1️⃣ 쓰레드 개념
프로세스란 간단히 말해서 ‘실행중인 프로그램’이다.
프로그램을 실행하면 OS로부터 실행에 필요한 자원(메모리)를 할당받아 프로세스가 된다.
프로세스는 프로그램을 수행하는 데 필요한 데이터와 메모리 등의 자원 그리고 쓰레드로 구성되어있다.
- 모든 프로세스에는 최소한 하나 이상의 쓰레드가 존재하며, 둘 이상의 쓰레드를 가진 프로세스를 ‘멀티쓰레드 프로세스’라고 칭한다.
- 프로세스 → 공장
- 쓰레드 → 공장에서 일하는 일꾼
Java에서는 그래서 Main 메서드가 Main Thread이다.
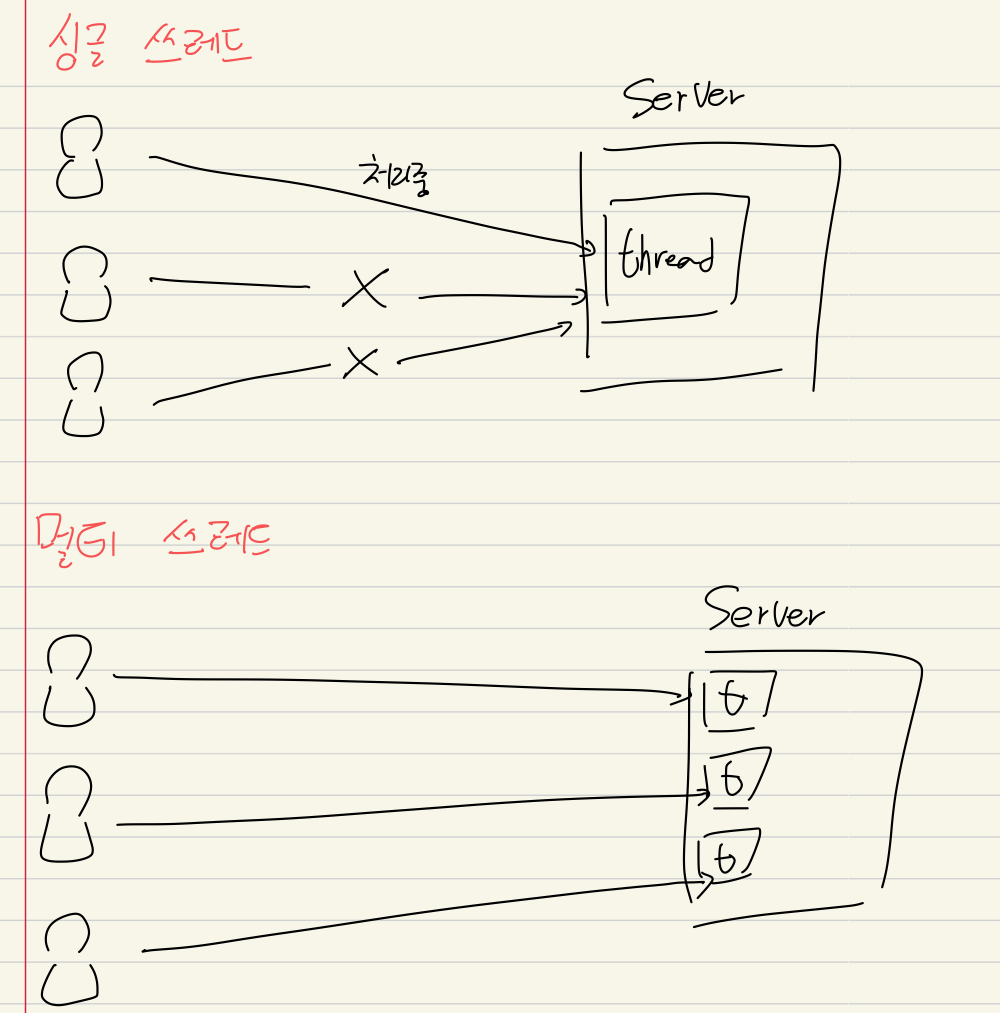
- 해당 Main Thread만 이용하는 거면 싱글 쓰레드로 프로그램이 돌아가는 것이다.
멀티 쓰레딩은 하나의 프로세스 내에서 여러 쓰레드가 동시에 작업을 수행하는 것이다.
- CPU 코어가 한번에 단 하나의 작업만 수행할 수 있으므로, 실제로 동시에 처리되는 작업의 개수는 코어의 개수와 일치한다.
