정규화가 답일까?
최근 데이터모델링을 학습하면서 느낀점은 '데이터모델링'은 '정답'이 정해지지 않은 학문인 것 같다는 점이다. 이론적으로 데이터모델링에서 가장 중요한 요점은 물론 '무결성'이다.
무결성 확보를 위해서는 '중복'을 최대한 제거하는것이 중요하며, 이를 위한 정규화가 이론적으로는 많이 실행할수록 무결성 확보가 쉬워진다.
하지만 이는 '성능'적인 측면에서는 완전히 틀린 방법이 되어버린다.
정규화가 진행되어 분리되는 테이블 수가 많아질수록 데이터의 조회를 위한 쿼리실행시 이에 비례해 시간이 증가하게 되고, 한눈에 데이터를 참조하기가 어려워진다.
그러므로 데이터모델링을 실행할때는 '상황'과 '목적'에 맞는 '최적의 답'을 구하는게 옳은 방법이며, '정답'이 정해지지 않음을 항상 생각하는게 중요하다.
내역과 이력
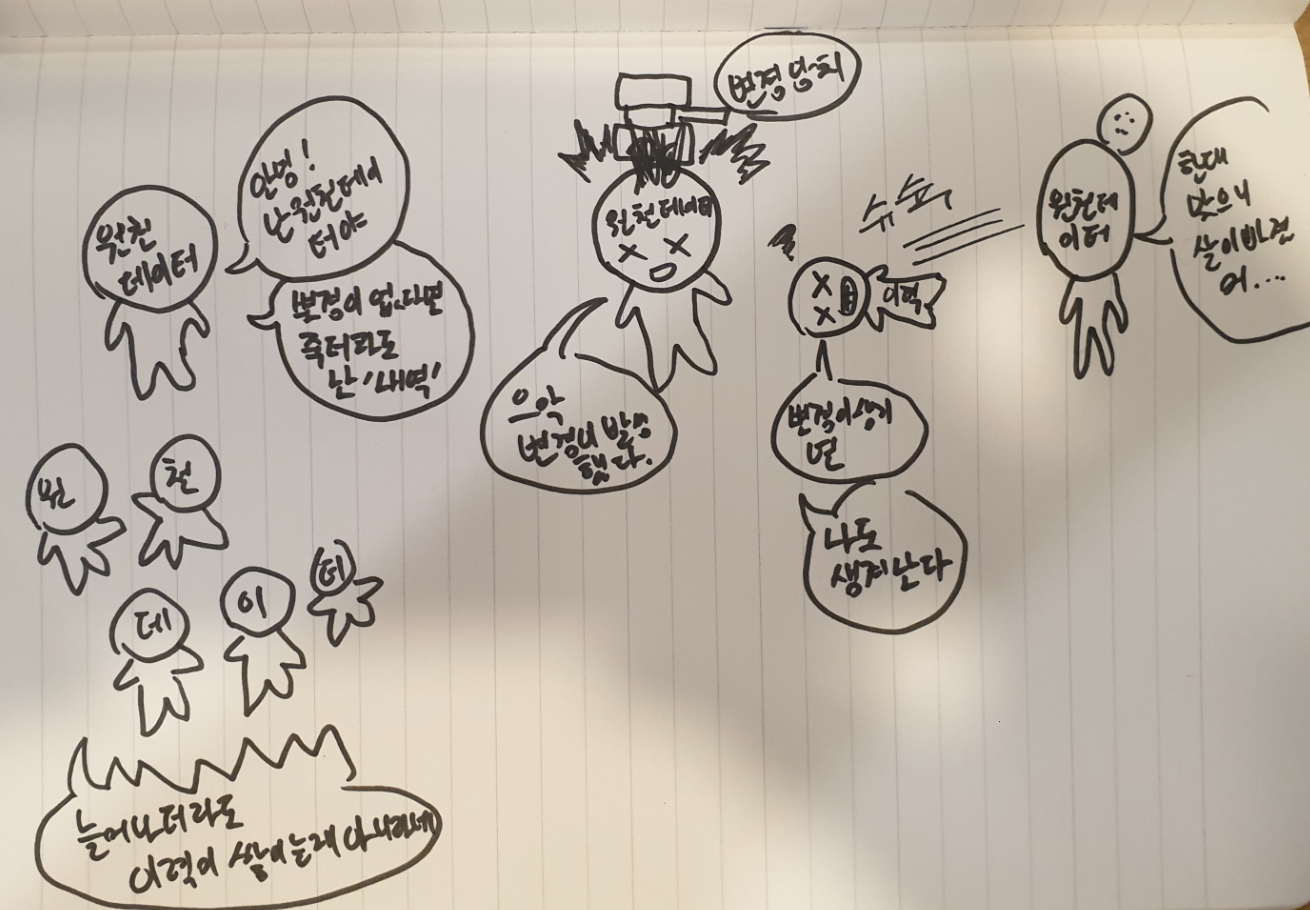
이번에 브랜디라는 이커머스 사이트를 대상으로 데이터모델링을 진행하면서 느낀점은 '이력관리'가 필요한 데이터가 생각보다 많다는 점이다. 그리고 내가 이전에 '이력'이라고 생각했던 개념이 이력이 아닌 '내역'이였던 경우가 많았다.
그래서 '내역'이랑 '이력'이 뭐라구?
간단하게 정의하자면 '내역'이란 '생성'되고 '쌓여진'데이터다.
우리가 지금 쿠팡사이트에 가서 회원정보를 보면 회원정보를 변경하지 않았다면, 가입할 당시에 쓰였던 전화번호나 주소같은 기초정보들이 그대로 남아서 보이게 될 것이다.
바로 이게 '내역'이다.
