원하는 작업들을 한 뒤에는 꼭 파일을 닫아주어야한다. .close()를 이용해 파일을 닫을 수 있으며, 닫는 방법은 다음과 같다.
fout.close()파일을 읽고 닫는 작업을 한 번에 할 수 있는 구문도 존재한다.
with open() as fout:를 이용하는 방법이며, 사용 예시는 다음과 같다.
with open('filename.txt', 'w') as fout:
#파일의 open-close 과정에서 작업할 코드들은 여기에 작성앞서 파일을 open할 때 mode를 설정한다고 했었다.
open한 mode별로 쓸 수 있는 method에 차이가 발생한다.
1. w 모드인 경우
: w 모드는 쓰기 모드이며, w mode로 파일을 열면 쓰기에 관련된 작업들만 수행할 수 있다. 해당 모드에서 사용 가능한 메소드는 다음과 같다.
fout.write('str')fout.write()의 argument는str이어야 한다. argument type이str이 아닌 경우str()를 이용해 type을 변경해주어야한다. 또는 format operator%를 이용하는 방법도 존재한다.- write를 이용해 파일에 입력을 할 때는 자동 줄바꿈이 적용되지 않는다. 따라서 줄바꿈이 필요하면 'str'의 끝에 개행 문자
\n를 꼭 써주도록 하자. - 만일
fout.write()을 한 번 사용한 이후에fout.write()를 다시 사용하면, 이전 작업의 마지막부분에 이어서 새로운 데이터를 추가한다.
*fout이 파일 오브젝트로서 매 작업마다 작업 위치를 계속 변경하고 있다는 점에 유의하자.(현재 디렉토리가 계속 업데이트 됨) - w 모드로 작업하고 파일을 close한 후, 다시 같은 파일을 w 모드로 열어 쓰기 작업을 진행하면 이전에 작성되었던 내용은 삭제된다.
- fout.write()의 return 값은 파일에 입력된 문자의 수이다.
\n는 문자 하나로 여긴다.
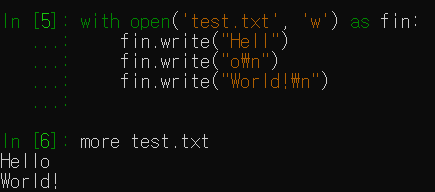
w 모드의 사용 예시는 다음과 같다.
with open('test.txt', 'w') as fin:
fin.write("Hell")
fin.write("o\n")
fin.write("World!\n")test.txt를 확인해보면 다음과 같이 정상 입력되었음을 알 수 있다.
🌴 Filenames and Paths
모든 running program은 current directory가 존재한다.
path는 파일이나 디렉토리를 나타내며, 총 두가지가 존재한다.
-
relative path
: 현재 디렉토리 안에서 고려된 path이다. 'test.txt'와 같이 현제 디렉토리에 의존해 단순히 파일 이름으로만 표기되는 path들이 이에 해당한다. -
absolute path
:/로 시작되는 path들이 이에 해당한다. 현재 디렉토리에 의존하지 않는다.
os module은 파일과 디렉토리에 관련된 함수들을 제공한다.
os.getcwd()
: 현재 디렉토리의 이름, 즉 path를 return한다. cwd는 current working directory의 약자이다.
사용 예시는 다음과 같다.
import os
cwd = os.getcwd()
# cwd == '/home/cham'
#'/home/cham'은 path라고 불리며 파일이나 디렉토리를 나타낸다.os.path.abspath('filename')
: 특정 파일의 absolute path를 알고 싶을 때 사용한다. absolute path를 return한다.
사용 예시는 다음과 같다.
import os
abspath = os.path.abspath('filename')
#abspath == '/home/cham/filename'os.path.exists('filename')
: 어떤 file이나 directory가 존재하는지 확인한다. return 값은True혹은False의 bool값이다.
사용 예시는 다음과 같다.
import os
B = os.path.exists('filename')
# B는 True 혹은 Falseos.path.isdir('str')
: 'str'이 directory인지 판단한다. return 값은True혹은False의 bool값이다.
사용 예시는 다음과 같다.
import os
B = os.path.isdir('filename.txt')
# B == False
B = os.path.isdir('/home/cham')
# B == Trueos.path.isfile('str')
: 'str'이 file인지 판단한다. return 값은True혹은False의 bool값이다.
사용 예시는 다음과 같다.
import os
B = os.path.isfile('filename.txt')
# B == True
B = os.path.isfile('/home/cham')
# B == Falseos.listdir('cwd')
: 'cwd' 디렉토리에 있는 파일들의 리스트를 return 한다.
사용 예시는 다음과 같다.
import os
L = os.listdir('cwd')
#L == ['music', 'photos', 'test.txt']os.path.join('cwd', 'filename')
: directory와 filename을 입력받아 path로 만든다.
사용 예시는 다음과 같다.
#os.walk()와 동일하게 동작하는 함수
#directory에 존재하는 모든 파일들을 출력한다.
import os
def walk(dirname):
for name in os.listdir(dirname):
path = os.path.join(dirname, name)
if os.path.isfile(path):
print(path)
else:
walk(path)🌴 Database

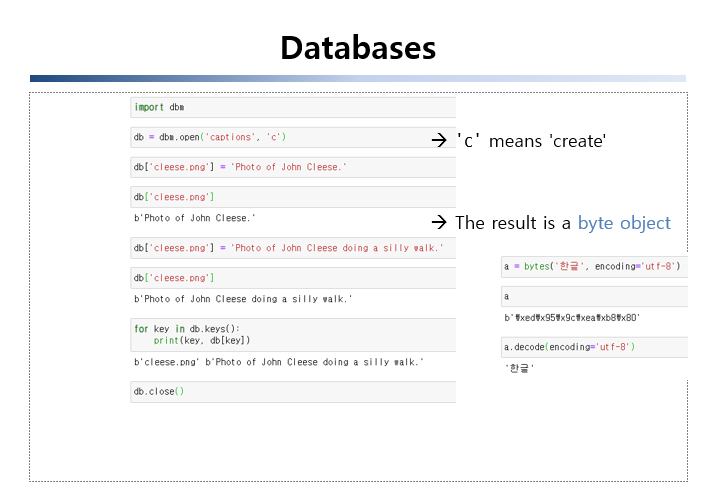
🌴 Pickling


🌴 Pipes

🌴 Writing Modules



Catching Exceptions
코드를 작성하다보면 의도치 않은, 코드 작성자가 미처 인식하지 못한 Exception이 발생할 수 있다. 이 경우, try: except: 구문을 사용하면 exception 문제들을 더 쉽게 다룰 수 있다 (catching an exception).
사용 예시는 다음과 같다.
# try를 실행하다 예외가 발생하면 except 구문으로 건너뛴다.
try:
fin = open('bad_file')
except:
print('Something went wrong.')The Goodies