1. 문자
1-1. 문자를 나타내는 방식
🔖예문
// 1Byte 자료형
char c = 1; // 컴파일 해보면 c에는 숫자 1에 대응하는 문자도 같이 보여준다. 문자 전용 자료형.
bool b = 1; // 컴파일 해보면 b에는 true라고 보여진다.
// 2Byte 문자를 표현하는 자료형도 있다.
wchar_t wc = 49; // 컴파일 하면 wc에는 49와 그 숫자에 대응하는 문자 1도 같이 보여준다.
short s = 49; // 컴파일 하면 s에는 49가 들어가 있다.📃 설명
ASCII 코드로 49라는 숫자가 문자 1을 의미하기 때문에 그렇게 보여진다.
숫자 1과 문자 1은 엄연히 다르다.
char c = '1'; // c에는 반대로 49가 저장되어 있다.문자 전용 자료형인 char는 1Byte이기 때문에 255개를 표현할 수 있다고 생각하지만,
UTF8같은 경우에 7Bit만 사용할 수 있어서 127개 까지만 표현할 수 있다.
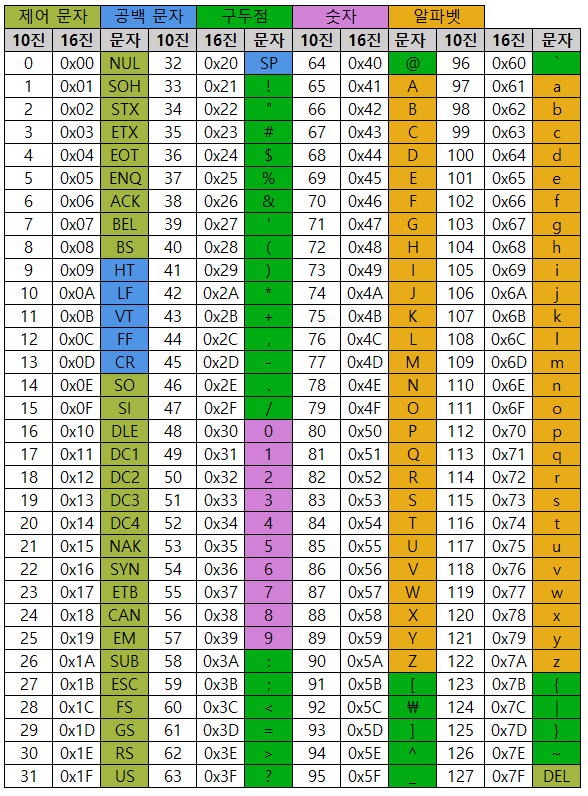
🔍참고
그냥 숫자를 대입했을 때는 메모리 안에 그 숫자에 해당하는 2진수 데이터를 넣으면 되지만,
문자를 대입했을 때는 문자 하나하나가 대응하는 숫자가 나열되는 구조이다.
예를들면, 문자 "459"는 4, 5, 9에 해당하는 1Byte 단위로 52, 53, 57이라는 숫자를 담고 있다.
일반적인 정수 데이터와 문자로서의 숫자를 착각하면 안된다.
또한 문자가 언제 끝날 것인지 알려주기 위해서 문자열 끝에 NUL을 입력해야 한다.
문자열 끝에는 NUL 숫자 0이 들어있다.
공백을 나타내는 SP와 헷갈리면 안된다. SP는 숫자로 32이다.
다시말해, "4 59" 문자열이 적혀있는 메모리 안에는 1Byte 단위로 52, 32, 53, 57, 0이 들어있다.
1-2. 문자열
char 자료형은 1Byte인데 7Bit만 사용할 수 있어서 문자를 127개만 표현할 수 있다고 했다.
반면 wchar_t 자료형은 2Byte라서 더 많은 문자를 표현할 수 있다.
🔖예문
char c = 'a';
wchar_t wc = L'a';📃 설명
char 자료형에서 문자를 표현할 때는 ' '작은 따옴표를 붙여서 표현하는데,
wchar_t 자료형에서는 앞에 L을 붙여서 ' ' 안에 문자를 2Byte 단위로 쓰겠다는 것이다.
문자열도 마찬가지이다.
🔖예문
char szChar[10] = "abcedf";
wchar_t szWChar[10] = L"abcedf"; // L은 문자 하나하나가 2Byte 단위라는것을 알려준다.
