회사 코드를 온보딩 기간 중 살펴보던 중 CrudRepositry를 구현한 Repository가 있어 왜 JpaRepsotiory 대신 사용하셨을까라는 궁금증으로 해당 차이점을 공부하기 시작했다.
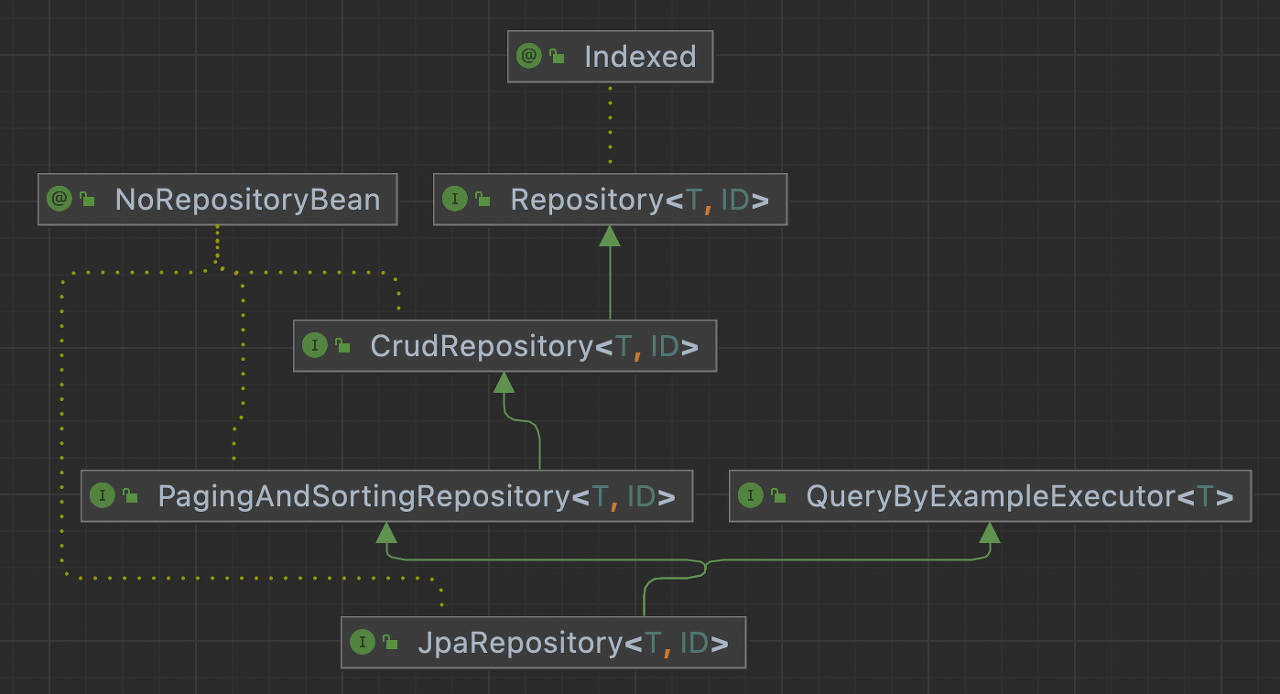
위 사진은 Repository간 상속 계층이다.
일단 CrudRepository와 JpaRepository 둘 다 Repository를 확장한 ''인터페이스''라는 공통점이 있다.
대표적인 차이점이라면 CrudRepository는 Repository를 상속받으며 CRUD 기능이 명세되어있다는 것이고, JpaRepository는 이 CrudRepository를 상속한 PagingAndSortingRepository를 상속받았다는 것이다.
즉 JpaRepository는 기본적인 CRUD 기능과 더불어 페이징 및 정렬 관련 기능 명세도 추가되어있다는 것이다.
자세히 코드를 보면서 살펴보자.
