
배치 작업 ← 데이터를 실시간으로 처리하는 게 아닌 일괄적으로 모아서 처리하는 작업
Spring Batch는 엔터프라이즈 시스템의 운영에 있어 대용량 일괄처리의 편의를 위해 설계된 가볍고 포괄적인 배치 프레임워크다. Spring의 특성을 그대로 가져왔기 때문에 DI, AOP, 서비스 추상화 등 Spring 프레임워크의 3대 요소를 모두 사용할 수 있다.
보통 아래와 같은 경우 많이 사용한다.
- 대용량의 비즈니스 데이터를 복잡한 작업으로 처리해야하는 경우
- 특정한 시점에 스케쥴러를 통해 자동화된 작업이 필요한 경우 (ex. 푸시알림, 월 별 리포트)
- 대용량 데이터의 포맷을 변경, 유효성 검사 등의 작업을 트랜잭션 안에서 처리 후 기록해야하는 경우
Spring Batch는 로깅/추적, 트랜잭션 관리, 작업 처리 통계, 작업 재시작, 건너뛰기, 리소스 관리 등 대용량 레코드 처리 에필 수적인 재사용 가능한 기능을 제공한다. 또한 최적화 및 파티셔닝 기술을 통해 대용량 및 고성능 일괄 작업을 가능하게 하는 고급 기술 서비스 및 기능을 제공한다.
스프링 배치(Spring Batch)란? 소개 및 예제
배치는 언제 사용하는가?
- 예약 시간에 광고성 메시지 발송
- 결제한 내역을 정산
- 운영을 위해서 필요한 통계 데이터 구축
- 대량 데이터를 필요로 하는 모델 학습 작업
왜 위 기능들은 배치를 통해서 일괄 처리를 해야하는가?
- 메시지 예약같이 기능 스펙상 실시간으로 처리할 수 없는 경우
- 리소스를 효율적으로 사용할 수 있다.
- 자동적으로 일괄 처리하기에 리소스 낭비를 줄일 수 있다.
왜 스프링 배치이어야 하는가?
- 스프링에서 제공하는 특성 그대로 사용가능하기에
- 유지보수가 좋기에
- AOP, DI, Test 등의 기능을 그대로 사용가능하기에
- 유지보수가 좋기에
스프링 배치에는 일정 시간에 자동으로 잡이 실행되는 스케쥴링 기능이 없다.
→ 스프링 배치 ≠ 스케쥴링
→ 스프링 스케쥴러나 Quartz등을 통해서 함께 사용할 수 있긴함.
→ 스프링 배치는 Job을 관리하나 실행시키는 주체는 아니다.
Job ← Feature 하나
ex) 수업전 알람을 주는 job ← 하나의 Job
Job은 여러 step으로 이루어져 있다.
ex) 수업전 알람을 주는 job ← 알람 대상인 사용자를 가져오는 step, 알람을 전송하는 step
step ← 순차적으로 이루어진 작업을 캡슐화한 도메인 객체
step은 테스트 클릭 기반 step, chunk 기반 step으로 나눌 수 있다.
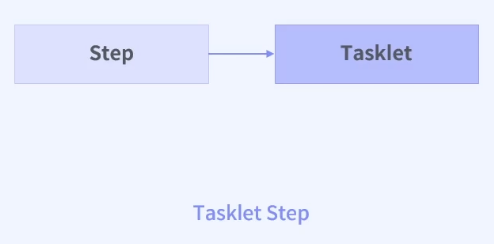
- 테스트 클릭 기반 step
- 단일 작업을 처리할 때 사용 = 간단히 정의한 하나의 작업 처리
1. 오래된 데이터를 삭제한다.
2. 이미 정의된 알람을 전송한다.
-
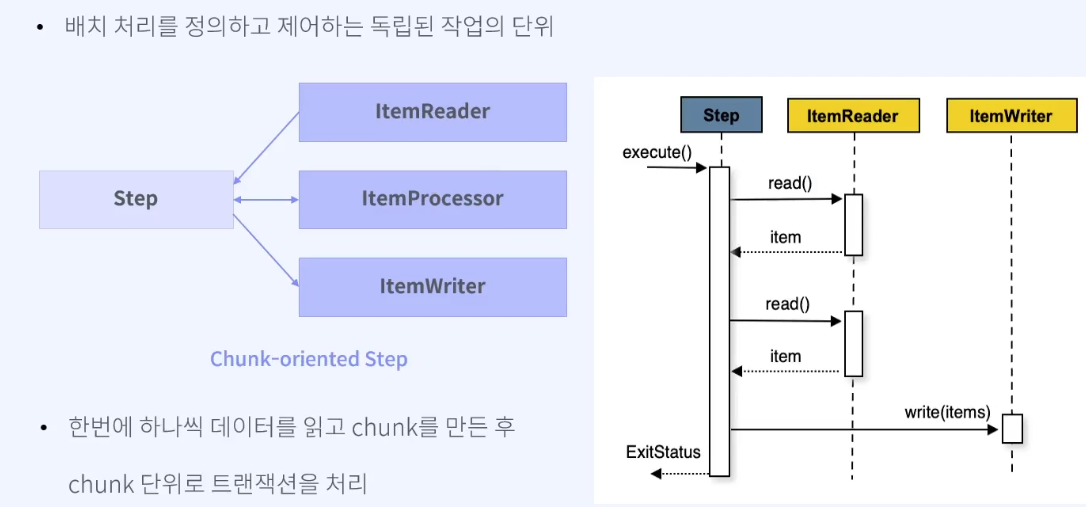
chunk 기반 step
-
아이템 기반으로 처리를 하게 돼서 아이템 리더, 아이템 프로세서, 아이템 라이터라는 부분으로 구성
- 아이템 프로세서는 필수 요소가 아니기에 필요한 경우에만 사용
-
Roop 1 : chunk 단위(=가져올 데이터 수)만큼 ItemReader로 조회하고, 아이템을 가져온다.
