
referenc: https://cs231n.github.io/classification/ - 2022/11/5
Image Classification(이미지 분류):
입력 이미지를 미리 정해진 카테고리 중 하나인 label(라벨)로 분류하는 문제다. 컴퓨터 비전 분야의 핵심적인 문제 중 하나이다.
The problem: semantic gap(의미적 차이)
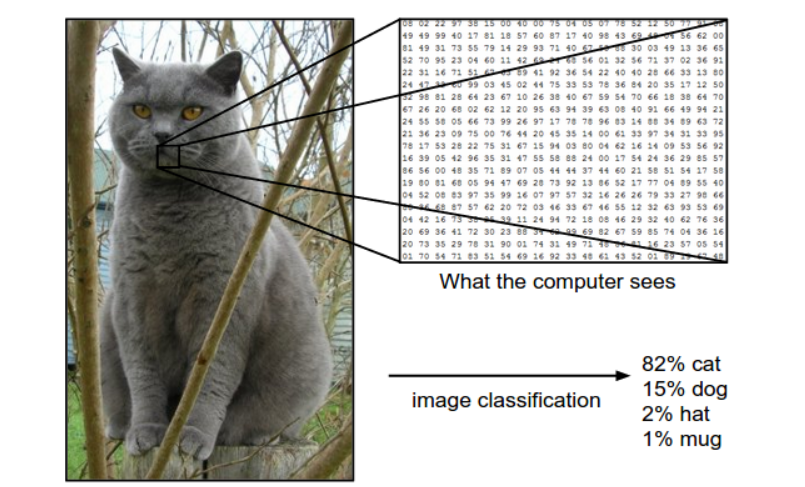
이미지는 숫자로 구성된 3D array로 구성된다. 예를 들어 300 x 100 x 3의 배열은 Width(너비) 300픽셀, Height(높이) 100픽셀, 3개의 Channel들로 이루어진다. Channel은 주로 색상으로 Red, Green, Blue(RGB) 3개의 색상 채널을 사용한다.
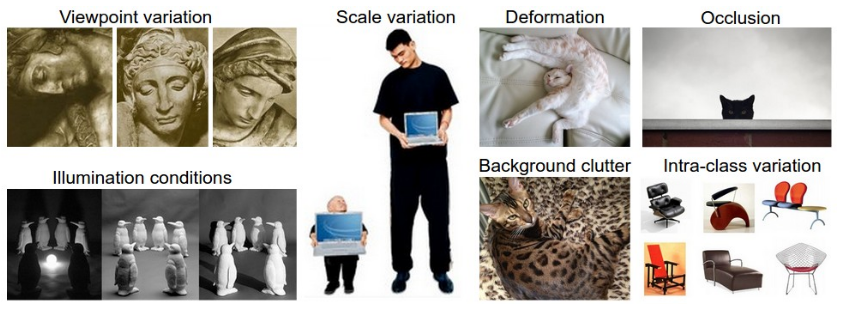
따라서, 직관으로 사물을 인식하는 사람과 달리 숫자들로 표현된 이미지를 인식하는 컴퓨터는 해결해야하는 문제들이 발생한다.
- Viewpoint Variation(시점 변화):
- Illumination conditions(조명)
- Deformation(변형)
- Occlusion(폐색)
- Background clutter(배경 분규)
- Intraclass variation(내부클래스의 다양성)
- Scale variation(크기 변화)
Data-driven approach(데이버 기반 방법론)
def predict(image):
# ????
return class_label이미지 분류 알고리즘을 프로그래밍할 때, 위와 같이 정해진 하드 코딩으로 알고리즘을 만들어내는 것은 쉽지 않다.