CrudRepository
- 코드 보기
@NoRepositoryBean public interface CrudRepository<T, ID> extends Repository<T, ID> { /** * Saves a given entity. Use the returned instance for further operations as the save operation might have changed the * entity instance completely. * * @param entity must not be {@literal null}. * @return the saved entity; will never be {@literal null}. * @throws IllegalArgumentException in case the given {@literal entity} is {@literal null}. */ <S extends T> S save(S entity); /** * Saves all given entities. * * @param entities must not be {@literal null} nor must it contain {@literal null}. * @return the saved entities; will never be {@literal null}. The returned {@literal Iterable} will have the same size * as the {@literal Iterable} passed as an argument. * @throws IllegalArgumentException in case the given {@link Iterable entities} or one of its entities is * {@literal null}. */ <S extends T> Iterable<S> saveAll(Iterable<S> entities); /** * Retrieves an entity by its id. * * @param id must not be {@literal null}. * @return the entity with the given id or {@literal Optional#empty()} if none found. * @throws IllegalArgumentException if {@literal id} is {@literal null}. */ Optional<T> findById(ID id); /** * Returns whether an entity with the given id exists. * * @param id must not be {@literal null}. * @return {@literal true} if an entity with the given id exists, {@literal false} otherwise. * @throws IllegalArgumentException if {@literal id} is {@literal null}. */ boolean existsById(ID id); /** * Returns all instances of the type. * * @return all entities */ Iterable<T> findAll(); /** * Returns all instances of the type {@code T} with the given IDs. * <p> * If some or all ids are not found, no entities are returned for these IDs. * <p> * Note that the order of elements in the result is not guaranteed. * * @param ids must not be {@literal null} nor contain any {@literal null} values. * @return guaranteed to be not {@literal null}. The size can be equal or less than the number of given * {@literal ids}. * @throws IllegalArgumentException in case the given {@link Iterable ids} or one of its items is {@literal null}. */ Iterable<T> findAllById(Iterable<ID> ids); /** * Returns the number of entities available. * * @return the number of entities. */ long count(); /** * Deletes the entity with the given id. * * @param id must not be {@literal null}. * @throws IllegalArgumentException in case the given {@literal id} is {@literal null} */ void deleteById(ID id); /** * Deletes a given entity. * * @param entity must not be {@literal null}. * @throws IllegalArgumentException in case the given entity is {@literal null}. */ void delete(T entity); /** * Deletes the given entities. * * @param entities must not be {@literal null}. Must not contain {@literal null} elements. * @throws IllegalArgumentException in case the given {@literal entities} or one of its entities is {@literal null}. */ void deleteAll(Iterable<? extends T> entities); /** * Deletes all entities managed by the repository. */ void deleteAll(); } - 코드에 나오는
@NoRepositoryBean은 Repository 인터페이스 받았기에, Spring Data JPA나 다른 Repository가 실제 빈을 만들지 않도록 지정하는 어노테이션이다.
JpaRepository
- 코드 보기
@NoRepositoryBean public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> { /* * (non-Javadoc) * @see org.springframework.data.repository.CrudRepository#findAll() */ @Override List<T> findAll(); /* * (non-Javadoc) * @see org.springframework.data.repository.PagingAndSortingRepository#findAll(org.springframework.data.domain.Sort) */ @Override List<T> findAll(Sort sort); /* * (non-Javadoc) * @see org.springframework.data.repository.CrudRepository#findAll(java.lang.Iterable) */ @Override List<T> findAllById(Iterable<ID> ids); /* * (non-Javadoc) * @see org.springframework.data.repository.CrudRepository#save(java.lang.Iterable) */ @Override <S extends T> List<S> saveAll(Iterable<S> entities); /** * Flushes all pending changes to the database. */ void flush(); /** * Saves an entity and flushes changes