
데이터베이스 성능 핵심

-
데이터베이스는 디스크에 저장된다.
-
디스크는 메모리에 비해 훨씬 느리다.
-
데이터베이스 성능 핵심은 디스크 접근을 최소화 하는 것이다.
-
어떻게 디스크 접근을 줄일 수 있을까?
-
디스크에서 메모리에 올라온 데이터로 최대한 요청을 처리하는 것 = 메모리 캐시 히트율을 높이는 것
- 데이터베이스에 쓸 때도 곧 바로 디스크에 쓰는게 아니라 메모리에 쓴다.
- 메모리에 쓴 데이터가 날라가는 것을 대비해 WAL(Write Ahead Log)를 사용한다.
-
디스크에 접근 하는 방법은 두가지 방법이 있다.
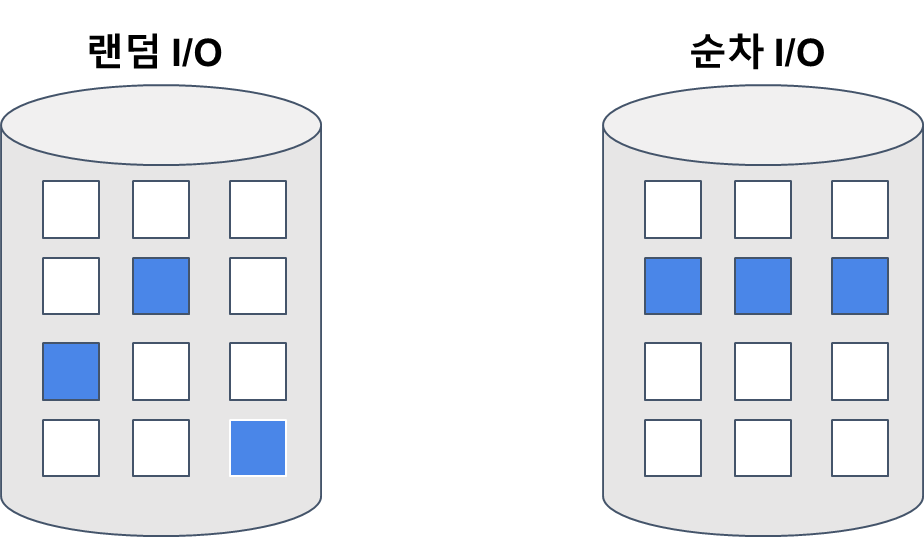
- 랜덤 I/O는 디스크에 랜덤으로 접근해서 데이터를 가져온다.
- 순차 I/O는 디스크에 순차적으로 접근
-
대부분의 트랜잭션은 무작위하게 Write가 발생(A 테이블의 10번 ID 값 가져와줘, 25번 ID값 가져와줘) → 그래서 이를 메모리에 바로 Write 하는게 아니라 메모리에 순차적으로 저장(순차 I/O 처럼 저장)을 시킨 후 한번에 디스크에 저장함 → 이 때 메모리에서 유실 될 것을 방지하기 위해서 WAL을 통해 LOG에도 저장한다.
-
메모리에 순차적으로 저장시키면, 디스크에 랜덤 I/O로 접근하는 것을 최소화할 수 있다.
-
-
데이터베이스 성능의 핵심은 디스크의 랜덤 I/O (접근)을 최소화 하는 것이다.
-
인덱스를 사용하면, 이런 불필요한 랜덤 I/O 접근을 줄여서 데이터 탐색 성능을 개선할 수 있다.
인덱스만을 메모리에 적재하고, 원하는 데이터의 물리적 주소를 찾아 접근하면 되기 때문이다.
인덱스란 쉽게 생각하면 책에 있는 내용을 시험에 대비해서, 시험에 나올 것 같은 부분들만 따로 정리본을 만드는 것이다. 오픈 북 테스트에서 정리본을 1차로 보고, 2차로 책을 찾아볼 것이다. 만약 정리본에서 많이 나온다면 효율적일 것이고, 아니면 책을 풀 스캔 하는게 효율적일 수도 있을 것이다.
