트리의 기본
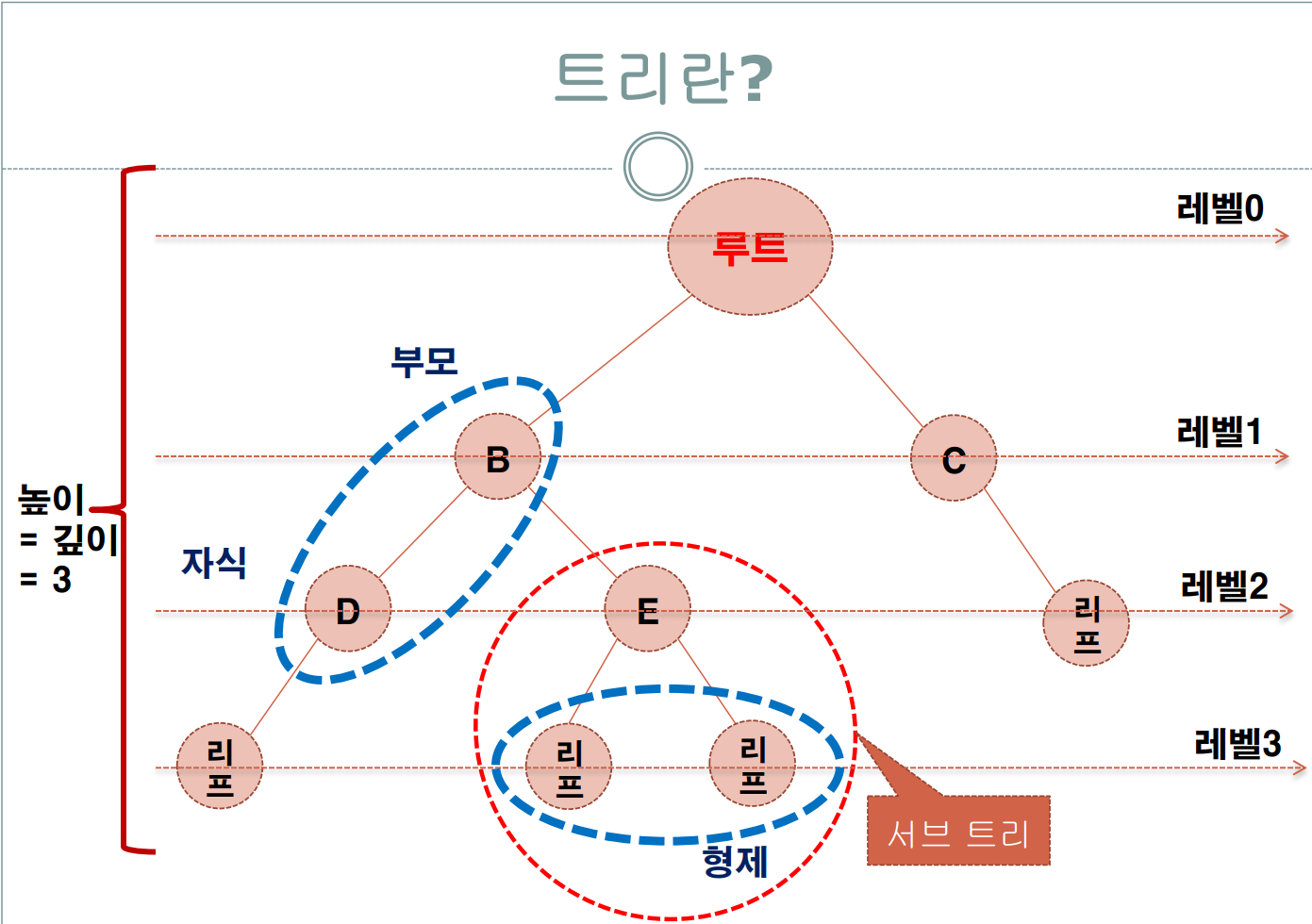
트리(Tree)란?
비선형 자료구조로 계층 관계를 나타내는 데 사용
트리의 용어
• 루트(root) : 트리의 최상위 노드
• 노드(node) : 각 노드는 널(NULL) 값이나 자식을 가리키는 두 개의 포인터와 데이터를 가짐.