instantly. * * @param entity entity to be saved. Must not be {@literal null}. * @return the saved entity */ <S extends T> S saveAndFlush(S entity); /** * Saves all entities and flushes changes instantly. * * @param entities entities to be saved. Must not be {@literal null}. * @return the saved entities * @since 2.5 */ <S extends T> List<S> saveAllAndFlush(Iterable<S> entities); /** * Deletes the given entities in a batch which means it will create a single query. This kind of operation leaves JPAs * first level cache and the database out of sync. Consider flushing the {@link EntityManager} before calling this * method. * * @param entities entities to be deleted. Must not be {@literal null}. * @deprecated Use {@link #deleteAllInBatch(Iterable)} instead. */ @Deprecated default void deleteInBatch(Iterable<T> entities) { deleteAllInBatch(entities); } /** * Deletes the given entities in a batch which means it will create a single query. This kind of operation leaves JPAs * first level cache and the database out of sync. Consider flushing the {@link EntityManager} before calling this * method. * * @param entities entities to be deleted. Must not be {@literal null}. * @since 2.5 */ void deleteAllInBatch(Iterable<T> entities); /** * Deletes the entities identified by the given ids using a single query. This kind of operation leaves JPAs first * level cache and the database out of sync. Consider flushing the {@link EntityManager} before calling this method. * * @param ids the ids of the entities to be deleted. Must not be {@literal null}. * @since 2.5 */ void deleteAllByIdInBatch(Iterable<ID> ids); /** * Deletes all entities in a batch call. */ void deleteAllInBatch(); /** * Returns a reference to the entity with the given identifier. Depending on how the JPA persistence provider is * implemented this is very likely to always return an instance and throw an * {@link javax.persistence.EntityNotFoundException} on first access. Some of them will reject invalid identifiers * immediately. * * @param id must not be {@literal null}. * @return a reference to the entity with the given identifier. * @see EntityManager#getReference(Class, Object) for details on when an exception is thrown. * @deprecated use {@link JpaRepository#getReferenceById(ID)} instead. */ @Deprecated T getOne(ID id); /** * Returns a reference to the entity with the given identifier. Depending on how the JPA persistence provider is * implemented this is very likely to always return an instance and throw an * {@link javax.persistence.EntityNotFoundException} on first access. Some of them will reject invalid identifiers * immediately. * * @param id must not be {@literal null}. * @return a reference to the entity with the given identifier. * @see EntityManager#getReference(Class, Object) for details on when an exception is thrown. * @deprecated use {@link JpaRepository#getReferenceById(ID)} instead. * @since 2.5 */ @Deprecated T getById(ID id); /** * Returns a reference to the entity with the given identifier. Depending on how the JPA persistence provider is * implemented this is very likely to always return an instance and throw an * {@link javax.persistence.EntityNotFoundException} on first access. Some of them will reject invalid identifiers * immediately. * * @param id must not be {@literal null}. * @return a reference to the entity with the given identifier. * @see EntityManager#getReference(Class, Object) for details on when an exception is thrown. * @since 2.7 */ T getReferenceById(ID id); /* * (non-Javadoc) * @see org.springframework.data.repository.query.QueryByExampleExecutor#findAll(org.springframework.data.domain.Example) */ @Override <S extends T> List<S> findAll(Example<S> example); /* * (non-Javadoc) * @see org.springframework.data.repository.query.QueryByExampleExecutor#findAll(org.springframework.data.domain.Example, org.springframework.data.domain.Sort) */ @Override <S extends T> List<S> findAll(Example<S> example, Sort sort); }
위 코드들 중 눈 여겨보아야 할 메서드는 findAll() 메서드이다.