프로세스의 성능이 단순히 쓰레드의 개수에 비례하는 것은 아니며, 하나의 쓰레드를 가진 프로세스보다 두 개의 쓰레드를 가진 프로세스가 오히려 더 낮은 성능을 보일 수도 있다.
멀티 쓰레딩의 장점은 아래와 같다.
- CPU 사용률 향상
- 자원을 보다 효율적으로 사용
- 사용자에 대한 응답성이 향상
- 작업이 분리되어서 코드 간결화
여러 사용자에게 서비스를 해주는 서버 프로그램의 경우 멀티 쓰레드로 작성하는 것은 필수적이어서, 하나의 프로세스가 여러 쓰레드를 생성해서 쓰레드와 사용자의 요청이 일대일로 처리되도록 프로그래밍 해야한다.
2️⃣ 프로세스 개념
쓰레드를 구현하는 방법은 일반적으로 Thread 클래스 상속, Runnable 인터페이스 구현 2가지 방식이 있다.
일반적으로는 Thread 클래스를 상속받으면 다른 클래스를 상속받을 수 없기에, Runnable 인터페이스를 구현하는 방법을 사용한다.
Main method
public class Main {
public static void main(String[] args) {
Runnable t1 = new ThreadEx();
Thread thread = new Thread(t1);
thread.start();
}
}Runnable 인터페이스를 구현한 Thread
public class ThreadEx implements Runnable{
@Override
public void run() {
System.out.println("쓰레드가 동작 중입니다.");
}
}Runnable 인터페이스
@FunctionalInterface
public interface Runnable {
public abstract void run();
}쓰레드를 구현한다는 것은 그저 쓰레드를 통해 작업하고자 하는 내용으로 run() 메서드의 몸통을 채우는 것 뿐이다.
Runnable 인터페이스를 구현한 후, Runnable 인터페이스를 구현한 클래스의 인스턴스를 생성한 다음, 이 인스턴스를 Thread 클래스의 생성자의 매개변수로 제공해야 한다.
왜냐면 Thread 클래스의 생성자에서는 Runnable 인터페이스를 구현한 클래스의 인스턴스를 인스턴스를 참조해서, 상속을 통해서 run()을 오버라이딩 하지 않아도, 외부로부터 run()을 제공받을 수 있게 된다.
Thread 클래스의 생성자
public Thread(Runnable target) {
this(null, target, "Thread-" + nextThreadNum(), 0);
}3️⃣ Thread의 실행 - start()