// 당연히 문자 자료형만 이렇게 초기화 할 수 있다.
short sArr[10] = L"abcedf"; // 컴파일 오류.
short sArr[10] = {97, 98, 99, 100, 101, 102}; // 이렇게 써야함.
wchar_t szWChar[10] = {97, 98, 99, 100, 101, 102}; // 이렇게 써도 위에 L"abcedf" 라고 초기화 한 것과 같다.🔍참고
abcdef 6개의 문자열이라고 해서 문자열이 6개만 필요하다고 생각하지만, 마지막에 NUL이 들어가야 하기 때문에 7개의 문자열이 필요하다.
char szChar[6] = "abcedf"; // 컴파일 오류.
char szChar[7] = "abcedf"; // 성립함.- 또 하나의 아래 예문을 살펴보자.
🔖예문
const wchar_t* pChar = L"abcedf"; // 성립한다.pChar 안에 abcedf 문자열이 저장된다는 것은 문자열의 정체가 주소값이라고 유추해 볼 수 있게된다.
다시말해, pChar에는 abcedf 문자열의 시작주소가 저장된다.
접근할 때는 wchar_t 자료형의 크기인 2Byte 단위로 접근할 것이다.
🔖예문
wchar_t szWChar[10] = L"abcedf";위 예문을 다시 살펴보자면 abcedf라는 문자열을 그대로 각각 2Byte 메모리 안에 옮겨오겠다는 의미이다. 둘의 차이를 알아야 한다.
그렇다면 아래 예문의 의미는 무엇일까?
🔖예문
wchar_t szWChar[10] = L"abcedf";
const wchar_t* pChar = L"abcedf";
szWChar[1] = 'z'; // 2Byte 각 메모리에 저장된 문자열에서 2번째인 b를 z로 바꾸라는 의미.
pChar[1] = 'z'; // 컴파일 오류. 주소에 접근해서 다이렉트로 값을 수정하라는 것은 불가능하다.그럼 const 키워드를 붙이지 않으면 접근해서 수정할 수 있는거 아닌가?
🔖예문
wchar_t* pChar = L"abcedf"; // 컴파일 오류. 애초에 문자열의 반환타입은 const 포인터 타입이다. const 포인터로만 받아야 함.
// 예전 버전의 컴파일러는 이것을 허용했지만 실수의 여지가 많아서 개선됐다.
// 컴파일 단계에서 오류를 잡아내면 수정할 수 있지만, 이건 실행단계에서 터져버리기 때문.📃 설명
전에 언급했던 메모리의 영역의 종류중에서, 읽기전용 메모리(ROM) 쪽을 수정하려고 하기 때문. 강제로라도 수정하려고 하면 결국 Runtime Error가 발생한다. 심각한 문제.
char 자료형 참고사항
위에서 char 자료형이 1Byte 단위로 문자를 표현한다고 했다. 하지만 char 자료형이 무조건 1Byte만 사용한다는 것은 아니다.
MultiByte라고 특정 문자는 2Byte로 표현하기도 한다. 문자에 따라 가변길이로 대응한다.
🔖예문
char szTest[10] = "abc한글";📃 설명
위 예문에서 한글은 한 글자당 1Byte로 표현할 수 없어서 2Byte로 표현해야 하는데 이것을 멀티바이트 방식으로 표현을 한다.
멀티바이트 방식은 현재 표준으로 쓰이지 않는 방식이다.
현재는 모든 문자를 2Byte로 표현하는 wchar_t 자료형을 쓰는 유니코드 방식을 사용한다.
문자열 갯수 세기
🔖예문
wchar_t szName[10] = L"Raimond";
// 문자가 몇개인지 알고 싶다
int iLen = wcslen(szName); // iLen에 7이 대입📃 설명
wcslen() : 문자열의 길이를 알려주는 기능. 정확하게 알려주려면 직접 데이터에 접근을 해서 알려줘야 하기에 ( ) 안에 const wchar_t* 형식으로 알려달라고 한다. 즉, 배열의 시작주소를 알려줘야 한다. 배열의 이름이 곧 시작주소이기 때문에 배열의 이름을 넣어주면 된다.
wcslen 함수를 직접 만들어보자
🔖예문
unsigned int GetLength(const wchar* _pStr)
{
int iValue = 0;
while(true)
{
wchar_t c = *(_pStr + iValue); // _pStr[iValue]; 이것과 같다.
if('\0' == c) break; // '\0' : NULL 문자 표현방식
++iValue;
}
return iValue; // NULL 문자가 나올때까지 증가한 수를 리턴
}
int main()
{
wchar_t szName[10] = L"Raimond"; // 7개의 문자를 가진 문자열
int i = GetLength(szName); // i에 7이 대입
}🔍참고
c == '\0' 라고 안쓰고 반대로 쓴 이유는, 만약 c = '\0' 라고 했을 경우에 컴파일러가 이걸 실수라고 잡아내지 못하기 때문.
비교연산 할 때 반대로 쓰는 것을 습관을 들이는게 좋다.
