스택(Stack)
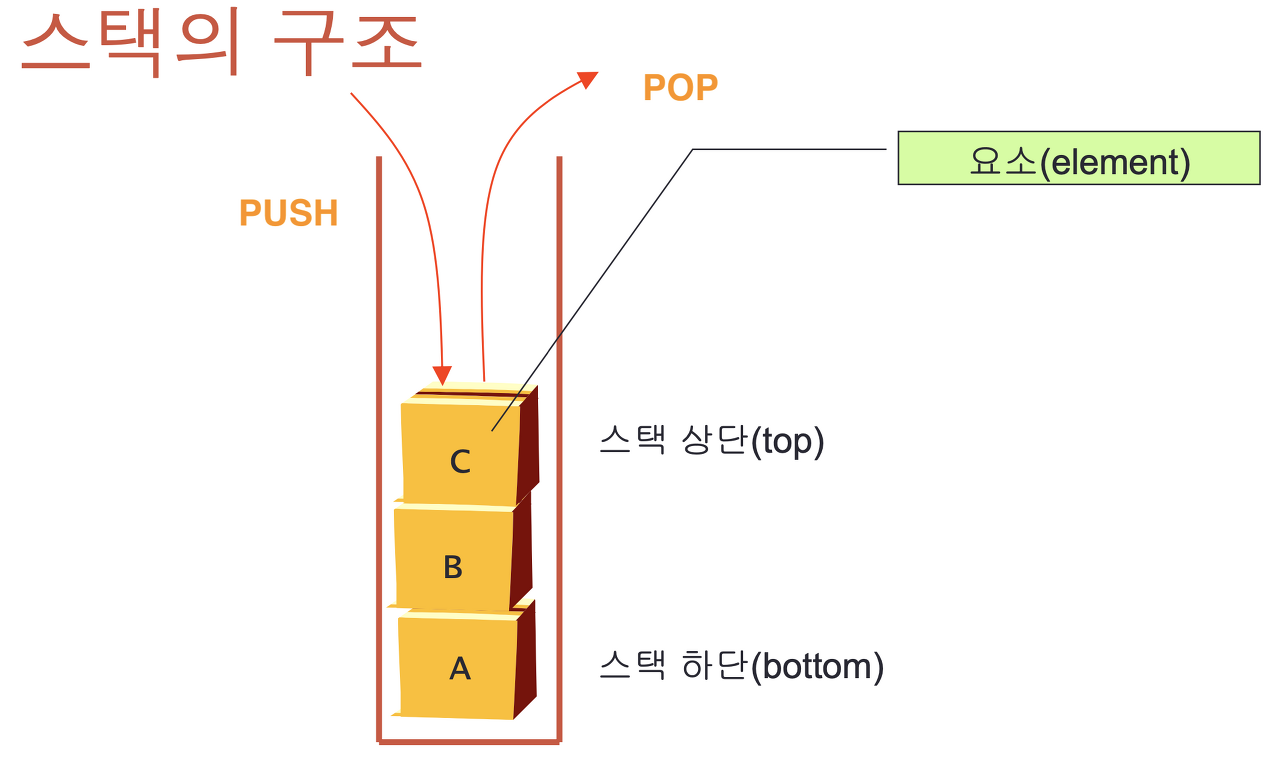
스택의 구조 및 개념
삽입(Push), 삭제(Pop) 가 한 쪽 방향에서 이루어 지는 자료구조 형태
데이터를 Push 할 때마다 차곡차곡 쌓이고, Pop 할 때는 마지막에 Push 한 데이터 부터 차례대로 꺼내지는 형태
LIFO (Last In First Out) 후입선출 구조
배열을 이용한 스택
배열에서의 스택은 가장 마지막에 Push 된 데이타의 위치, 즉 스택의 최상단을 항상 알고 있어야 하는데, 그러기 위해서 Top 이라는 int형 변수를 가지고 있어야 한다.
top 변수는 0 을 초기값으로 해서, 데이터가 삽입될 때마다 1 씩 증가시킨다. 즉, 가장 마지막에 삽입된 요소의 인덱스를 top 이 저장하게 된다.