인덱스의 기본 동작
- 인덱스는 정렬된 자료구조이며, 이를 통해서 탐색 범위를 최소화한다.
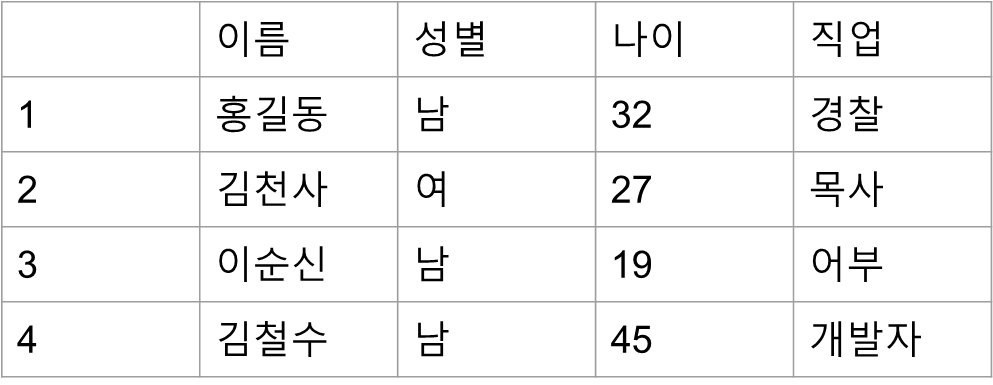
- 위 표에서 가장 어린 사람을 찾고 싶다면 모든 행을 다 뒤져봐야 한다.
만약 인덱스가 존재한다면?
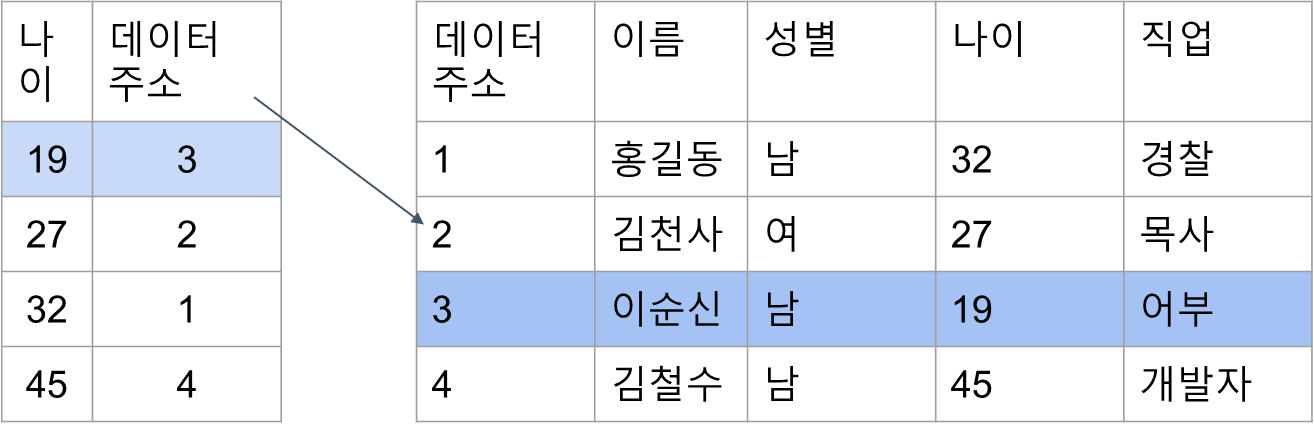
- “나이” 특성에 대한 인덱스를 만들게 되면, 나이를 기준으로 정렬 후 가장 어린 나이의 데이터 주소를 반환하면 된다.
- 데이터가 이미 나이순으로 정렬되어 있어서 하나만 조회하면 됨
- 인덱스도 테이블이다.