문자열 이어붙이기
wcscat_s(); // 문자열 이어붙이는 기능을 하는 함수. 두 가지로 오버로딩 되어있는 함수이다.- 함수 오버로딩(function overloading) : 동일한 이름의 함수가 여러개 만들어지는것을 의미한다.
(오버라이딩(overriding)과는 다르다. 헷갈리면 안됨.)
🔖예문
void Test(int a)
{
}
void Test(int a, int b)
{
}
// 함수명은 같은데 들어갈 인자의 타입, 갯수등 차이가 있을 때 함수를 호출할 시 어떤걸 호출할 건지 컴파일러가 구별해 줄 수 있다.다시 wcscat_s()함수를 이용해서 문자열 이어붙이기를 해보자.
🔖예문
int main()
{
wchar_t szString[100] = L"abc";
wcscat_s(szString, 100, L"def");
// 문자열이 의미하는 것이 주소이고 const 포인터 타입이기 때문에 L"def" 라고 집어넣어도 아무 문제가 없다.
// 읽기전용 메모리 영역에 저장되어 있는걸 가져다 쓴다.
wcscat_s(szString, 100, L"ghi"); // szString에 abcdefghi가 저장된다.
return 0;
}wcscat()함수를 직접 만들어보자
🔖예문
...
#include <assert.h> // 경고를 발생시킬 수 있는 기능이 있다.
unsigned int GetLength(const wchar* _pStr) // 위에서 만든 문자열 갯수 세는 함수
{
int iValue = 0;
while(true)
{
wchar_t c = *(_pStr + iValue);
if('\0' == c) break;
++iValue;
}
return iValue;
}
void StrCat(wchar_t* _pDest, int _iBufferSize, const wchar_t* _pSrc)
{
// 예외처리 : 이어붙인 최종 문자열의 길이가 Dest 저장공간을 넘어서려는 경우
int iDestLen = GetLength(_pDest);
int iSrcLen = GetLength(_pSrc);
if (_iBufferSize < iDestLen + iSrcLen + 1) // NULL 문자 공간까지 계산
{
assert(nullptr); // 경고를 띄운다. ( ) 안에 내가 넣고싶은 경고 메시지를 넣을 수 있다.
}
// 문자열 이어붙이기
// 1. Dest 문자열의 끝을 확인 (문자열이 이어 붙을 시작 위치)
// iDestLen;
// 2. 반복적으로 Src 문자열을 Dest 끝 위치에 복사하기
// 3. Src 문자열의 끝을 만나면 반복 종료
for (int i = 0; i < iSrcLen + 1; i++)
{
_pDest[iDestLen + i] = _pSrc[i];
}
}
int main()
{
wchar_t szString[10] = L"abc";
StrCat(szString, 10, L"def"); // szString 에 abcedf 가 저장.
return 0;
}내가 혼자 만들어본 wcscat() 함수
🔖예문
...
#include <assert.h> // 경고를 발생시킬 수 있는 기능이 있다.
void StrCat(wchar_t* _pDest, int _iBufferSize, const wchar_t* _pSrc)
{
int i = 0;
int j = 0;
while (true)
{
// 1. _pDest[i]가 NULL이면 _Src[j] 대입한다.
if ('\0' == _pDest[i])
{
_pDest[i] = _pSrc[j];
++j;
}
++i;
// 2. Src 문자열의 끝을 만나면 반복 종료
if ('\0' == _pSrc[j]) break;
// 3. iBufferSize < i 이면 경고메시지를 띄운다.
if (_iBufferSize < i) assert(nullptr);
}
}
int main()
{
wchar_t szString[10] = L"abc";
StrCat(szString, 10, L"def"); // szString 에 abcedf 가 저장.
// StrCat(szString, 10, L"defghijklm"); // 10개를 초과하기 때문에 경고메시지 발생.
return 0;
}문자열 비교하기
wcscmp()함수를 이용해서 두 문자열을 비교할 수 있다.
완벽히 일치하면 0이 나온다.
다르면 어느쪽이 더 우열인지 판단해서 왼쪽이 -1, 오른쪽이면 1이 나온다.
🔖예문
int iRet = wcscmp(L"abc", L"abc"); // iRet에는 0이 저장됨.
iRet = wcscmp(L"cbc", L"abc"); // iRet에는 1이 저장됨.
iRet = wcscmp(L"abc", L"cbc"); // iRet에는 -1이 저장됨.wcscmp()함수를 만들어보자.
🔖예문
int Strcmp(const wchar_t* _pLSrc, const wchar_t* _pRSrc)
{
// 같은 위치의 문자를 비교 후 같으면 0, 왼쪽 인자가 더 크면 -1, 오른쪽 인자가 더 크면 1을 반환한다.
int i = 0;
while (!('\0' == _pLSrc[i] && '\0' == _pRSrc[i])) // 둘 다 NULL 값이 아니면 반복
{
if (*(_pLSrc + i) == *(_pRSrc + i)) // (_pLSrc[i] == _pRSrc[i]) 랑 같은 의미
{
++i; // 같으면 다음 위치를 비교한다.