-
Roop 2 : 그 후에 동일하게 아이템 갯수만큼 ItemProccesor로 가서 데이터를 처리한다.
-
위 2번의 루프가 끝나면 아이템들을 한번에 ItemWriter로 쏴서 모두 전달한다.
-
Roop 3 : 전체 과정(1~ 2)을 아이템을 다 읽을 때까지 루프하는 것
-
chunk 기반 step은 한번에 하나씩 데이터를 읽고 chunk를 만든 후 chunk 단위로 트랜잭션을 처리한다.
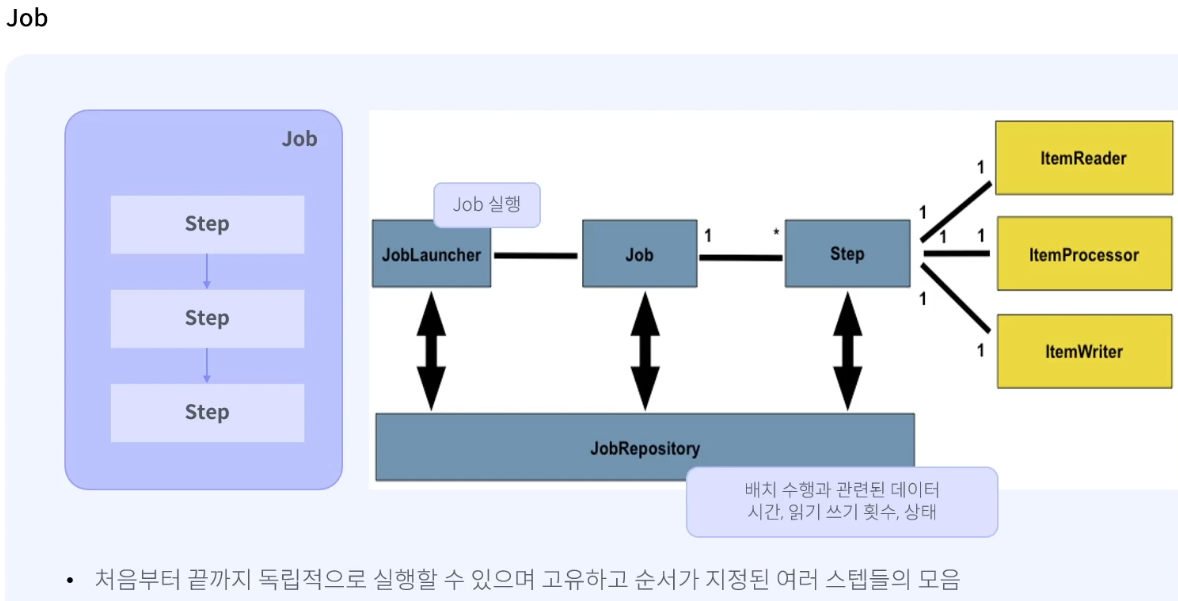
Job은 유일하고, 고유하고 순서를 가진 여러 스텝들의 목록이며 외부 의존성에 영향을 받지않고 실행이 가능해야 하는 독립적인 작업이다.
Job은 정의된 step의 순서대로 작업을 진행한다.