- 인덱스의 핵심은 탐색(검색) 범위를 최소화 하는 것이다.
인덱스 자료구조
- Tree → 트리 높이에 따라 시간 복잡도가 결정되기에 트리 높이를 최소화하는 것이 중요
- 그렇기에 한쪽으로 노드가 치우치지 않도록 균형을 잡아주는 트리 사용 → B(Balanced) + Tree
B + Tree
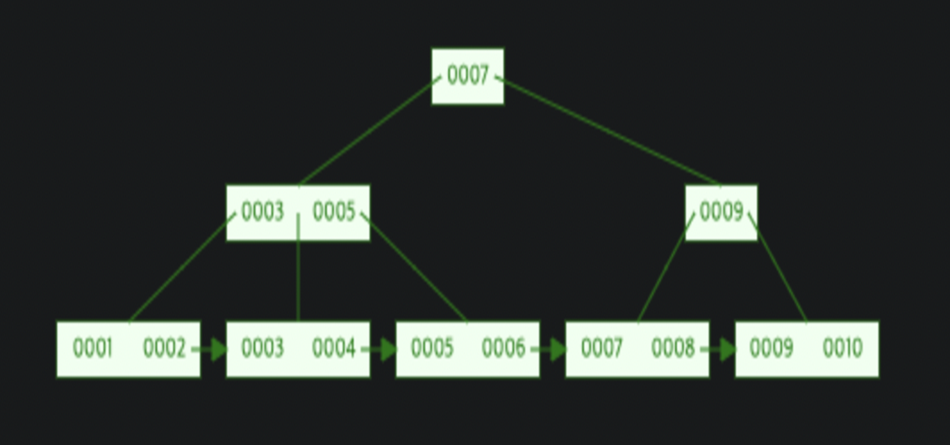
- 삽입 / 삭제시 항상 균형을 이룸
- 하나의 노드가 여러 개의 자식 노드를 가질 수 있음
- 리프 노드의 키에만 데이터 포인터를 가지고 있다.
- 리프 노드간 연결 리스트로 연결되어있기 때문에 정렬 상태의 리프 노드를 순차 탐색할 수 있다.
- B+Tree는 B-Tree와 다르게, 리프 노드에만 데이터 포인터가 존재하므로 노드에 더 많은 키를 보관할 수 있게 된다. 이는 곧 트리의 높이가 낮아지는 것을 의미하고, 탐색 속도가 B-Tree에 비해 더 향상됨을 의미한다.
- 다만, B+Tree에서는 실제 데이터에 접근하기 위해서는 무조건 리프 노드까지 탐색해야한다. 따라서 운이 좋으면, 금방 데이터를 찾을수도 있는 B-Tree와 다르게, B+Tree는 고정적으로 O(logN)의 탐색 시간을 갖는다.
데이터 포인터(data pointer)
- B + Tree의 리프 노드의 각 키는 실제 데이터의 물리적 위치를 가리키고 있는 데이터 포인터(data pointer)를 가지고 있다. 키를 기준으로 데이터를 탐색한 뒤, 일치하는 키를 발견한 경우 데이터 포인터가 가리키는 곳으로 이동해 실제 데이터를 찾을 수 있다.
- 데이터베이스에서는 특정 컬럼으로 인덱스를 생성할 수 있는데, 이때 컬럼의 값이 키가 되고, 테이블의 행(데이터의 물리적 위치)는 데이터 포인터가 된다.
- 인덱스를 사용하게 되면, 읽기 성능은 올라가지만, 쓰기 성능은 내려간다.
클러스터 인덱스
-
클러스터 인덱스는 데이터 위치를 결정하는 키 값이다.
-
클러스터 키는 정렬되어있고, 정렬된 순서에 따라 데이터의 주소가 결정된다.