}
else if (*(_pLSrc + i) < *(_pRSrc + i))
{
return -1; // 왼쪽이 더 크면 -1을 반환
}
else
{
return 1; // 오른쪽이 더 크면 1을 반환
}
}
return 0; // 반복문이 종료되도 반환되지 않았으면 문자열이 완벽히 일치한 것이므로 0을 반환
}
int main()
{
int iNum = Strcmp(L"abc", L"abca"); // abc가 abca보다 우선순위 이므로 -1을 반환한다.
return 0;
}2. 구조체 포인터
전에 배운 구조체를 가지고 포인터를 활용해보자.
🔖예문
typedef struct _tagMyst
{
int a;
float f;
}MYST; // 멤버변수 int a와 float f를 가진 구조체를 만들었다.
int main()
{
MYST s = {}; // 구조체의 초기화 방식은 배열과 같다.
MYST* pST = &s; // 포인터를 활용해서 주소를 저장
(*pST).a = 100;
(*pST).f = 3.14f;
// *pST로 주소에 접근하면 s의 값이 되는데
// s는 그 안에 a, f 가 멤버변수로 있기 때문에 (.) 으로 따로 초기화 할 수 있다.
pST->a = 100; // 위 방식을 이렇게 (->)로 표현할 수 있다. 위와 같은 의미.
pST->f = 3.14f;
return 0;
}3. 동적할당
3-1. 동적할당이란?
"메모리를 동적 할당한다"라는 뜻은 컴퓨터 프로그램이 실행되는 도중인 런타임 도중에 사용할 메모리 공간을 할당하는 것을 말한다. 동적 할당되는 메모리는 힙 메모리 영역에 생성되게 되며 컴파일 할 때에 메모리의 크기가 결정되는 데이터 영역이나 스택 영역의 정적 메모리 할당과는 대조적인 개념이다.
🔖예문
int main()
{
int* pInt = (int*)malloc(100); // malloc() : 메모리 할당 함수. 힙 영역에 100Byte의 메모리가 만들어진다.
// 잡힌 메모리 공간의 주소를 int형 포인터변수에 저장한다.
float* pF = (float*)malloc(4);
}📃 설명
힙 영역에 만들어진 메모리 공간은 void 타입으로, 정해진 타입이 없다.
그 공간이 어떤식으로 사용될지는 사용하는 쪽에서 결정하고, 포인터 변수 자료형에 따라 타입이 정해진다.
메모리 공간이라는 것은 애초에 목적이 없다.
사용하는 사람이 어떻게 사용하느냐에 따라서 언제든지 용도는 달라질 수 있다.
🔖예문
int main()
{
float* pF = (float*)malloc(4); // float 형식으로 4바이트 메모리 공간을 힙 영역에 만듦.
int* pI = (int*)pF; // pI에 float형 메모리 공간 pF를 강제로 int형으로 변환해서 저장.
*pF = 3.14f; // pF에 3.14 실수 타입 값을 저장.
int i = *pI; // i에는 3.14라는 실수를 정수타입으로 보니까 이상한 엄청 큰 숫자가 들어가게됨.
}3-2. 동적할당의 특징
- 런타임 중에 대응 가능
- 사용자가 직접 메모리를 관리해야함(해제까지)
🔖예문
int main()
{
int iInput = 0;
scanf_s("%d", &iInput);
int* pInt = nullptr;
if(100 == iInput)
{
pInt = (int*)malloc(100);
}
if(nullptr != pInt)
{
free(pInt); // 주소를 전달해주면 그 주소가 가리키는 곳의 힙 메모리를 해제시켜주는 함수.
// 따라서 지역, 전역 변수 주소를 주면 안된다. 힙 메모리 주소만.
// pInt 주소로 가서 거기에 있는 힙 메모리를 해제해준다.
}
}스택 영역이나 데이터 영역에 있는 메모리는 컴파일이나 프로그램이 실행될 때 생성되고 자동으로 사라지지만, 힙 영역에 있는 메모리는 동적할당 될 수도 있고 안될 수도 있다.
따라서 자동으로 해제되지 않기 때문에 메모리를 해제하는 것까지 신경을 써줘야 한다.
해제하지 않으면 메모리 누수라고 해서 그런 프로그램을 계속 실행시키다보면 메모리 부족현상으로 연결된다.
그래서 이러한 메모리 누수를 감지할 수 있는 디버그 함수도 존재한다.