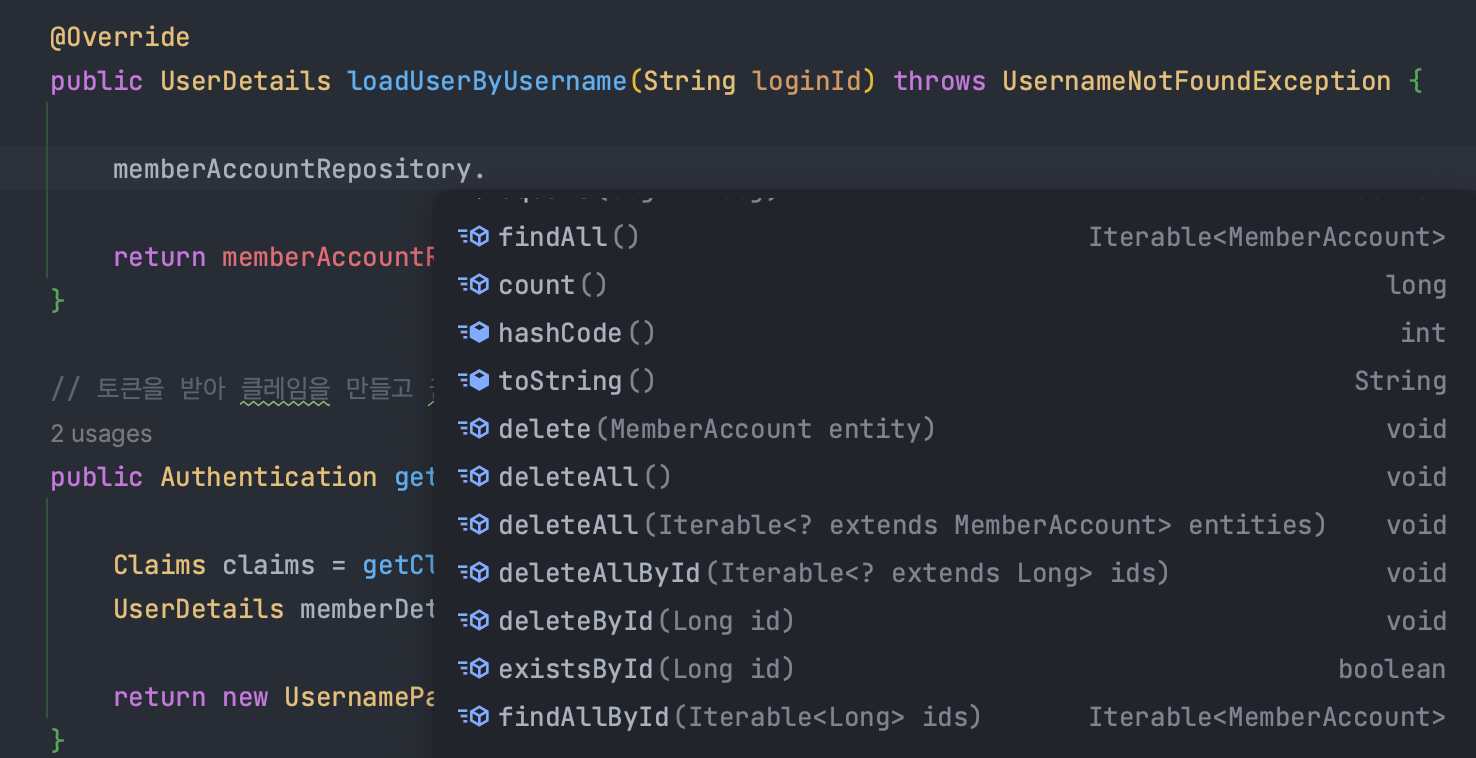
CrudRepository 같은 경우에는 반환 타입이 Iterable이며, 별도 정렬은 지원하지 않고 있다.
그러나 PagingAndSortingRepository 을 상속받은 JpaRepository 같은 경우에는 반환 타입이 List이며, Sort 관련 인자를 받아 정렬을 지원하는 걸 볼 수 있다.
여기까지가 두 Repository의 대표적인 차이점 및 특징이며, 궁금증을 해결해보자.
그러면 왜 CrudRepository를 사용했을까?
나는 그 코드를 작성했던 사람이 아니기에 정확한 이유까지는 알지 못한다. 그러나 내가 해당 주제를 통해 알아보기 위해 찾아봤던 레퍼런스들에서 이야기한 것 중 공감하는 내용들을 유추해볼 수 있다.
첫번째 이유로는 시스템의 설계를 간단하게 만들기 위해서이다.