쓰레드가 생성되었다고 해서 자동으로 실행되는 것은 아니다. start()를 호출해야만 쓰레드가 실행된다.
- 정확히는 start()가 호출되었다고 해서 바로 실행되는 것이 아니라, 일단 실행대기 상태에 있다가 자신의 차례가 되어야 실행된다.
한번 실행이 종료된 쓰레드는 다시 실행할 수 없다.
Thread 클래스의 start() method
public synchronized void start() {
if (threadStatus != 0)
throw new IllegalThreadStateException();
group.add(this);
boolean started = false;
try {
start0();
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
}
}
}- 내부적으로 started 변수를 두어서 이를 구현한다.
4️⃣ start()와 run()
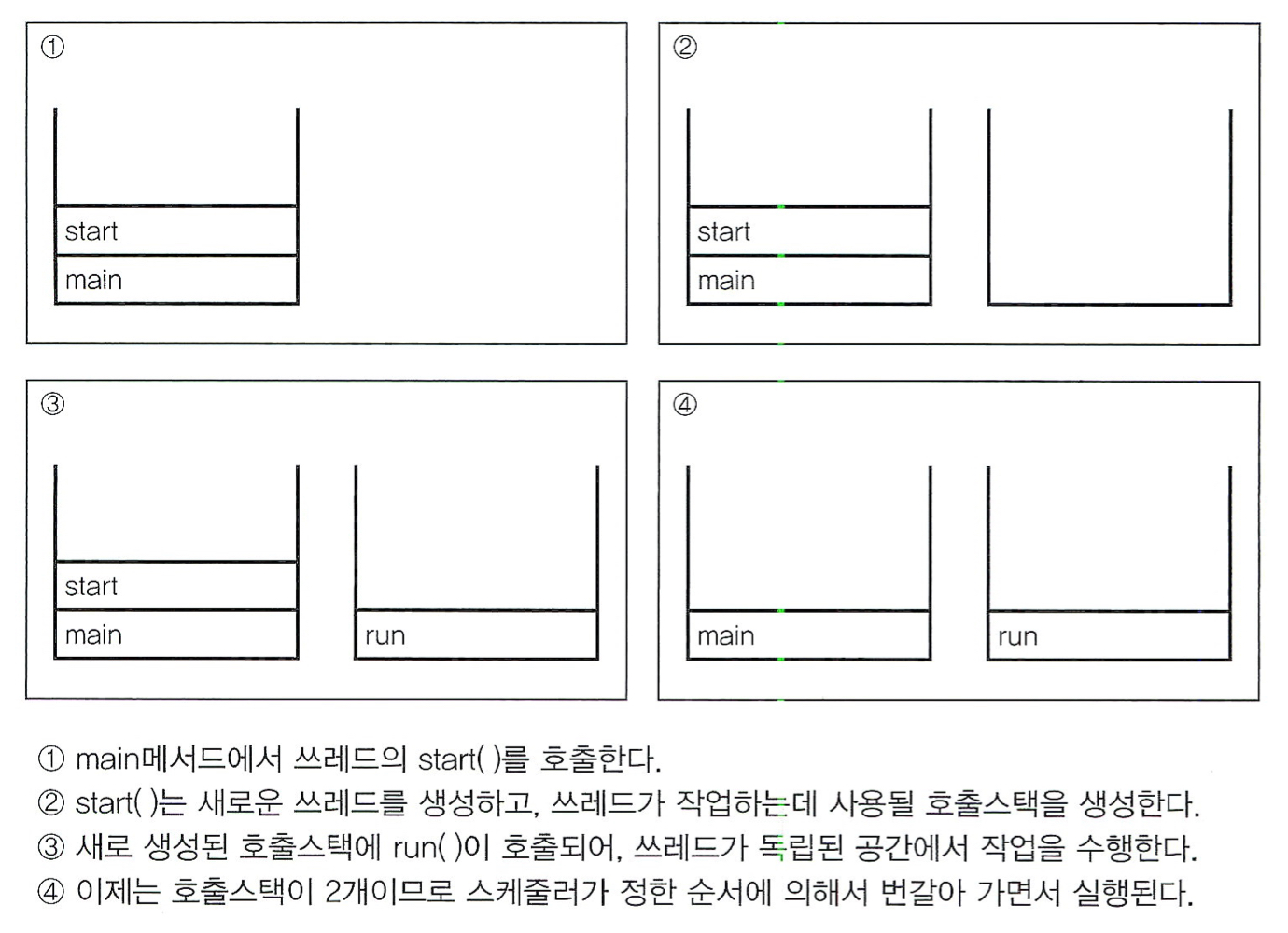
main() 메서드에서 run()을 호출한다는 것은 생성된 쓰레드를 실행시키는 것이 아니라 단순히 클래스에 선언된 메서드를 호출하는 것일 뿐이다.
- 즉 새로운 쓰레드를 생성하는 것이 아니다.
모든 쓰레드는 독립적인 작업을 수행하기 위해서 자신만의 호출 스택을 필요로 한다. 즉 새로운 쓰레드를 만들 때도 자신만의 호출 스택을 만들어주어야 한다.
start() 메서드는 새로운 쓰레드가 작업을 실행하는데 필요한 호출 스택을 생성한 다음에 run()을 호출해서, 생성된 호출 스택에 run()이 첫번째로 올라가게 한다.
- 즉 새로운 쓰레드를 생성한다.
5️⃣main Thread
main 메서드의 작업을 수행하는 것도 쓰레드이며, 이를 main 쓰레드라고 한다.
그래서 프로그램을 실행하면 기본적으로 하나의 쓰레드(일꾼)을 생성하고, 그 쓰레드가 main 메서드를 호출해서 작업이 수행되도록 한다.
- Spring boot Application도 서버 실행시 main Thread를 생성하고 이 쓰레드가 main Method를 호출해서 작업이 수행되도록한다.
프로그램은 Main 메서드의 종료 여부와 관계 없이, 실행중인 사용자 쓰레드가 하나도 없을 때 프로그램은 종료된다.
6️⃣ 싱글 쓰레드와 멀티 쓰레드
자바가 OS(플랫폼) 독립적이라고 하지만 실제로는 OS 종속적인 부분이 몇가지 있는데 쓰레드도 그 중 하나이다.
두 쓰레드가 서로 다른 자원을 사용하는 작업의 경우에는 싱글 쓰레드 프로세스보다 멀티 쓰레드 프로세스가 더 효율적이다.