삭제는 top 에 저장된 인덱스를 가진 배열의 요소를 삭제하면 되는데, 어차피 배열에서의 삭제는 메모리를 삭제하는 것이 아닌 다른 값을 대신 집어 넣는 방식이다 보니 '물리적인 삭제'가 아닌 '논리적인 삭제'를 적용시켜야 한다. 즉, top 을 0 해주면 스택에서 모든 데이터가 삭제가 된 것이 된다.
만약 더 이상 삭제할 데이터가 없는 경우, 즉 top = 0 인 경우를 Underflow 라고 하고, 반대로 top 이 '배열의 크기 - 1' 더 이상 데이터를 삽입할 수 없기 때문에 Overflow 라고 한다.
아래에서 코드로 한번 구현해보자.
스택 코드 구현
#include <stdio.h>
#include <stdlib.h>
// 스택 구조체 선언
typedef struct stack
{
int* arr; // int arr[10] 이렇게 정해진 크기의 배열을 써도 되지만,
// 크기를 조절할 수 있도록 하기 위해 포인터 주소를 넘겨주어 나중에 동적할당 해준다.
int top;
int capacity; // 배열의 용량
}stack;
// 스택 구조체 초기화 함수
void initializeStack(stack* p, int size)
{
p->arr = (int*)malloc(sizeof(int*)*size); // size 갯수만큼의 배열을 동적으로 생성한다.
p->top = 0;
p->capacity = size;
}
// 스택 Push 함수
void pushStack(stack* p, int data)
{
p->arr[p->top] = data; // top 을 인덱스로 하는 배열의 요소에 데이터를 삽입한다.
p->top++;
}
// 스택 Pop 함수
void popStack(stack* p)
{
p->top--; // 논리적인 삭제, 데이터는 그대로 남아있지만 쓰레기값으로 여겨진다.
}
// 스택 출력 함수
void printStack(stack* p)
{
for (int i = p->top - 1; i >= 0; i--) // 출력도 최근 삽입된 데이터부터 출력하기 때문에
{
printf("%d ", p->arr[i]);
}
}
// 스택 clear 함수
void clearStack(stack* p)
{
p->top = 0; // top 이 0이 되면 논리적인 삭제가 이루어져 모든 값은 쓰레기 값이 되버린다.
}
int main()
{
stack stk; // 총 16바이트의 메모리가 할당 된다.
initializeStack(&stk, 5); // stk 의 값이 바뀌길 원하기 때문에 주소를 넘겨준다.
pushStack(&stk, 99);
popStack(&stk);
return 0;
}
연결 리스트를 이용한 스택
연결 리스트에서의 스택은 Push 를 할 때, 맨 앞 삽입 방식을 사용하기 때문에 head 가 항상 마지막에 삽입된 데이터를 알고 있다. 따라서 배열이랑은 달리 top 변수가 필요 없다.
삭제할 때는 head 를 두번째 노드와 연결 해준 후 맨 앞 노드를 삭제해 주면 된다. 여기서는 배열처럼 '논리적인 삭제'가 아닌 실제 할당된 메모리를 삭제하는 것이기 때문에 '물리적인 삭제'가 된다.
삽입할 때 메모리를 동적 할당해서 생성하기 때문에 Overflow 는 생각할 필요가 없다. 대신 데이터가 없는 상태 즉, head 가 NULL 일 경우에는 Underflow 가 된다.
큐(Queue)
큐의 구조 및 개념
삽입(Enqueue)된 순서에 따라 삭제(Dequeue)가 이루어 지는 자료구조 형태.
스택과는 반대로 First In First Out(FIFO) 선입선출 구조이다.