내가 만약 페이징 및 정렬 기능을 사용하지 않고, 단순한 CRUD 기능만을 필요로 한다고 하자. 그럴 경우에 JpaRepository를 사용할 경우, 불필요한 페이징 및 정렬 관련 Interface 또한 상속을 받아야 한다.
또 어떤 이들은 이런 아직 사용하지 않는 기능들을 위한 불필요한 상속들을 제하기 위해서 기본 Repository 인터페이스를 상속받는 사람들도 많았다.
두번째 이유로는 다른 개발자들이 명세를 보고 헷갈리지 않게 하기 위해서이다.
우리 기능이 페이징 및 정렬같은 기능들을 사용하지 않는데, JpaRepository를 상속받아서 사용한다면 다른 개발자들이 페이징 및 정렬의 기능들을 사용한다고 인터페이스 명세를 보고 헷갈릴 수 있기 때문이다.
아래 사진은 CrudRepository를 상속받았을 때이다.
아래 사진은 JpaRepository를 상속받았을 때이다.
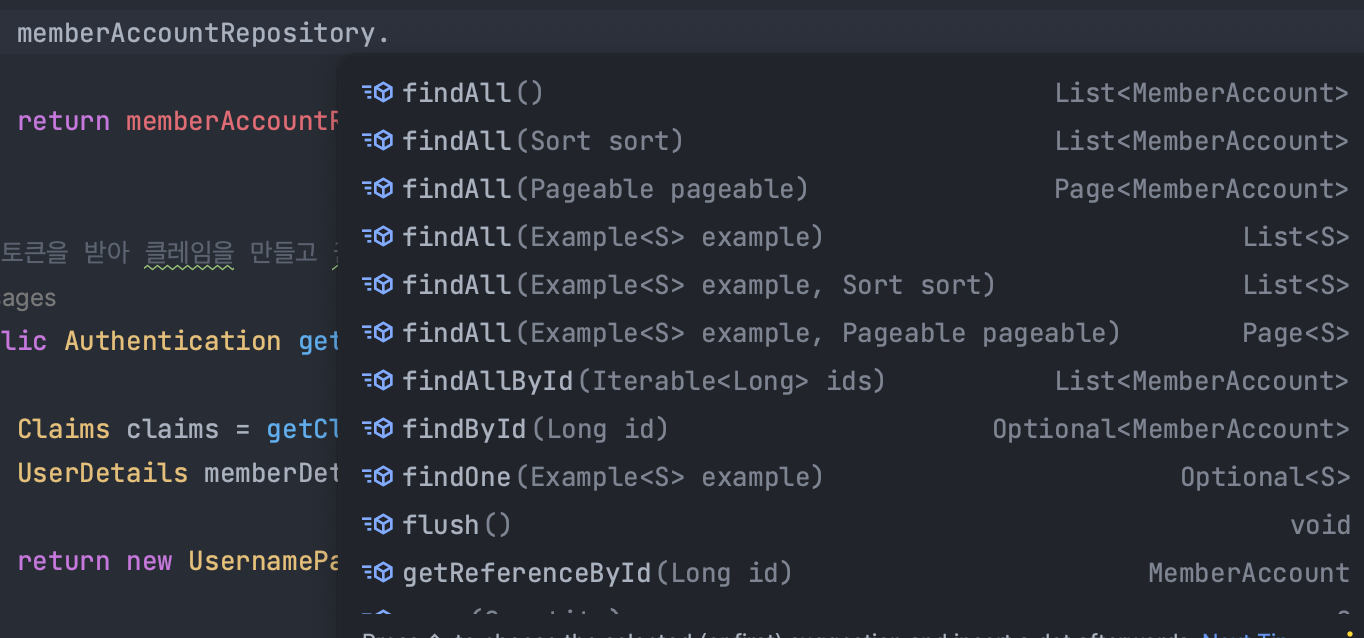
위 사진을 보면 같은 메서드라 할지라도 인터페이스의 다른 인자 타입이나 반환 타입으로 인해서 개발자에게 충분히 혼동을 줄 수 있다.