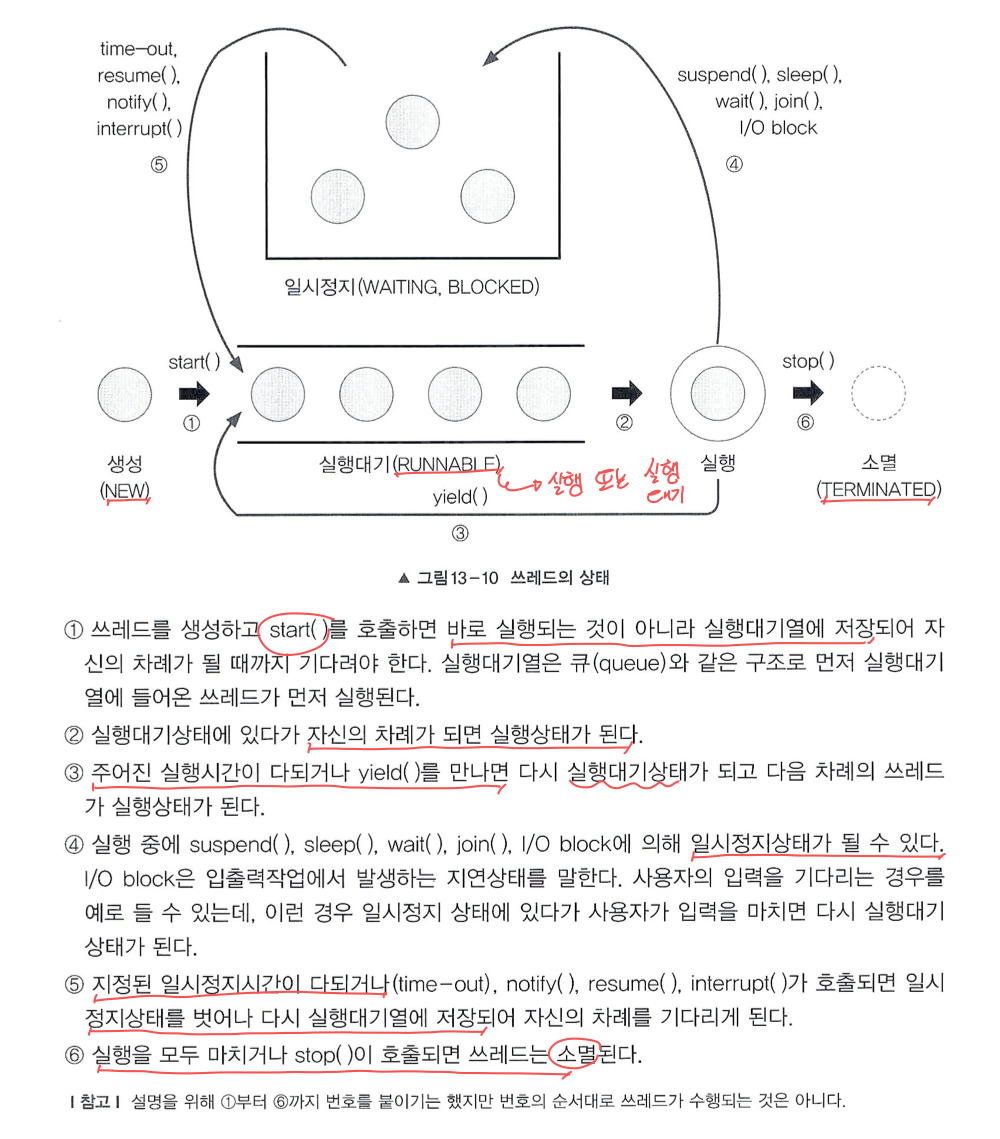
7️⃣ 쓰레드의 생명 주기 및 상태
쓰레드의 상태

쓰레드의 생명 주기
8️⃣ 쓰레드의 동기화
멀티 쓰레드 프로세스의 경우 여러 쓰레드가 같은 프로세스 내의 자원을 공유해서 작업하기 때문에 서로의 작업에 영향을 주게 된다.
위와 같은 일을 방지 하기 위해서 한 쓰레드가 특정 작업을 끝마치기 전까지 다른 쓰레드에 의해 방해받지 않도록 임계영역과 락을 도입할 수 있다.
공유 데이터를 사용하는 코드 영역을 임계 영역으로 지정해놓고, 공유 데이터(객체)가 가지고 있는 lock을 획득한 단 하나의 쓰레드만 이 영역 내의 코드를 수행할 수 있게 한다.
