Train.cpp
-
line #94. Optimization functions
-
line #97.
double BEETA1= 0.9, BETA2=0.9;
: SGD의 기본 값(?) -
line #98.
double SGD(double gradient, double learning_rate);
: SGD에 부여되는 paramers(gradient, leaning_rate) -
line #99.
double Momentum(double gradient, double learning_rate, double momentumPrev, double GAMA=0.3);
: Momentum optimizer에 부여되는 parameters(gradient, learing_rate, momentumPrev, GAMA) -
lime #100.
double Adagrad(double gradient, double learning_rate, double gradSquare, double EPSILON=1E-2);
: Adagrad optimizer에 부여되는 parameters(gradient, learning_rate, gradSquare, EPSILON) -
line #101.
double RMSprop(double gradient, double learning_rate, double gradSquarePrev,double GAMA=0.9, double EPSILON=1E-5);
: RMS optimizer에 부여되는 parameters(gradient, learning_rate, gradSquarePrev, GAMA, EPSILON) -
line #102.
double Adam(double gradient, double learning_rate, double momentumPreV, double velocityPrev, double epoch,double BETA1=0.9, double BETA2=0.999, double EPSILON=1E-8);
: Adam optimizer에 부여되는 parameters(gradient, learning_rate, momentumPreV, velocityPrev, epoch, BETA, BETA, EPSILON)
(여러 설정에 따라 다르지만) 최적의 값은
BETA1=0.9 (default value=0.9)
BETA2=0.999 (default value=0.9)
EPSILON=1E-8 (default value=1E-5) -
line #121~1199.
int train_batchsize = param -> numTrainImagesPerBatch; -
line #1201~1203.
double SGD(double gradient, double learning_rate){ }
: SGD 계산 식
https://twinw.tistory.com/247
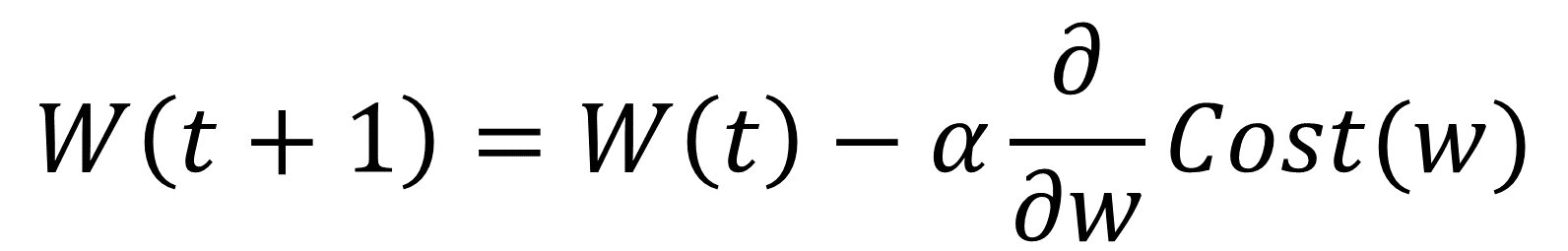
-
line #1205~1209.
double Momentum(double gradient, double learning_rate, double momentumPrev, double GAMA){ }
:Momentum optimizer 계산 식
(수식 image) -
line #1211~1213.
double Adagrad(double gradient, double learning_rate, double gradSquare, double EPSILON){ }
:Adagrad optimizer 계산 식
(수식 image) -
line #1215~1219.
double RMSprop(double gradient, double learning_rate, double gradSquarePrev,double GAMA, double EPSILON){ }
:RMSprop optimizer 계산 식
(수식 image) -
line #1221~1228.
double Adam(double gradient, double learning_rate, double momentumPrev, double velocityPrev, double epoch,double BETA1, double BETA2, double EPSILON){ }
:Adam optimizer 계산 식
(수식 image) -
line #. ``
-
line #. ``
-
line #. ``
