Generator의 개념과 사용법
파이썬 함수용어들은 상당히 직관적이다. Iterator와 마찬가지로 Generator 역시 단어의 의미로부터 그 개념을 손쉽게 유추할 수 있다. Generator : '발생시키는것', 무엇을? : Iterator(생성자)다. Generator는 Iterator를 발생시켜주는 함수다.
좀 더 자세히 살펴보자. 다음은 PythonDocs에서 발췌한 Generator에 대한 정의이다.
Generator
A function which returns an iterator. It looks like a normal function except that it contains yield statements for producing a series of values usable in a for-loop or that can be retrieved one at a time with the next() function. Each yield temporarily suspends processing, remembering the location execution state (including local variables and pending try-statements). When the generator resumes, it picks-up where it left-off (in contrast to functions which start fresh on every invocation).
제너레이터는 생성자를 발생시켜주는 함수입니다. 이것은 Yield구문이라는 for반복문과 next함수에 사용가능한 구문을 가지고있습니다. 각각의 yield값들은 일시적으로 함수의 진행을 지연시킵니다. 또한 이전에 진행되었던 함수의 단계를 기억합니다. 그러므로 제너레이터가 다시 재개됬을 때 yield값들은 멈췄던 순간부터 다시 진행되게됩니다.(이것은 대부분의 함수들이 실행때마다 초기값으로 실행되는것과 대비됩니다)
yield는 generator가 일반 함수와 구분되는 가장 핵심적인 부분이다. yield를 사용함으로써 어떤 차이가 있게 되는지 살펴보자.
먼저, 일반적인 함수의 경우를 생각해보자.
일반적인 함수는 사용이 종료되면 결과값을 <호출부>로 반환 후 함수 자체를 종료시킨 후 메모리 상에서
클리어 된다. (실행 -> 결과값 생성 -> 호출부로 반환 -> 종료)
하지만 yield를 사용할 경우는 다르다.
generator 함수가 실행 중 yield를 만날 경우, 해당 함수는 그 상태로 정지되며, 반환 값을 next()를 호출한 쪽으로 전달 하게 된다. 이후 해당 함수는 일반적인 경우 처럼 종료되는 것이 아니라 그 상태로 유지되게 된다. 즉, 함수에서 사용된 local 변수나 instruction pointer 등과 같은 함수 내부에서 사용된 데이터들이 메모리에 그대로 유지되는 것이다.
(실행 -> 결과값 생성-> next()를 호출한쪽으로 '전달' -> 일시정지)
예시를 보자
def generator(n): i = 0 while i < n : yield i i += 1 for x in generator(5): print(x)
위 구문을 하나하나 살펴보자.
- for 문이 실행되며, 먼저 generator 함수가 호출된다.
- generator 함수는 일반 함수와 동일한 절차로 실행된다.
- 실행 중 while문 안에서 yield를 만나게 된다. 그러면 return 과 비슷하게 함수를 호출했던 구문으로 반환하게 된다. 여기서는 첫 번째 i값인 0을 반환하게 된다. 그러나 반환 하였다고 generator 함수가 종료되는 것이 아니라 그대로 유지한 상태이다.
- x 값에는 yield에서 전달 된 0 값이 저장된 후 print 된다. 그 후 for문에 의해 다시 generator 함수가 호출된다.
- 이때는 generator 함수가 처음부터 시작되는게 아니라 yield 이후 구문부터 시작되게 된다. 따라서 i += 1 구문이 실행되고 i 값은 1이 증가하게 된다.
- 아직 while문 내부이기 때문에 i 값인 1이 전달 된다.
- x 값은 1을 전달 받고 print된다.

또한 generator expression이라는 표현이 존재한다. list comprehension가 비슷하지만, []대신 ()를 사용하면 된다.
[i for i x range(1,10) if i % 2 == 1] : list comprehension
(i for i x range(1,10) if i % 2 == 1) : generator expression
Generator 대체 왜 쓸까?
그렇다면 Generator를 사용했을 때 어떤 점이 유용하길래 우리는 Generator를 쓰는 걸까? 먼저, Memory를 효율적으로 사용할 수 있다.
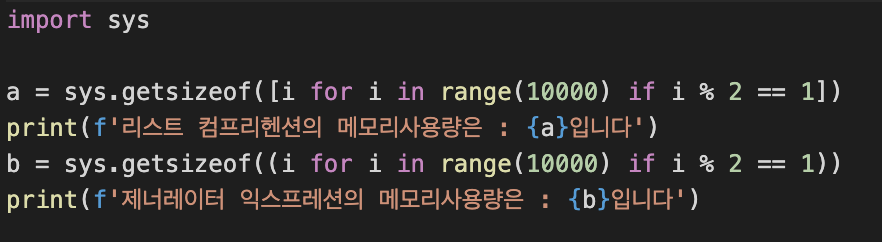
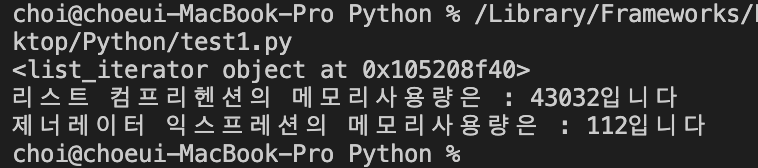
list의 경우 사이즈가 커질수록 메모리 사용량이 늘어나게 된다. 하지만 generator의 경우는 사이즈가 커진다해도 차지하는 메모리 사이즈는 동일하다. 이는 list와 generator의 동작방식의 차이에서 기인한다.
list 는 list 안에 속한 모든 데이터를 메모리에 적재하기 때문에 list의 크기 만큼 차지하는 메모리 사이즈가 늘어나게 된다. 하지만 generator 의 경우 데이터 값을 한꺼번에 메모리에 적재 하는 것이 아니라 next() 메소드를 통해 차례로 값에 접근할 때마다 메모리에 적재하는 방식이다. 따라서 list 의 규모가 큰 값을 다룰 수록 generator의 효율성은 더욱 높아지게 된다.
둘째로, Lazy evaluation 즉 계산결과 값이 필요할 때까지 계산을 늦추는 효과를 볼 수 있다.
import time import random counter = random.randrange(1, 11) # 1부터 10사이의 랜덤 값 생성 print("counter: {}".format(counter)) def return_one_after_five_sec(): print("please wait for 5 seconds") time.sleep(5) print("return 1") return 1 print("[let's make one_list !]") one_list = [return_one_after_five_sec() for x in range(10)] # counter 숫자만큼 값 출력 print("[let's print one_list !]") for item in one_list: counter -= 1 print(item) if counter == 0: break