• 간선(edge) : 두 노드를 연결하는 데 사용
• 리프(leaf) : 자식이 없는 노드
• 자식(children) : 한 노드로부터 가지로 연결 된 아래쪽 노드
• 부모(parent) : 한 노드에서 가지로 연결 된 위쪽 노드
• 형제(sibling) : 같은 부모를 가지는 노드
• 높이/깊이(height / depth) : 루트부터 리프까지 가장 긴 경로의 간선수
• 레벨(level) : 루트에서 노드까지의 경로에 있는 간선 수. 루트의 레벨이 0이며, 가지가 하나씩 아래로 뻗어 나갈 때 마다 레벨이 1씩 늘어남.
• 차수(degree) : 노드가 갖는 자식의 수
• 서브트리(subtree) : 트리 안에서 다시 어떤 노드를 루트로 정하고 그 자손으로 이루어진 트리
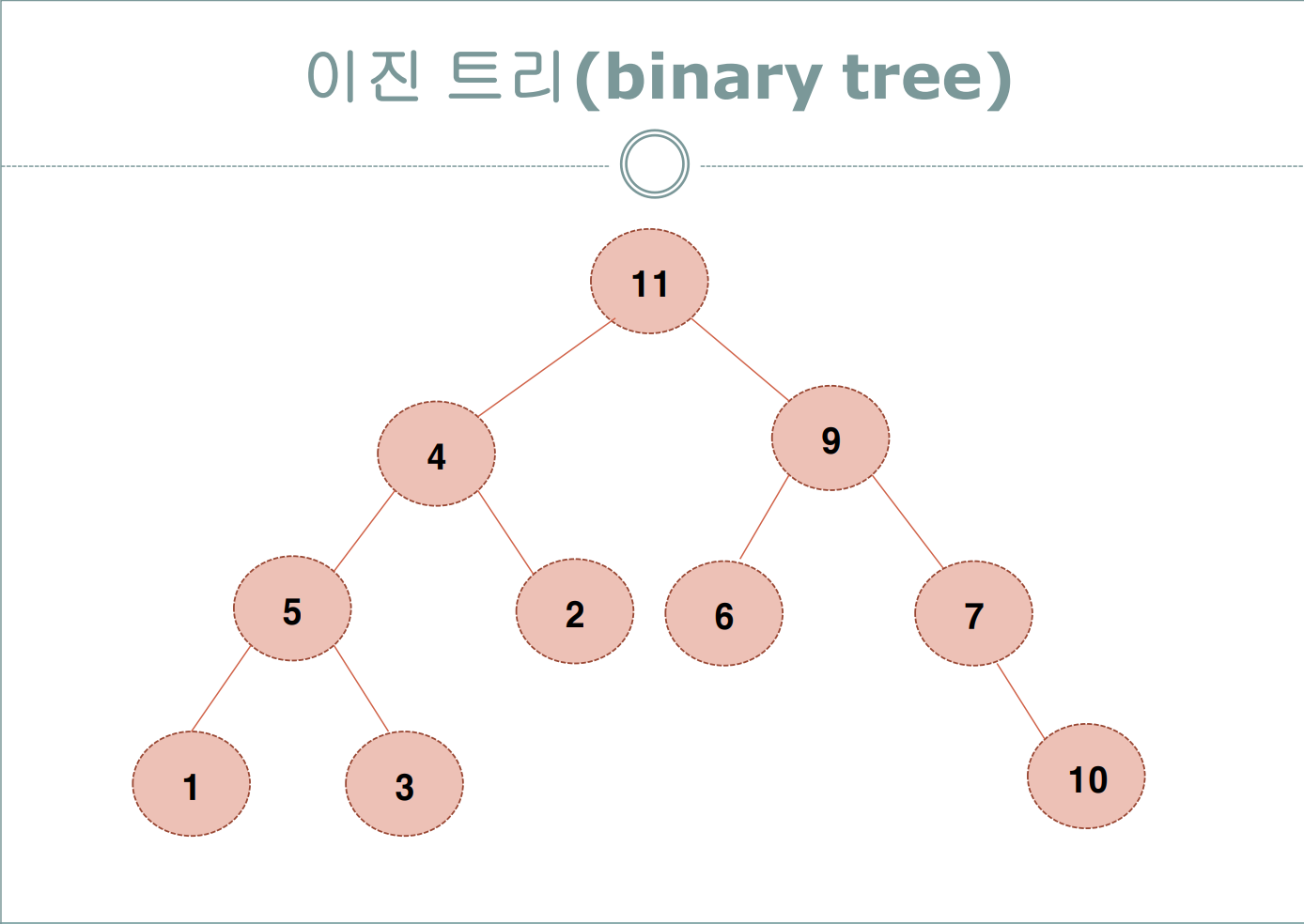
이진 트리
• 노드가 왼쪽 자식과 오른쪽 자식을 갖는 트리
• 각 노드의 자식은 2명 이하로 유지해야 함.