그래서 고안된 방법이 data-driven approach(데이터 기반 방법론) 이다. 이 방법은 먼저 컴퓨터에게 각 클래스에 대한 많은 예제를 주고 나서 이 예제를 보고 시각적으로 학습할 수 있는 학습 알고리즘을 개발하는 것이다.
def train(train_images, train_labels):
# build a model for images -> labels...
return model
def predict(model, test_images):
# predict test_labels using the model...
return test_labels데이터 기반 방법론을 활용한 image classification은 다음과 같은 과정으로 이루어진다.
- Input 이미지와 라벨로 구성된 데이터셋을 수집한다.
- Learning 수집한 데이터셋을 통한 머신러닝을 통해 image classifier를 학습시킨다.
- Evaluation 테스트 이미지들을 활용해 classifier의 성능을 평가한다.
First classifier: Nearest Neighbor Classifier(최근접 이웃 분류기)
첫번째 방법은 Nearest Neighbor Classifier라는 분류기로 CNN과는 아무 상관이 없지만, 이미지 분류 문제에 대한 기본적인 접근 방법을 알 수 있도록 한다.
Nearest Neighbor Classifier는 모든 training image와 label을 기억하고 test image와 가장 비슷한 이미지의 label을 예상한다.
이미지 분류 데이터셋 예: CIFAR-10

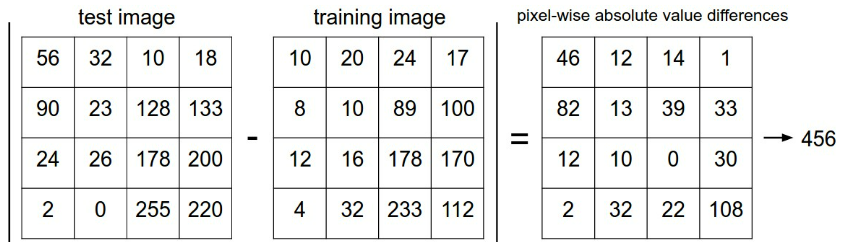
training image와 test image를 비교하는 방식으로는 이미지 array의 각각의 값을 비교하고, 그 차이를 모두 더하는 것이다. 즉, 이미지 간의 distance를 구하는 것이다.
L1 distance 구하는 방법:
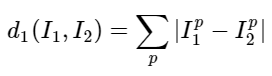
Nearest Neighbor Classifier 구현
실제 코드 상에서 어떻게 구현하는지 살펴보자.
CIFAR-10 데이터를 메모리로 불러와 4개의 배열에 저장한다. 각각은 학습(트레이닝) 데이터와 그 라벨, 테스트 데이터와 그 라벨이다. 아래 코드에 Xtr(크기 50,000 x 32 x 32 x 3)은 트레이닝 셋의 모든 이미지를 저장하고 1차원 배열인 Ytr(길이 50,000)은 트레이닝 데이터의 라벨(0부터 9까지)을 저장한다.
(Xtr, Ytr), (Xte, Yte) = cifar10.load_data() # 제공되는 함수 X는 (32*32*3)이미지 형식, y는 class index
# 모든 이미지가 1차원 배열로 저장된다.
# shape[0]은 행의 갯수 반환, reshape(x, y)은 x, y로 다시 재배열
Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3) # Xtr_rows는 50000 x 3072 크기의 배열.
Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3) # Xte_rows는 10000 x 3072 크기의 배열.
일반적으로 평가 기준으로서 accuracy(정확도) 를 사용한다. 앞으로 만들어볼 모든 분류기는 공통적인 API를 갖게 될 것이다: 데이터(X)와 데이터가 실제로 속하는 라벨(y)을 입력으로 받는 train(X,y) 형태의 함수가 있다는 점이다.