다음의 코드는 5초를 대기했다가 1을 반환하는 예제이다. 그리고 전부 반환하지 않고, 1부터 10까지 랜덤의 횟수 만큼만 반환한다. 위의 예시에서 쓰인 list comprehension은 one_list라는 리스트에 무조건 10까지 담은 후 카운터숫자(1~10 중에 하나)만큼 프린트를 해주게 된다. print counter가 1이 뜨더라도10개의 요소를 채울때까지 50초의 return시간을 기다려야 한다.
하지만 one_list = (return_one_after_five_sec() for x in range(10)) #generator 형태로 바꿔주게 되면 이야기는 달라진다.

보다싶이 generator는 미리 값을 만들어 놓지 않는다. one_generator값을 사용하는 순간에만 함수를 수행하고 있다. 즉 값이 실제로 사용되지 않으면 연산 또한 하지 않으므로 시간과 메모리를 절약할 수 있게된다. 이것이 바로 Lazy evaluation(게으른 계산)이다. 때론 미리미리 끝내놓고 그때그때마다 해치우는게 더 효율적일때가 있는 것이다.
Assignments
1번 문제:
결과값 : 1, 4, 9
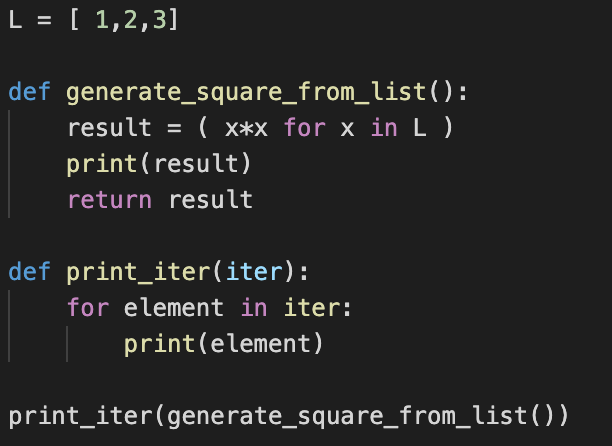
해석 : generation expression을 사용한 구문이다. for구문(generator_square_from_list)이 실행되며 generator 함수가 호출된다. 첫 번째 result 값이 1이 리턴되고 이는 iter함수로 전달된다. 그 후 for문에 의해 다시 한번 generator 함수가 호출되며 동작을 멈춘 구간부터 다시 시작, 두 번째 result값인 22= 4 가 리턴->전달, 마지막으로 한번 더 반복되고 33 값이 리턴->전달 되며 종료된다.
2번 문제 :
L = [1, 2, 3]
결과값 :
list comprehension : sleep1s sleep1s sleep1s 1 2 3
Generator expression : sleep1s 1 sleep1s 2 sleep1s 3
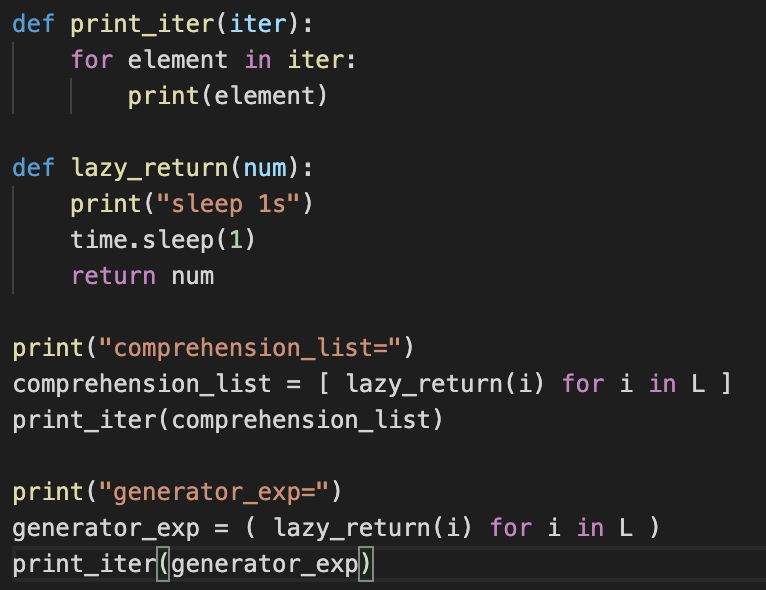
해석 : li_co의 경우 우선 리스트를 만들어야 하므로 lazy_return 함수를 3번 실행, num값을 3번 리턴해 리스트를 생성한다. 그 이후 comprehension_list를 실행해 print_iter로 보내줘 1,2,3을 반환한다. ge_exp의 경우 generator_exp 함수를 실행할때만 lazy_return 함수를 실행한다. 그러므로 lazy_return-> 반환이 세 번 반복되게 된다.
