서론
멘토님들이 Project Kickoff(시작) 전에 하시던 말씀이 있다.
"앞으로 프로젝트 시작하시면 Velog작성이 더 어려우실거예요"
틀린말 하나 없었다. 개인으로 개발공부를 하는것도 팀으로서 프로젝트를 진행하는것은 분명히 차이가 존재한다. 개인 개발공부는 온연하게 자신에게만 집중하면 된다. 공부방식도, 쉬는시간도, 벨로그 작성도 말이다. 게으름을 피우면 그 대가는 온전히 자기만 받으면 된다.
하지만 프로젝트를 진행하며 게으름을 피운다는것은 팀 전체에게 데미지를 주는 행위가 될 수 있다. 여기에서 큰 차이가 발생한다. 이런 관점에서 배려는 책임감으로 바뀌고, 책임감은 행동의 변화를 이끌어낸다. 벨로그 작성할 여유가 없어지게 된다. 하지만 정리를 하고 안 하고는 학습에 있어서 꽤나 큰 차이를 낸다. 내가 지금 알고있다고 믿는 것들이 3일 후, 일주일 후에도 알고 있다고 확신할 수 있을까? 인간의 뇌는 ROM보다는 REM에 가깝다. Velog라는 DB storage에 때려넣어줘야 나중에 색인이라도 할 수 있다.
그렇기에 최대한 팀 프로젝트에 지장이 가지않는 한도 내 시간을 쪼개 이렇게 벨로그를 작성할까 한다. 기존의 TIL과 달리 프로젝트 기간에는 '개발로그'와 'TIL'을 조금 나눠볼까 한다.
개발로그를 통해 프로젝트 기간동안에 진행한 사항을 돌아보며, 복습과 느낀점을 정리한다면, 'TIL'을 통해 프로젝트 기간 내에도 진행되는 세션과 프로젝트에서 배운 새로운 점들을 정리해나갈까 한다.
개발로그
- Project DAY 01
팀이 결정되었다. 팀 인원은 보통 5~6명으로 구성되는데 우리 팀 같은 경우는 5명(프론트 3, 백엔드 2)로 구성되었다. 7개의 팀 전원에서 백엔드는 무조건 2명씩 참여하게 되기 때문에 정말 진득하게 소통하게 될 백엔드 메이트가 궁금했는데 평소 꽤나 편하게 지내던 L양으로 결정되서 출발이 좀 산뜻한 느낌이였다.
뭐 백엔드 전원이랑 친하기 때문에 사실 누가되든 상관이 없긴 했지만, 그래도 개중에 더 편한 사람이 있는것은 사실이다.
제시된 다양한 웹페이지 아이디어 중에 우리의 과제로 선정된 것은 SpaceX였다. 이 역시 평소에 좋아하던 엘론머스크와 관련된 회사 홈페이지 이므로 맘에 들었다. 다만 홈페이지의 비중이 화려한 사진으로 구성된 레이아웃과 모션에 힘을 많이 쓴 느낌이라, 백엔드 입장에서는 구현할 사항이 적은게 한편으론 다행이라고 느끼면서, 아쉬운 맘이 동시에 들었다.
Trello라는 프로젝트에 최적화된 웹을 이용해 프로젝트를 진행했다. 트렐로는 Backlog(프로젝트 기간 동안 앞으로 수행해야 할 업무를 전부 모아놓은 항목) Sprint('이번주'에 업무를 모아놓은 항목) In progress(지금 시점에서 하고있는 업무를 모아놓은 항목) Done(끝낸 업무를 모아놓은 항목)으로 나눠지고 업무를 끝낼 때 마다 한 단계씩 푸싱하는 식으로 진행한다.
첫째 날엔 Backlog에 할 일을 모두 적어보고, 이후에 멘토님들과 피드백을 통해 양을 줄이거나 할일을 바꾸는 식으로 수정작업이 이뤄졌다. 2주라는 한정된 기간에 최대한 가능한 업무량을 주기 위한 멘토님들의 배려인것 같았다. 프로젝트 과제를 최종적으로 정한 후에는 홈페이지 데이터모델링을 진행했다.
Aquery를 통해 테이블을 그렸는데, 처음에는 Mainpage와 Shoppage를 전부 모델링하려했으나, 대부분이 이미지파일이고 카테고리화 하기 어려운 메인페이지는 멘토님들과의 상의를 통해, 모델링을 진행하지 않는 것으로 결정했다.
- Project Day 02
프로젝트 두 번째날엔 팀 별로 구현한 모델링을 피드백 받았다.
모든 팀들의 백엔드들이 모여 진행한 피드백 세션이여서 다양한 모델링 모델들을 볼 수 있어 흥미진진한 시간이였다.