• 이진트리는 왼쪽 자식과 오른쪽 자식을 구분함.
• 이진트리는 순서가 정의되어 있지 않으므로 순서 없이 삽입 시 편향 이진 트리가 될 수 있다.(비효율적) -> 완전 이진 트리로 해결
• i >= 1일때, 레벨i에서 최대 노드수는 2i이다.
• k >= 1일때, 높이가 k인 노드의 최댓값은 2k+1 – 1 이다.
• N개의 노드를 가진 트리는 노드를 연결하는 간선이 n-1개 이다.
• n개의 노드를 저장할 수 있는 완전이진트리의 높이는 log2n 이다.
• 이진트리의 유형으로는 완전 이진 트리(complete binary tree), 정 이진 트리(full Binary tree), 포화 이진 트리(perfect binary tree) 등이 있다.
이진 트리 구조
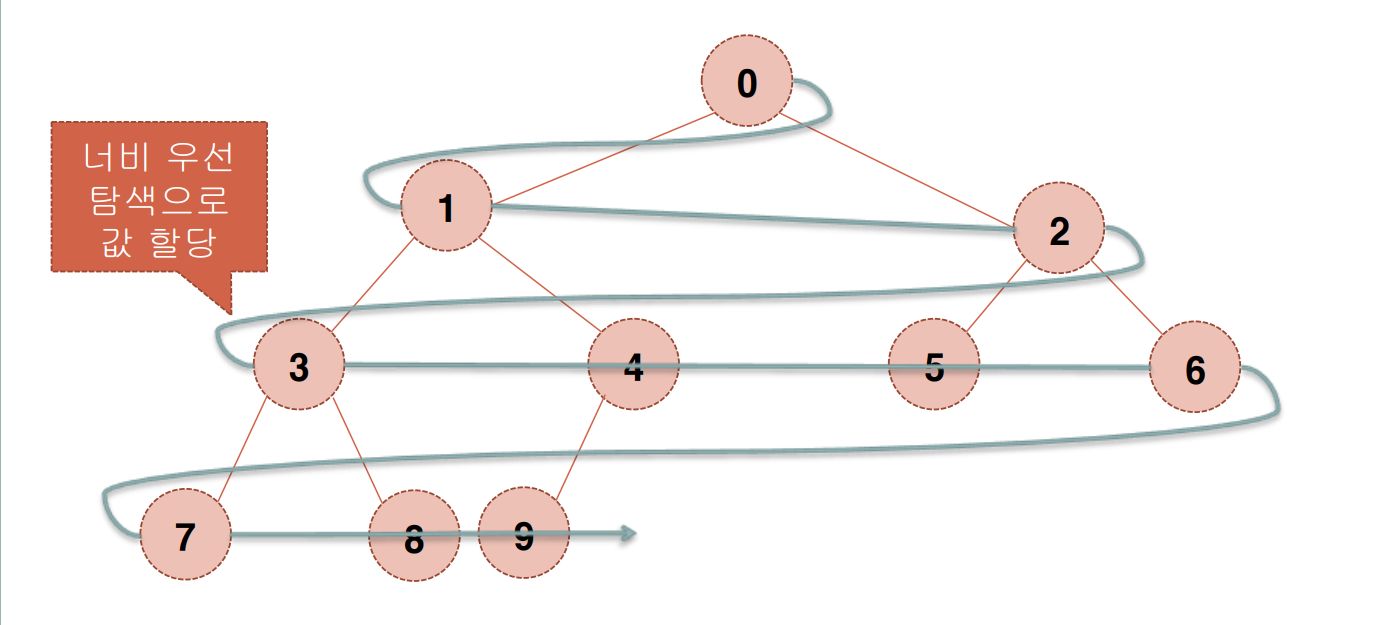
완전 이진 트리 (Complete Binary Tree)
- 마지막 레벨을 제외한 모든 레벨은 노드로 가득 차야함.