해당 쓰레드가 임계 영역 내의 모든 코드를 수행하고, 벗어나서 lock을 반납해야만 다른 쓰레드가 반납된 lock을 획득하여 임계 영역의 코드를 수행할 수 있게 된다.
이처럼 한 쓰레드가 진행 중인 작업을 다른 쓰레드가 간섭하지 못하도록 막는 것을 ‘쓰레드의 동기화’라고 한다.
9️⃣ Syncronized를 이용한 동기화
먼저 가장 간단한 동기화 방법인 Syncronized 키워드를 이용한 동기화는 임계영역을 설정하는데 사용된다.
public class Sync {
// 메서드 전체를 임계 영역으로 지정
public synchronized void countPoints() {
}
}쓰레드는 synchronized 메서드가 호출된 시점부터 해당 메서드가 포함된 객체의 lock을 얻어 작업을 수행하다가 메서드가 종료되면 lock을 반환한다.
synchronized 를 통해서 메서드 내의 코드 일부를 임계영역으로 지정하는 방법도 존재한다.
public class Sync {
public void countPoints() {
// 특정한 영역을 임계 영역으로 지정
synchronized (this){
}
}
}이 때 synchronized 인자에는 락을 걸고자 하는 객체를 참조해야 한다.
이 블럭의 영역 안으로 들어가면서부터 쓰레드는 지정된 객체의 lock을 얻게 되고, 이 블럭을 벗어나면 lock을 반납한다.
모든 객체는 lock을 하나씩 가지고 있으며, 해당 객체의 lock을 가지고 있는 쓰레드만 임계 영역의 코드를 수행할 수 있다.
- 다른 쓰레드들은 lock을 얻을 때까지 기다리게 된다.
임계 영역은 멀티쓰레드 프로그램의 성능을 좌우하기에 가능하면 메서드 전체에 락을 거는 것보다 synchronized 블록으로 임계 영역을 최소화해서 보다 효율적인 프로그램이 되도록 노력해야한다.
synchronized로 동기화해서 공유 데이터를 보호하는 것까지는 좋은데, 특정 쓰레드가 객체의 락을 가진 상태로 오랜 시간을 보내지 않도록 하는 것이 중요하다.
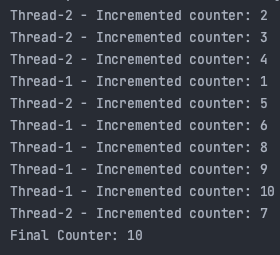
🤣 직접 테스팅 해보자.
Main.java
public class Main {
public static void main(String[] args) {
SharedResource sharedResource = new SharedResource();
// 여러 쓰레드가 같은 SharedResource에 접근
Thread thread1 = new Thread(new ThreadEx(sharedResource), "Thread-1");
Thread thread2 = new Thread(new ThreadEx(sharedResource), "Thread-2");
thread1.start();
thread2.start();
try {
// 모든 쓰레드의 실행이 끝날 때까지 대기
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 최종 결과 출력
System.out.println("Final Counter: " + sharedResource.getCounter());
}
}ThreadEx.java
public class ThreadEx implements Runnable{
private SharedResource sharedResource;
public ThreadEx(SharedResource sharedResource) {
this.sharedResource = sharedResource;
}
@Override
public void run() {
for (int i = 0; i < 5; i++) {
sharedResource.increment();
}
}
}SharedResource.java
class SharedResource {
private int counter = 0;
// synchronized 키워드를 사용하여 메서드를 동기화
public synchronized void increment() {
counter++;
System.out.println(Thread.currentThread().getName() + " - Incremented counter: " + counter);
}
public int getCounter() {
return counter;
}
}위 코드를 통해서 SharedResoure의 인스턴스 변수를 증가 시키기 위해서 Thread1과 Thread2가 접근을 하고, 경쟁을 한다. 그러나 public synchronized void increment() 를 통해서 먼저 들어온 쓰레드가 작업을 마칠 때까지 다른 쓰레드는 접근을 하지 못하게 락을 걸어준다.
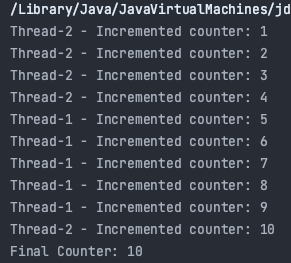
Thread1이 먼저 start() 했음에도 Thread2가 먼저 실행된 이유는 바로 OS의 스케쥴러에 의해서 이 순서가 변경되기 때문이다.
만약 Lock을 풀게 된다면(synchronized 키워드를 삭제했다면) 아래와 같은 결과가 출력된다.