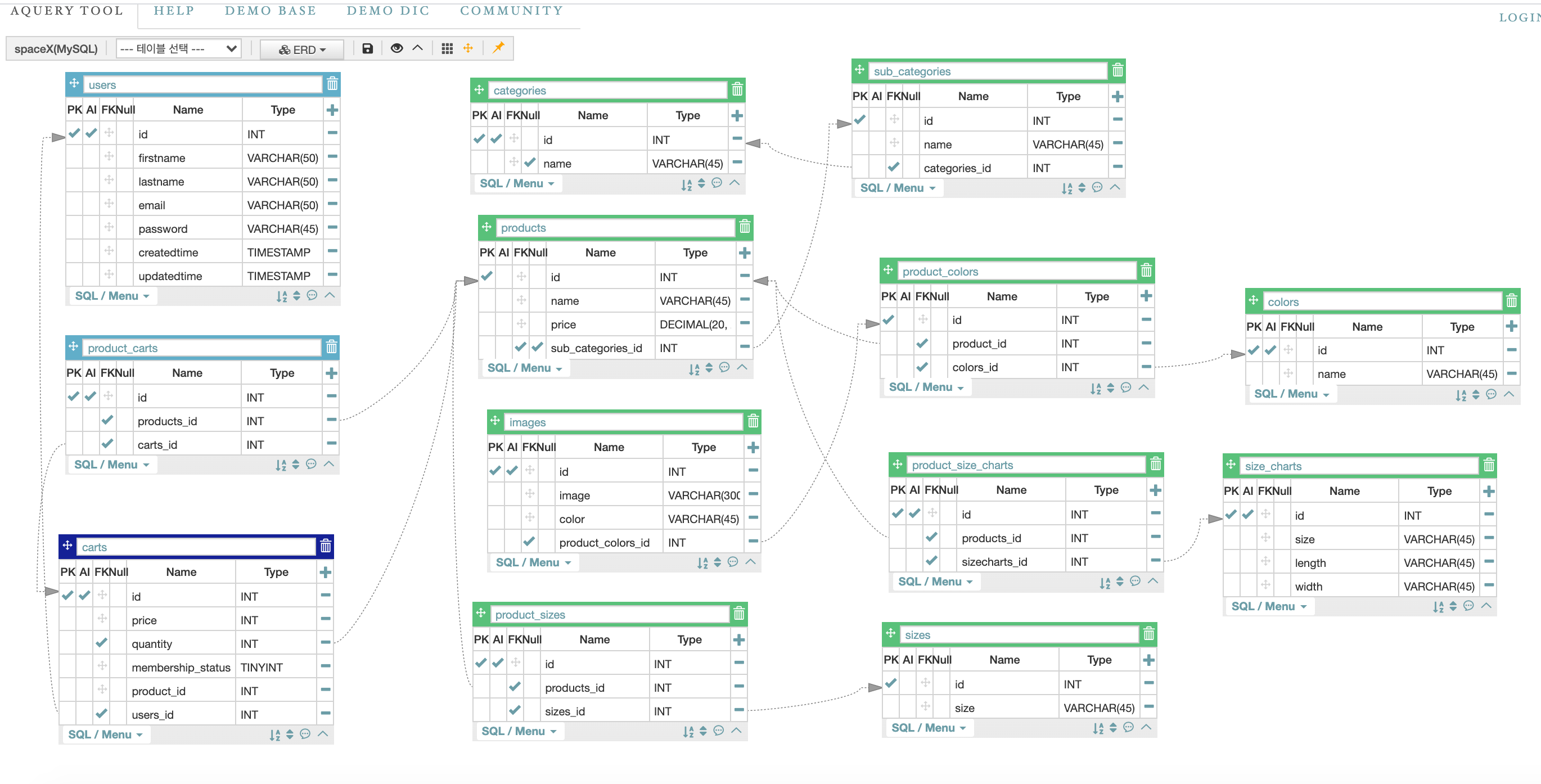
스페이스X는 모델링을 할 항목이 적어 타 팀보다는 테이블 갯수가 많지는 않아서 비교적 수월하게 진행했고, 피드백도 크게 수정할 사항이 많지 않았다. 제품과 제품색깔은 Many to Many Field로 join을 했었는데 이미지 파일의 경우 색깔을 기준으로 첨부되므로 Product에 Many to one으로 join시키는게 아니라 제품과 제품색깔의 중간테이블에 연결하는 식으로 모델을 수정했다.
제품마다 Size chart와 Size가 따로 분류되어있고, 들어있는 데이터의 형식이나 종류, 개수가 다르므로 테이블을 따로 나눠 분류했는데 이점은 멘토님에게 칭찬을 받았다.
이외에 모델링에 관한 새롭게 배우게 된 점이 피드백세션에 많이 있었는데 이는 따로 후술할 예정이다.
피드백 시간 이후에는 모델링한 항목에 맞춰 웹 크롤링 코드를 짜기 시작했다. 왠지 모르겠지만 list comprehension과 for loof과 굉장히 많은 python code가 짜여지고 있었다.
- Project Day 03
전 날에 이어 크롤링을 이어 진행했다. 스타벅스때 썼던 방식으로 상세페이지 url주소의 구조를 파악해서 url의 후측의 공통점을 통해 한 페이지씩 타고 들어가 BS4로 html을 파싱하는 방식으로 크롤링을 구현했다.
웹 크롤링 코드를 짜면서 공부만 했던 다양한 파이썬 기법을 쓰게 되었던 것 같다.
우선 list comprehension, 정규표현식, enumerate 등이 있다. csv 저장때는 항상 즐겨쓰는 라이브러리인 pandas를 써서 저장했다. 1차적으로 크롤링파일을 완성했고, 이후에 프론트엔드분들과 대화를 통해 리스트데이터를 2차원 리스트로 리스트안에 항목화 하는 식으로 프론트엔드에서 데이터 렌더링이 편하게끔 가공(refactoring)을 했다. 이것으로 크롤링을 끝마쳤다.

이 지저분한 하드코딩의 흔적을 보자.. 제일 애먹었던 사이즈차트를 크롤링하기 위한 코드다. inch 표시를 html상에서는 이것을 수정했고, 2차원 리스트를 만들기 위해 enumerate를 사용했다.
가끔씩 사이즈차트가 따로 없는 상품들이 있었는데(대체..왜?) 이는 Try, except를 통해 오류가 발생하면 None값을 리턴하는 식으로 해결했다.