- 마지막 레벨은 왼쪽부터 오른쪽 방향으로 노드를 채워야 함.
완전 이진 트리 순회
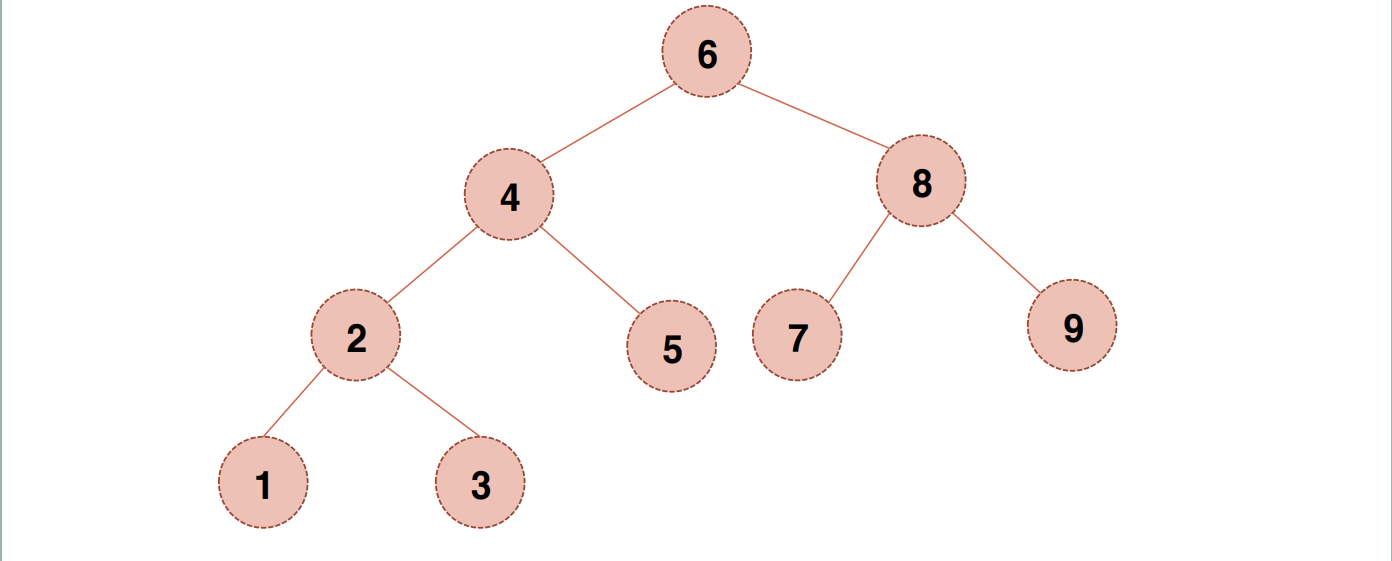
중위순회(In-order) : 왼쪽 -> 부모-> 오른쪽 : 1-2-3-4-5-6-7-8-9
전위순회(pre-order) : 부모-> 왼쪽 -> 오른쪽 : 6-4-2-1-3-5-8-7-9
후위순회(post-order) : 왼쪽 -> 오른쪽 -> 부모 : 1-3-2-5-4-7-9-8-6
트리 구조 구현
typedef struct tree
{
int value; // Data 값을 저장
struct tree* left; // 왼쪽 주소를 저장
struct tree* right; // 오른쪽 주소를 저장
}tree; // 트리 구조체 이름 정의
void display(tree* t) // tree 자료형을 갖는 t를 인자값으로 한 함수
{
if(t) // t가 NULL이 아니면
{
display(t->left); // 왼쪽 주소값을 가지고 재귀호출
printf("%d ", t->value);
display(t->right);
// 출력하는 구문이 가운데 있으면 "중위순회"
// 위에 있으면 "전위순회"
// 아래의 있으면 "후위순회"
}
}정 이진 트리 (Full Binary Tree)
- 각 노드가 모두 0개 또는 2개의 자식이 있어야 한다.