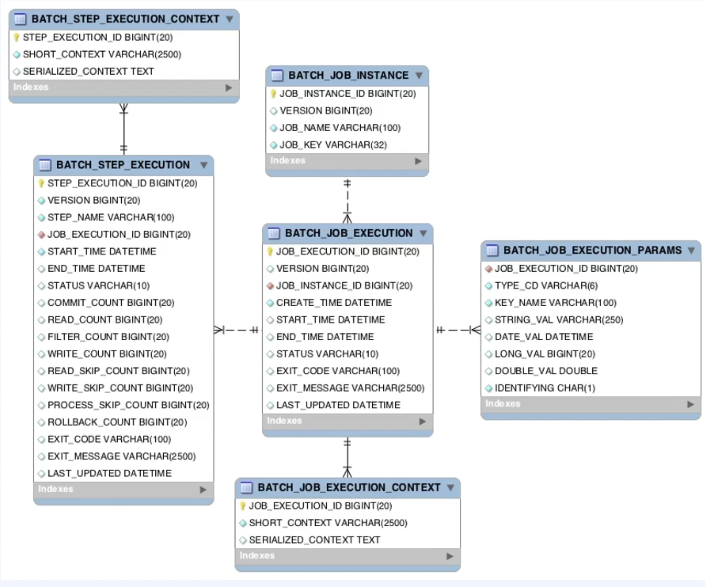
jobRepository
→ 배치 수행과 관련된 데이터를 가지고 있다. ex) 시작하는 시간, 종료하는 시간, job의 상태, 읽는 건수, 쓰는 건수 등등
→ 일반적으로 rdb를 사용
→ 스프링 배치 내에 대부분의 컴포넌트들이 해당 데이터를 공유한다.
→ 스프링 설정을 통해서 애플리케이션 실행시 없으면 자동적으로 생성하게끔 할 수 있다.
→ 인메모리 데이터 방식도 지원함.
jobLauncher
→ job을 실행하는 역할, job을 현재 스레드에서 수행할지, 스레드 풀을 이용할지, job을 실행할 때 필요한 파라미터는 유효한지 검증
→ jobLauncher를 통해서 job을 실행하면, job은 정의된 step을 실행하게 된다. step은 위에서 이야기한대로 3단계의 루프를 거친다. 루프를 거치면서, jobRepository의 읽고, 쓰기 건수등을 update 한다.
Feature 하나 하나 정의해보기
- 이용권 만료
job : 이용권 만료
step : 이용권 만료, Chunk 방식 채택
- 이용권 만료 대상을 읽어서 그 대상들을 만료 상태로 업데이트 시키면 된다.
- step 내부
- ExpirePassesReader
- ExpirePassesWriter
- 이용권 일괄 지급
job : 이용권 일괄 지급
step : 이용권 일괄 지급, 테스크 기반 방식 채택
- step 내부
- AddPassesTasklet
~2번까지의 배치 구조는 job 내에서 step을 정의된 순서대로 단일 Thread로 실행하는 것이었다.
그러나 대량의 데이터를 다룰수록 병렬처리는 핵심이된다.
그렇기에 3번은 대량의 데이터를 배치할 때 병렬 처리 방식을 도입한다.
- 예약 수업 전 알람
job : 예약 수업 전 알람
step : 알람 대상 가져오기, 알람 전송하기, Chunk 방식 채택
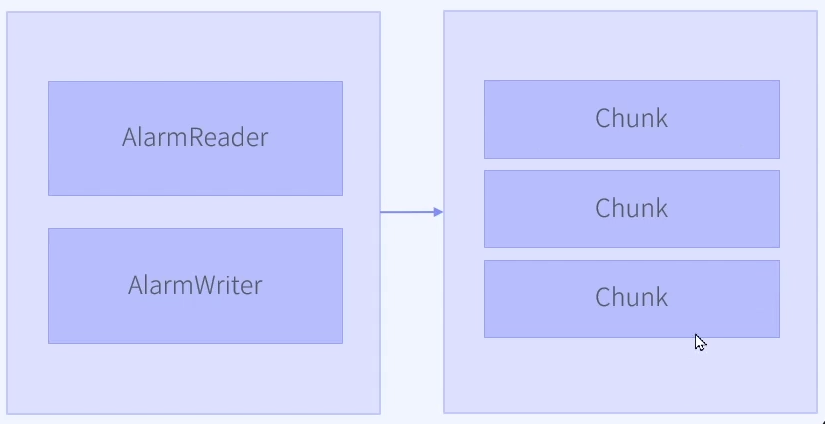
왼쪽 step이 알람 대상을 가져오는 step이고, 오른쪽 step이 알람을 병렬적으로 전송하는 step이다.
chunk 기반의 step 에서는 chunk 단위로 처리되고 각자 독립적인 트랜잭션이 적용된다.
그렇기에 100개의 커밋이 있으면, 순차적으로 커밋을 완료해간다.
이는 대용량에서 극심한 속도 문제를 가져다준다.
그러나 병렬처리로 하면 Chunck 개수만큼 빠른 작업 속도를 보여준다.
- 이용권 차감
job : 이용권 차감
step : 이용권 차감, chunk 기반 방식 채택
- step 내부
- UsePassesReader
- AsyncItemProcessor
- AsyncItemWriter
시간상 오래걸리는 로직이나 트랜잭션이 있는 경우 Async를 적용
- 시간당 통계 데이터
job : 이용권 차감
step : 이용권 차감, chunk 기반 방식 채택
- step 내부
- StaticsReader
- StatsticsWriter
이 경우에 step을 서로 병렬로 작업한다.
→ step끼리 연관이 없기에, 서로 기다릴 필요가 없다. 그렇기에 동시에 병렬로 작업