-
클러스터 키 순서에 따라서 데이터 저장 위치가 변경된다. → 클러스터 키 삽입 / 갱신시에 성능 이슈 발생
-
- MySQL의 PK는 클러스터 인덱스다.
- 이는 PK 순서에 따라서 데이터 저장 위치가 변경된다. → PK 삽입 / 갱신시에 성능 이슈 발생
- 이를 고려하여서 PK로 Auto Increment or UUID 중 어떤 것을 선택할지를 결정해야 한다.
- MySQL에서 PK를 제외한 모든 인덱스는 PK를 가지고 있다.
- PK의 사이즈가 인덱스의 사이즈를 결정
- 세컨더리 인덱스(=PK를 제외한 모든 인덱스)만으로는 데이터를 찾아갈 수 없다. → PK 인덱스를 항상 검색해야 함
- 당연하긴 하다. userName이 “kevin”인 유저가 여러 명 있을 수 있기에 중복되는 값들 간 반드시 구별할 PK가 필요하다.
- 예를 들어서 Student 테이블에서 pk와 name, age 필드 3개가 있다면, pk는 클러스터 인데스이고, 필드를 제외한 name, age 필드들은 세컨더리 인덱스이다.
- 세컨더리 인덱스는 여러개 가질 수 있고, Unique할 필요가 없다.
클러스터 인덱스 장점
- PK를 활용한 검색이 빠름. 특히 범위 검색
- 세컨더리 인덱스들이 PK를 가지고 있어 커버링(인덱스에 있는 값을 반환하기에, 테이블까지 가지 않도록 하는 방법)에 유리
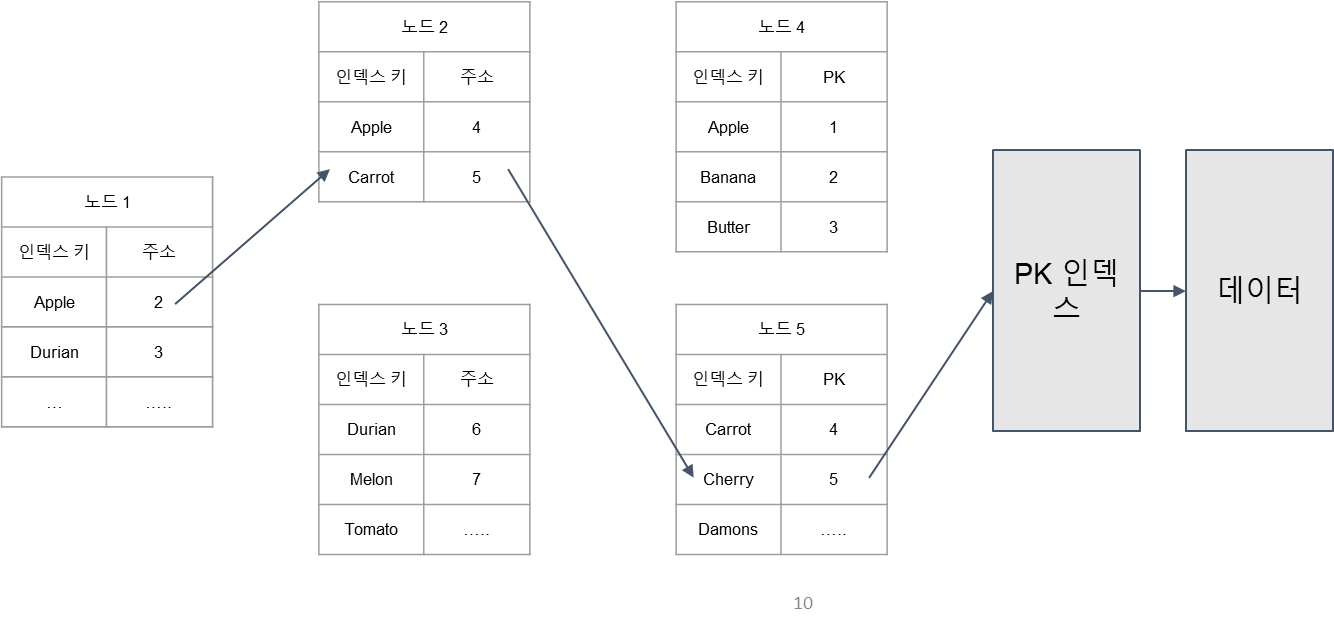
세컨더리 인덱스가 PK 인덱스로 가는 과정
- 인덱스 검색이기에 인덱스 순으로 리프 노드(노드 4, 5)가 정렬되어있다. → 리프 노드에만 값이 있다.