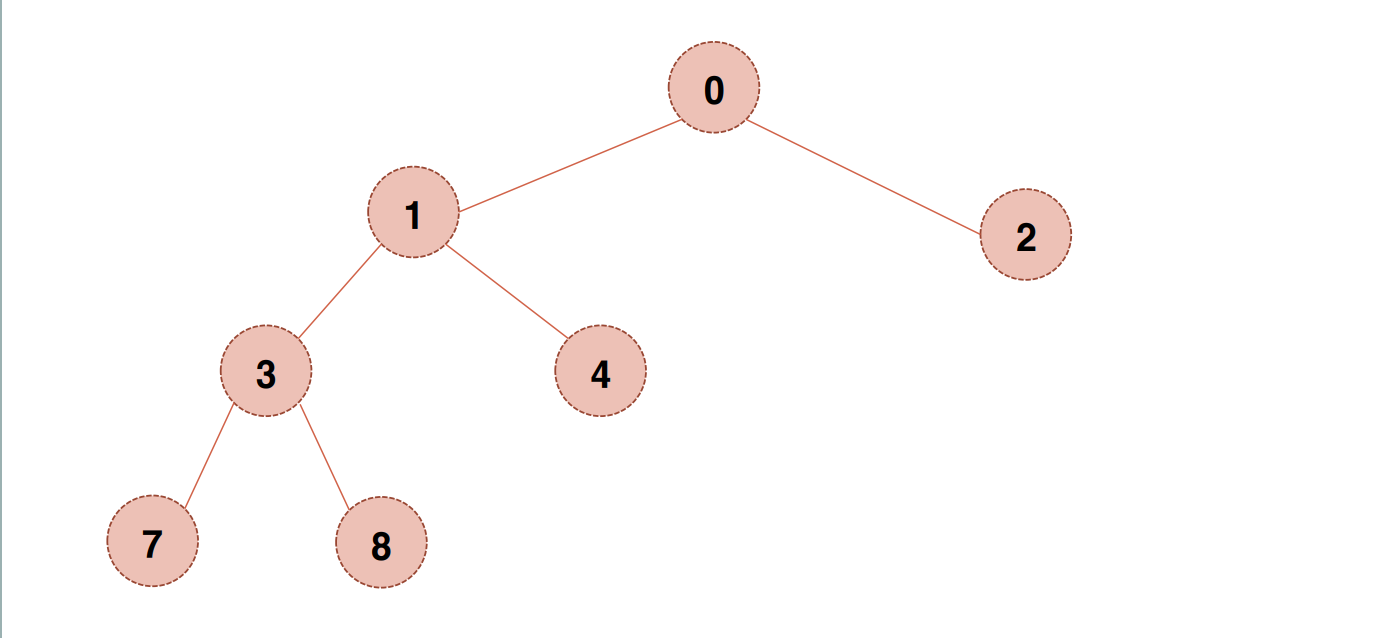
포화 이진 트리 (Perfect Binary Tree)
- Leaf 노드를 제외한 모든 노드가 정확히 2개의 자식 노드를 갖는다.
- 모든 Leaf는 레벨이 갖고, 모든 노드가 채워져야 함.