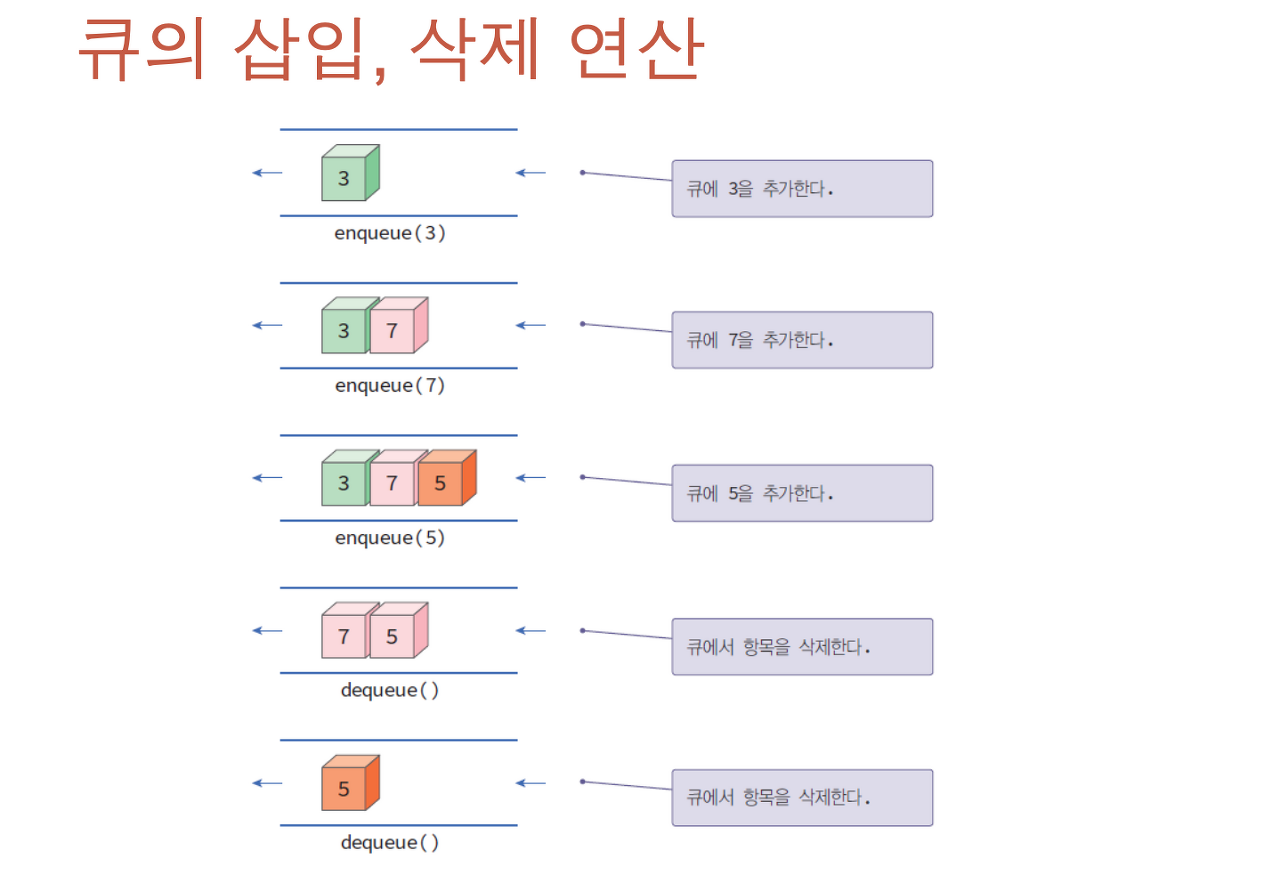
배열을 이용한 큐
위에 그림처럼 일렬로 나열된 배열이라고 생각했을 때, 맨 앞 데이터가 먼저 꺼내지면 그 다음 데이터부터는 한 칸씩 앞으로 옮겨져야 한다. 배열의 크기가 작다면 크게 문제가 없지만, 배열의 크기가 매우 커지게 되면 배열의 크기만큼 한 칸씩 앞으로 옮겨져야 하기 때문에 시간복잡도가 O(N)이 된다.
따라서 원형 큐 개념을 사용해야 한다.