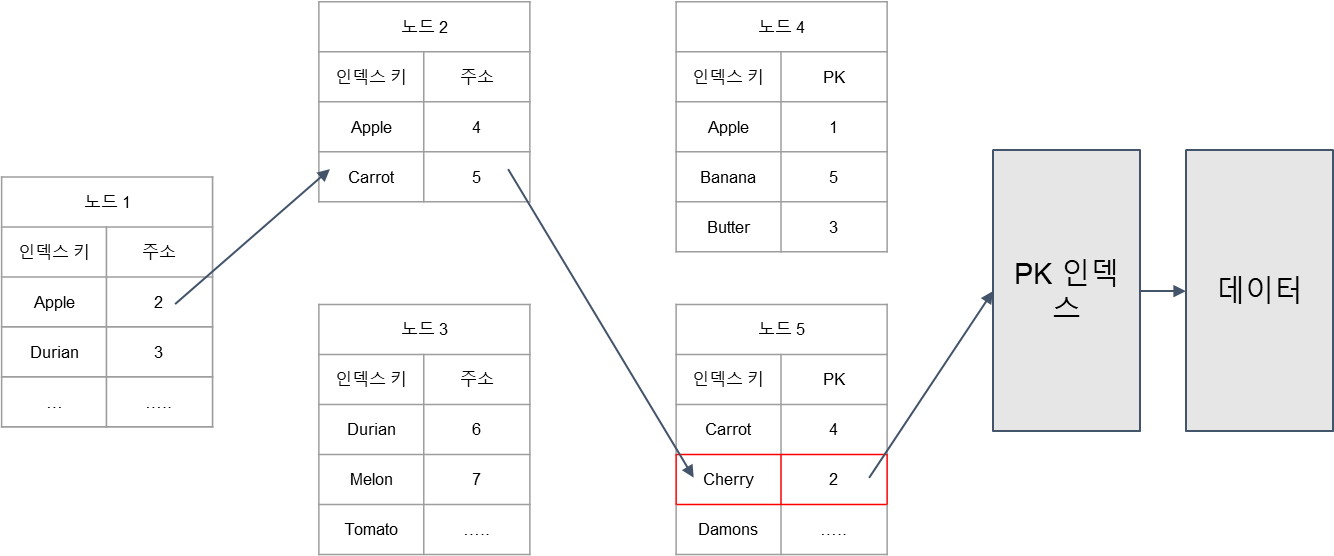
- 체리를 찾아보는 과정을 살펴보자.
- 노드 1에서 체리는 Durian 이전에 있으니까 주소 2번으로 간다.
- 노드 2번에서 Carrot 이후에 있으니까 주소 5번으로 간다.
- 리프 노드 5번에서 Cherry를 찾게 되고, 2번 PK로 PK 인덱스에게 요청을 한다.