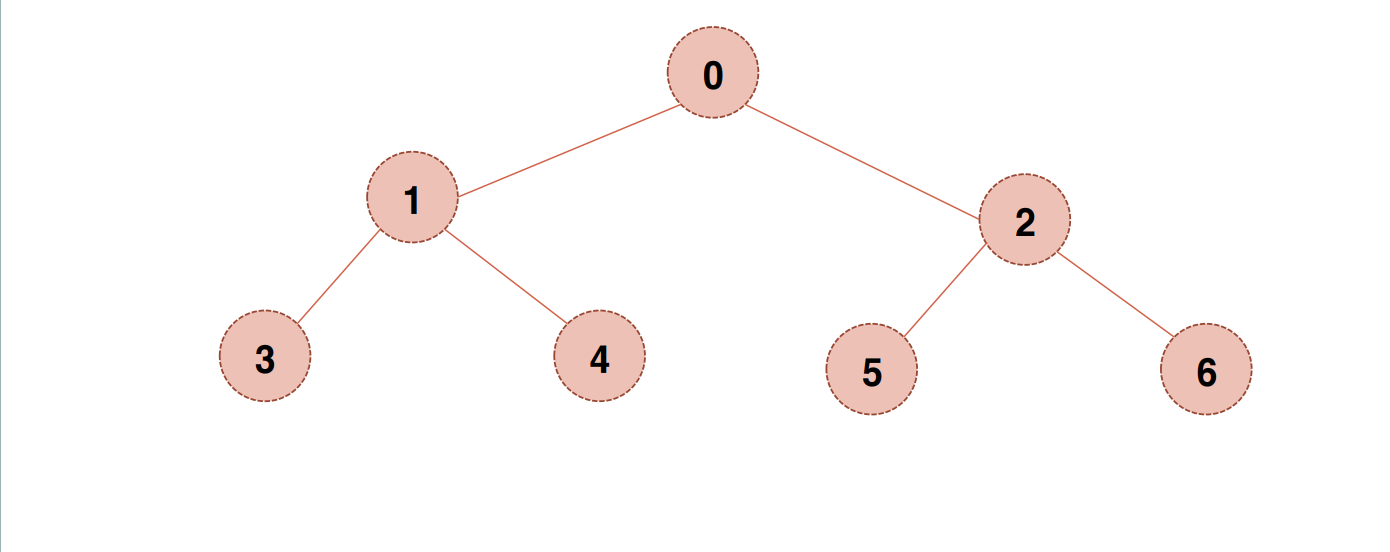
이진 검색 트리 (Binary Search Tree)
• 노드N을 기준으로 왼쪽 서브 트리 노드의 모든 값은 노드 N의 값보다 작아야 한다.
• 오른쪽 서브 트리 노드의 값은 노드 N의 값보다 커야 한다.
• 같은 값을 갖는 노드는 없다.
• 이진 검색 트리는 중위 순회를 하면 오름차순으로 노드를 얻을 수 있다.
• 구조가 단순하다.
• 이진 검색과 비슷한 방식으로 검색이 가능하다.
• 노드의 삽입이 쉽다.
BST 노드 삽입
- BST는 부모보다 값이 작으면 왼쪽, 크면 오른쪽에 위치하는 특성을 이용
- 왼쪽 혹은 오른쪽 주소의 값이 없으면 동적할당으로 메모리 생성 후 데이터 삽입
typedef struct tree
{
int value;
struct tree* left;
struct tree* right;
}
tree* AddNode(tree* t, int data) // 삽입할 노드의 자료형을 tree로 반환
{
if (!t) { // t가 NULL이 아니라면
t = new tree {data}; // 메모리를 동적할당해서 값을 data로 초기화
// t = new tree();
// t->value = data; // 이렇게 써도 됨
t->left = nullptr;
t->right = nullptr;
}
else if (data < t->value) {
t->left = AddNode(t->left, data)
}
else if (data > t->value) {
t->right = AddNode(t->right, data)
}
return t;
}BST 최댓값, 최솟값 노드 찾기
-
부모를 중심으로 왼쪽은 부모보다 작은 값, 오른쪽은 큰 값이기 때문에,
가장 왼쪽에 위치한 Leaf 노드가 최솟값이 되고,
가장 오른쪽에 위치한 Leaf 노드가 최댓값이 된다. -
재귀호출을 사용해도 되지만 코드를 이해하기 어렵기 때문에 피할 수 있으면 피하는게 좋다.
-
최솟값은 재귀호출을 사용하고, 최댓값은 반복문을 사용해서 구현해보자.
// tree 구조체
(생략)
// 최댓값(반복문)
tree* FindMax(tree* t) {
if (t) {
while (t->right)
t = t->right;
}
return t;
}
// 최솟값(재귀호출)
tree* FindMin(tree* t) {
// left가 Null이면 t를 리턴
if (t->left) {
t = FindMin(t->left); // 아랫단계에서 return된 t의 값을 현재 t에 대입
}
return t;
}BST 노드 삭제
3가지 경우가 있다.