쿠팡 어드민페이지에 연결된 DB에는 나라는 유저말고도 수십만명의 형성된 유저데이터가 쌓여있다. 이것들 하나하나가 모두 내역이 된다. 특정한 이유로 유저가 웹페이지에서 회원탈퇴를 하더라도 DB에서는 데이터를 그대로 삭제하지않고 soft delete로 삭제처리를 해두고 그대로 보존해놓은 경우도 있는데 이 경우 데이터는 실제로 사용되지않은 '죽은데이터'로서 DB에 존재하지만 여전히 내역이다.
왜냐면 '생성되었고 지워졌으나' '변경 되어지지 않았기'때문이다.
반면에 '이력'의 경우는 한가지 요인이 무조건 존재해야 성립이된다. 데이터 수정(update)이 발생해야한다.
만약 내가 전화번호가 바뀌어 쿠팡에 있는 회원정보에서 전화번호를 010-0000-0001에서 010-0000-0002로 바꿨다고 가정하자.
이때, 회원정보를 누르면 당연히 내가 바꾼 전화번호인 010-0000-0002가 포함된 유저정보데이터가 내역으로서 출력 될 것이다.
그렇다면 기존의 전화번호인 010-0000-0001은 어떻게 될까?
나도 이력이란 개념을 알기전까지는 그냥 데이터는 업데이트 하는순간 기존데이터는 증발하는 알콜처럼 모두 없어지거나 혹은 그대로 로우(행)하나가 테이블내에서 추가되는줄 알았는데 그게 아니였다.
기존의 전화번호인 010-0000-0001이 포함된 유저정보는 없어지거나 유저정보테이블에 쌓여있는게 아니라 '이력관리용 테이블'에 '이력'으로서 남게된다.(이는 스키마구조에 따라 다르지만 전체 유저정보 중 하나라도 변경하면 유저정보 전체가 이력으로 남는 방식이라고 가정하자)
즉 원천데이터가 '변경'될 경우, '이력관리전용 테이블'에 생겨난 '죽은데이터' 이것이 바로 '이력'이다.