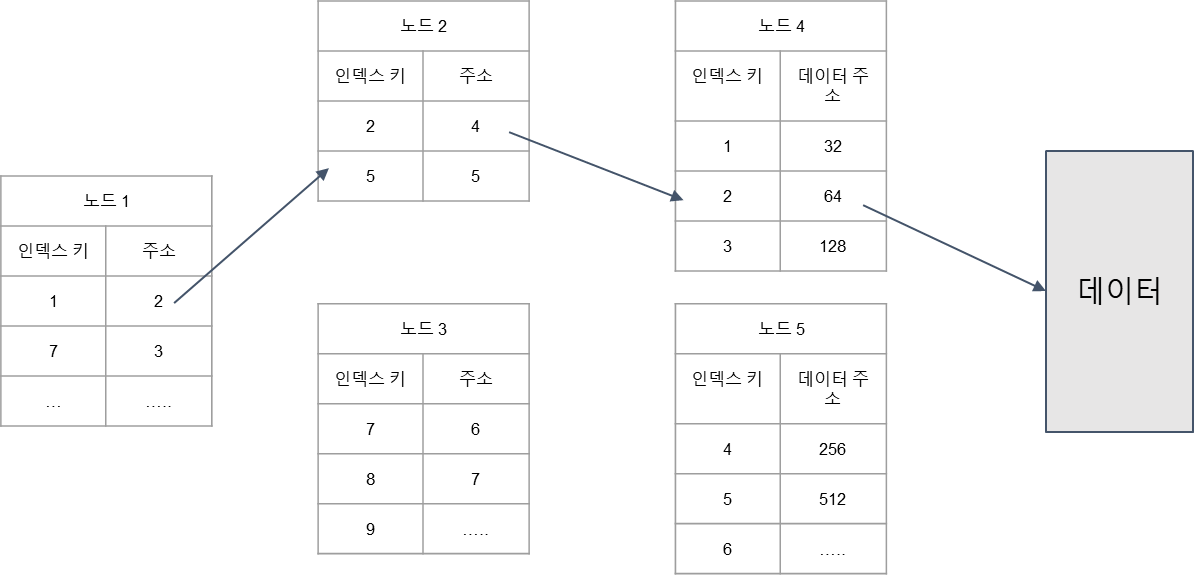
- PK 인덱스로 넘어온 화면이다.
- 2번 PK를 찾아야 하는데, 7보다 작으니 주소 2로 간다.
- 노드 2에서 2번을 찾아서 바로 주소 4로 간다.
- 노드 4에서 데이터 주소 64를 찾아서 데이터를 가져온다.
내가 이해하고, 나름대로 정의를 내린 인덱스
우리는 DB는 디스크에 존재하기에 해당 디스크에 접근해서 데이터를 가져와야 한다. 이 때 디스크에 접근하는 방식 중 한 방식인 랜덤 I/O 방식은 치명적인 성능 이슈를 가지고 있다. 이 때 인덱스를 사용하면 인덱스만을 메모리에 올려서 적재하고, 인덱스를 통해 원하는 물리적 데이터의 위치를 알아내서 접근하면 랜덤 I/O 방식을 최소화 할 수 있다.
인덱스는 B + Tree 자료 구조로 이루어져 있으며, MySQL 같은 경우 PK는 클러스터링 인덱스로 자동으로 구성되는데, 클러스터링 인덱스란 데이터의 물리적 저장 위치를 결정하는 키 값이라고 생각하면 된다.
PK를 제외한 나머지 필드는 세컨더리 인덱스로 구성할 수 있는데, 세컨더리 인덱스는 여러개를 가질 수 있고, Uniuque 하지 않아도 가능하다.
궁금한 점
질문
- Spring JPA를 사용할 때 @Index 어노테이션을 사용해서, 인덱스를 걸 수 있는 걸로 알고 있는데 이 경우 세컨더리 인덱스만 거는걸까? 그리고 PK 같은 경우에는 자동으로 클러스터링 인덱스가 걸어질까?
답변
- @Index 어노테이션은 세컨더리 인덱스를 생성하는 어노테이션이다. 또한 PK는 자동으로 클러스터링 인덱스가 걸어지는건 아니고, 만약 ddl-auto 옵션과 MySQL을 사용한다면 테이블 생성시 PK는 자동으로 클러스터링 인덱스가 걸어질 것이다!!
참고 자료