- 자식 노드가 없는 경우
-> 노드를 삭제 후 부모에게 Null을 넘겨준다. - 자식 노드가 1개 있는 경우
-> 임시변수에 자식 노드의 주소를 저장 후 노드를 삭제하고, 그 노드의 부모에게 자식 노드의 주소를 넘겨준다. (내가 죽을 때 내 자식을 내 부모에게 맞기고 떠남) - 자식 노드가 2개 있는 경우
-> 왼쪽 서브 트리의 최댓값을 구해서 현재 노드에 대입 후 최댓값을 삭제한다.
삭제 순서
1. 삭제하려는 노드가 어디에 있는지 부터 검색
2. 찾았으면 위에 3가지 경우에 따라 삭제
// tree 구조체
(생략)
tree* Remove(tree* t, int delData)
{
tree* temp;
if (t) {
if (delData == t->value) {
// 삭제
if (t->left == nullptr && t->right == nullptr) { // 1. 자식이 둘 다 없는 경우
delete t; // 삭제 후
return nullptr; // 호출한 곳으로 null 값을 반환
}
else { // 2. 자식이 하나 있는 경우
if (t->right == nullptr) { // 왼쪽 자식만 있는 경우
temp = t->left;
delete t;
return temp; // 호출한 곳으로 temp 값(왼쪽 자식)을 반환
}
if (t->left == nullptr) { // 오른쪽 자식만 있는 경우
temp = t->right;
delete t;
return temp; // 호출한 곳으로 temp 값(오른쪽 자식)을 반환
}
// 3. 자식이 둘 다 있는 경우
temp = FindMax(t->left); // 위에서 만든 최댓값 찾는 함수를 사용해 임시변수에 저장
t->value = temp->value;
t->left = Remove(t->left, temp->value);
// 최댓값 노드가 왼쪽 자식을 갖고 있을 수 있기 때문에 재귀호출로 삭제
}
}
else {
if (delData < t->value)
t->left = Remove(t->left, delData);
else
t->right = Remove(t->right, delData);
}
}
return t;
}트리 순회 방식을 활용해 원본트리 구현
개념
-
단일 순회 방식만으로는 트리를 복원할 수 없다.
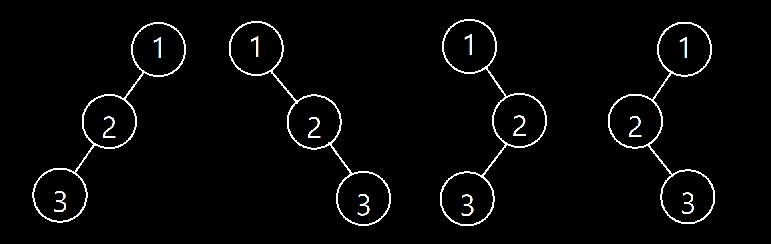
예시)
전위순회 : 1-2-3 (모든 그림 해당)
후위순위 : 3-2-1 (모든 그림 해당) -
중위 순회 방식이 없으면 트리를 복원할 수 없다.
중위순회 : 2-1-3
루트가 1이라면 1을 기준으로 왼쪽에 있는 수들은 왼쪽 자식이고, 오른쪽이 있는 수들은 오른쪽 자식이 된다.
이 개념을 바탕으로 전위 or 후위 + 중위 순회 방식으로 원본 트리를 복원할 수 있다.
전위: 1-2-3
중위: 1-2-3전위: 1-2-3
중위: 3-2-1전위: 1-2-3
중위: 1-3-2후위: 3-2-1
중위: 1-3-2후위: 3-2-1
중위: 2-3-1그림을 노트에 그려보자. 여기선 생략..
코드 구현
예를 들어 다음과 같은 순회 결과가 나왔다고 해보자.