내부적으로, 이 함수는 라벨들을 활용하여 어떤 모델을 만들어야 하고, 그 값들이 데이터로부터 어떻게 예측될 수 있는지를 알아야 한다. 그 이후에는 새로운 데이터로 부터 라벨을 예측하는 predict(X) 형태의 함수가 있다. 물론, 아직까지는 실제 분류기 자체가 빠져있다. 다음은 앞의 형식을 만족하는 L1 거리를 이용한 간단한 최근접 이웃 분류기의 구현이다.
class NearestNeighbor(object):
def __init__(self):
pass
def train(self, X, y):
""" X is N x D where each row is an example. Y is 1-dimension of size N """
# nearest neighbor 분류기는 단순히 모든 학습 데이터를 기억해둔다.
self.Xtr = X
self.ytr = y
def predict(self, X):
""" X is N x D where each row is an example we wish to predict label for """
num_test = X.shape[0]
# 출력 type과 입력 type이 갖게 되도록 확인해준다.
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
# loop over all test rows
for i in range(num_test):
# i번째 테스트 이미지와 가장 가까운 학습 이미지를
# L1 거리(절대값 차의 총합)를 이용하여 찾는다.
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances) # 가장 작은 distance를 갖는 인덱스를 찾는다.
Ypred[i] = self.ytr[min_index] # 가장 가까운 이웃의 라벨로 예측
return Ypred거리(distance) 선택 벡터간의 거리를 계산하는 방법으로 기하학적으로 두 벡터간의 유클리디안 거리를 계산하는 것으로 해석할 수 있는 L2 distance(L2 거리)을 사용할 수 있다.
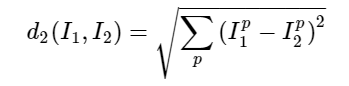
distances = np.sqrt(np.sum(np.square(self.Xtr - X[i,:]), axis = 1))위의 코드 한 줄만 바꾸면 된다.
k-Nearest Neighbor(kNN) Classifier
kNN은 학습 데이터셋에서 가장 가까운 하나의 이미지만 찾는 것이 아니라, 가장 가까준 k 개의 이미지를 찾아서 테스트 이미지의 라벨에 대해 투표하도록 하는 것이다. 여기서 k = 1 인 경우, 원래의 NN 분류기가 된다.

kNN classifier는 k를 정해줘야 한다. 앞서 우리는 여러 거리 함수(L1 norm, L2 norm etc..)를 살펴보았다. 이러한 선택들을 htperparameters 라 부르다. 이는 데이터로 학습하는 많은 기계학습 알고리즘 디자인에 등장한다.
하지만, 이 hyerparameter 값을 조정하기 위해 테스트 셋을 사용하면 절대 안된다. 그렇게 하지 않는다면, 모델이 테스트 셋에는 잘 동작하지만 실전 사용 시에 성능이 낮아질 수 있는 overfit 현상이 발생할 수 있다. 따라서 테스트 셋은 모델 성능을 평가하는 맨 마지막에 단 한번만 해야 한다.
hyperparameter 들을 튜닝하는 방법으론 트레이닝 셋에서 vaildation set(검증 셋)을 쪼개는 것이다. 예로, 학습 이미지 49000 장을 트레이닝 셋으로 나머지 1000장을 검증 용으로 남기는 것이다.
다른 방법으론 Cross-validation (교차 검증)이라는 튜닝 방법이 있다. 예를 들어 5-fold 교차 검증에서는 학습데이터를 5개의 동일한 크기의 그룹으로 쪼갠 뒤, 4개를 학습용으로, 1개를 검증용으로 사용한다. 그 다음에는 어떤 그룹을 검증 셋으로 사용할 지에 따라 반복하고, 성능을 평가하고 각 그룹에 대해 평가한 성능을 평균낸다.
Nearest Neigbor Classifier의 장단점
이 방법은 구현이 매우 간단하지만, 학습 데이터셋 전체를 메모리에 저장해야 하고, 새로운 테스트 이미지를 분류하고 평가할 때 계산량이 매우 많다. 마지막으로, 단순히 픽셀 값들의 L1이나 L2 거리는 이미지의 클래스보다 배경이나 이미지의 전체적인 색깔 분포 등에 더 큰 영향을 받기 때문에 이미지 분류 문제에 있어서 충분하지 못하다는 점을 보았다.