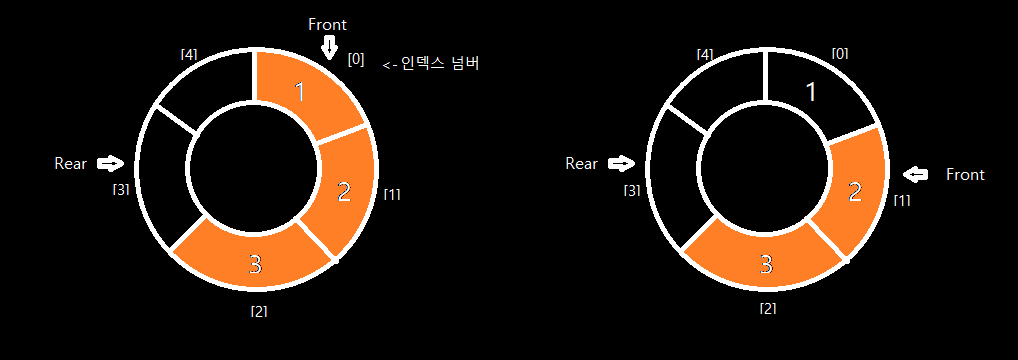
데이터는 위 그림에서 주황색으로 칠해진 front 부터 rear 전까지 존재하고, 삭제(Dequeue)를 할 때는 front 를 다음 인덱스로 증가시켜 '논리적인 삭제'를 적용시킨다.
만약, rear 가 인덱스 4를 넘어 5가 된다면 존재하지 않는 인덱스에 접근하기 때문에, 그때는 다시 0 으로 바꿔주는 코드가 필요하다.
front 와 rear 가 같은 위치에 있는 경우는 데이터가 하나도 없거나 가득 차있는 경우가 해당되기 때문에 이 둘을 구별해주기 위해서 count 라는 변수가 필요하다.
아래에서 코드로 구현해보자.
#include <stdio.h>
#include <stdlib.h>
// 큐 구조체 선언
typedef struct queue
{
int* arr; // 배열의 크기를 동적으로 할당하기 위해 포인터로 선언
int front; // 가장 첫번째 데이터의 위치
int rear; // 가장 마지막 데이터의 위치
int count; // 데이터의 갯수
int capacity; // 배열의 크기
}queue;
// 큐 구조체 초기화 함수
void queueInit(queue* pQ, int size)
{
pQ->arr = (int*)malloc(sizeof(int) * size);
pQ->front = 0;
pQ->rear = 0;
pQ->count = 0;
pQ->capacity = size;
}
// 큐 삽입(Enqueue) 함수
void enqueue(queue* pQ, int data)
{
if (pQ->count == pQ->capacity) // 데이터의 갯수가 배열의 크기와 같다면 queue overflow 를 출력
{
printf("queue overflow\n");
return;
}
pQ->arr[pQ->rear] = data;
pQ->rear++;
if (pQ->rear == pQ->capacity) // rear 가 배열의 크기와 같아지면 다시 인덱스 0 번으로 변경
pQ->rear = 0;
pQ->count++; // 데이터의 갯수 증가
}
// 큐 삭제(Dequeue) 함수
void dequeue(queue* pQ)
{
if (pQ->count == 0)
return;
pQ->front++;
pQ->count--;
if (pQ->front == pQ->capacity)
pQ->front = 0;
}
int main()
{
queue que;
queueInit(&que, 5);
enqueue(&que, 1);
dequeue(&que);
free(que.arr); // 동적할당된 메모리 해제
return 0;
}연결 리스트를 이용한 큐
연결리스트를 사용하기 위해서는 노드(Node)가 필요하다.
구조체를 만들어 줘야 한다.
typedef struct node {
int value;
struct node* next;
}node;배열을 이용한 큐에서는 배열을 할당해준 뒤에 값을 집어넣어주면 됐었지만,
연결리스트에서는 시작 노드를 저장할 수 있는 포인터 한개만 필요하게 된다.
int main()
{
node* head = NULL; // 시작 노드를 저장하는 포인터 변수 head를 선언
}FIFO(First In First Out) 구조로 연결을 하기 위해서,
삽입은 '맨 뒤 삽입' 방식으로 삽입이 이루어져야 한다.
...
이미지 출처 https://lsh424.tistory.com/

안녕하세요 검색하다 찾았는데 저랑 관심사가 많이 겹치네요. 자주 올게요!