전위순회 결과: 1-2-4-5-3-6
중위순회 결과: 4-2-5-1-6-3
#include <iostream>
typedef struct tree {
int value;
struct tree* left;
struct tree* right;
}tree;
// 복원 함수들
// ...
int main() {
tree* root = nullptr;
int preOrder[6] = { 1,2,4,5,3,6 };
int inOrder[6] = { 4,2,5,1,6,3 };
root = tree_restore(preOrder, inOrder, 0, 5);
return 0;
}main 함수에는 위와 같이 전위순회 결과인 preOrder 배열과
중위순회 결과인 inOrder 배열을 선언하고, root에 트리구조를 복원할 것이다.
먼저 tree_restore 함수를 구현해보자.
void tree_restore(int* preOrder, int* inOrder, begin, end) {
static int preIdx = 0; // preOrder를 순서대로 불러오기 위한 인덱스를 선언
tree* newNode = nullptr; // 마지막 리프 노드의 아랫단계 재귀호출에서 newNode를 리턴할 때 NULL 값을 리턴
if (begin <= end) { // 리프 노드의 아랫단계에서는 조건이 맞지 않음
newNode = new tree(); // 동적할당으로 메모리 생성
newNode->value = preOrder[preIdx++];
newNode->left = newNode->right = nullptr;
// 전위순회 순서로 불러온 값으로 중위순회에서의 inIdx를 구함
int inIdx = get_inOrder_idx(inOrder, begin, end, newNode->value);
// inIdx를 기준으로 왼쪽자식과 오른쪽자식을 구분함
newNode->left = tree_restore(preOrder, inOrder, begin, inIdx - 1); // 리턴하면서 부모의 왼쪽 주소에 저장
newNode->right = tree_restore(preOrder, inOrder, inIdx + 1, end); // 리턴하면서 부모의 오른쪽 주소에 저장
}
return newNode;
}전위순회 순서로 불러온 값으로 중위순회의 인덱스를 구하는 함수(get_inOrder_idx)를 구현해보자.
int get_inOrder_idx(int* inOrder, int begin, int end, int target) {
for (int i = begin; i <= end; i++)
if (inOrder[i] == target)
return i;
return -1; // 예외처리 구문. 없으면 "모든 경우에 반환값을 돌려줄 수 없다" 라는 경고메세지가 뜸. 배열의 첨자로 가질 수 없는 -1값을 리턴.
}정리를 하면
#include <iostream>
typedef struct tree {
int value;
struct tree* left;
struct tree* right;
}tree;
int get_inOrder_idx(int* inOrder, int begin, int end, int target) {
for (int i = begin; i <= end; i++)
if (inOrder[i] == target)
return i;
return -1; // 예외처리 구문. 없으면 "모든 경우에 반환값을 돌려줄 수 없다" 라는 경고메세지가 뜸. 배열의 첨자로 가질 수 없는 -1값을 리턴.
}
void tree_restore(int* preOrder, int* inOrder, begin, end) {
static int preIdx = 0; // preOrder를 순서대로 불러오기 위한 인덱스를 선언
tree* newNode = nullptr; // 마지막 리프 노드의 아랫단계 재귀호출에서 newNode를 리턴할 때 NULL 값을 리턴
if (begin <= end) { // 리프 노드의 아랫단계에서는 조건이 맞지 않음
newNode = new tree(); // 동적할당으로 메모리 생성
newNode->value = preOrder[preIdx++];
newNode->left = newNode->right = nullptr;
// 전위순회 순서로 불러온 값으로 중위순회에서의 inIdx를 구함
int inIdx = get_inOrder_idx(inOrder, begin, end, newNode->value);
// inIdx를 기준으로 왼쪽자식과 오른쪽자식을 구분함
newNode->left = tree_restore(preOrder, inOrder, begin, inIdx - 1); // 리턴하면서 부모의 왼쪽 주소에 저장
newNode->right = tree_restore(preOrder, inOrder, inIdx + 1, end); // 리턴하면서 부모의 오른쪽 주소에 저장
}
return newNode;
}
int main() {
tree* root = nullptr;
int preOrder[6] = { 1,2,4,5,3,6 };
int inOrder[6] = { 4,2,5,1,6,3 };
root = tree_restore(preOrder, inOrder, 0, 5);
return 0;
}이렇게 원본 트리를 복원할 수 있다.
※ 참고 : 혀니C - https://www.youtube.com/playlist?list=PLrj92cHmwIMdXsZm-AMZmp-nmJlRZh5fq
