1. 클라우드 데이터 조작 쿼리와 DB 객체
<학습 목표>
- 관계형 데이터베이스의 주요 객체에 대해서 이해한다.
- 관계형 데이터베이스를 다루기 위해서 필수적으로 알아야
하는 SQL Query에 대해서 이해한다.
1.1 관계형 데이터베이스의 주요 객체
관계형 데이터베이스는 데이터를 효율적으로 관리하기 위해 다양한 객체들을 사용합니다.
- 테이블(Table): 행과 열로 구성되며, 모든 행은 동일한 수의 열을 가집니다.
- 엔티티(Entity): 고객이나 제품과 같은 실제 항목 또는 주문과 같은 가상 항목을 나타내며, 관계로 연결됩니다.
- 정규화(Normalization): 데이터 중복을 방지하고 품질을 향상시키기 위해 데이터를 구조화하는 과정입니다.
- 관계(Relation): 기본 키(PK)와 외래 키(FK)를 사용하여 테이블 간의 연결을 정의합니다.
- 인덱스(Index): 데이터 검색을 최적화하여 읽어야 할 페이지 양을 줄이고 속도를 높입니다.
- 뷰(View): 쿼리 결과를 기반으로 하는 가상 테이블로, 복잡한 조인 쿼리를 단순화해 줍니다.
1.2 SQL(Structured Query Language)문의 유형
데이터베이스 구조와 데이터를 관리하기 위해 체계적인 SQL 구문을 사용합니다.
- DML (Data Manipulation Language): 데이터를 조작하며,
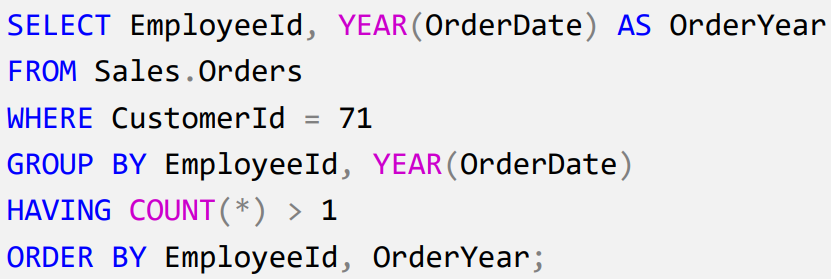
SELECT(선택/읽기),INSERT(삽입),UPDATE(편집/업데이트),DELETE(삭제)가 포함됩니다.
 |  |
|---|
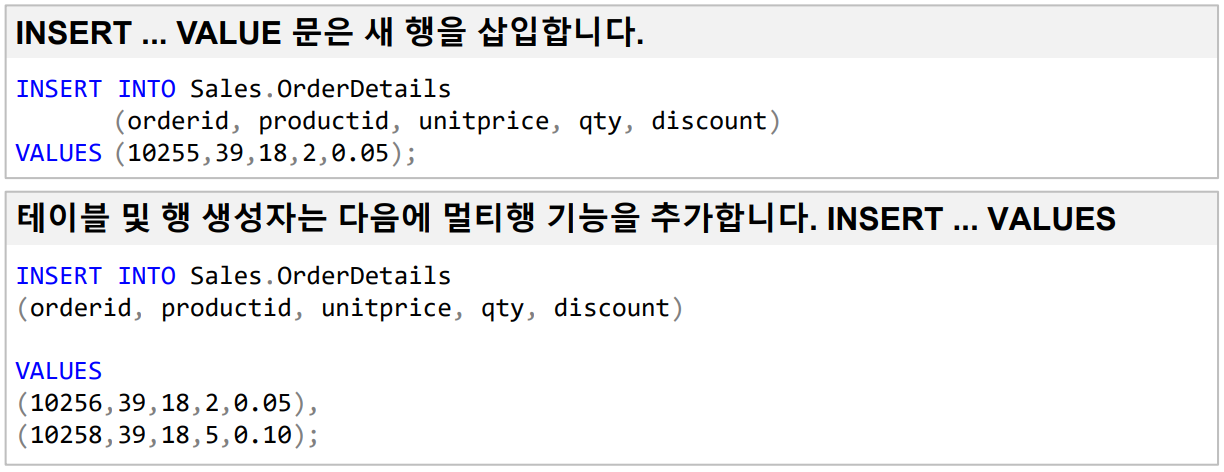
- DDL (Data Definition Language): 데이터베이스 구조를 관리하며,
CREATE(생성),ALTER(수정),DROP(제거),RENAME(이름 변경) 등이 있습니다.

2. 상용 클라우드의 데이터 플랫폼
<학습 목표>
- 클라우드에서 상용으로 제공되는 SQL Server에 대해서
살펴본다.- SQL Server가 용도별로 어떤 버전을 사용해야 하는지 그
차이에 대해서 이해한다.
2.1 Azure SQL 서비스 모델 비교
Azure는 요구사항에 따라 세 가지 주요 SQL 서비스를 제공합니다.

- Azure VM의 SQL Server (IaaS): 클라우드에서 SQL Server 정품을 사용하며, OS 업데이트와 백업 등 모든 관리를 고객이 직접 수행합니다.
- Azure SQL Database (PaaS): 관리 작업이 최소화된 저가형 옵션으로, 신규 클라우드 프로젝트나 가변적인 로드 대응에 적합합니다. 단일 DB 또는 리소스를 공유하는 탄력적 풀 형태로 배포 가능합니다.

- Azure SQL Managed Instance (PaaS): 온-프레미스 SQL Server와 거의 100% 호환되며 자동 패치와 백업을 지원하는 완전 관리형 서비스입니다.

2.2 인증 및 역할 기반 액세스 제어(RBAC)
- 인증: Azure AD(Active Directory) 인증과 SQL 로그인을 지원하며, 보안 주체를 통해 액세스를 요청합니다.
- RBAC: 보안 주체, 역할(권한 컬렉션), 범위(리소스 집합)의 세 가지 요소를 통해 사용자가 수행할 수 있는 작업을 관리합니다.
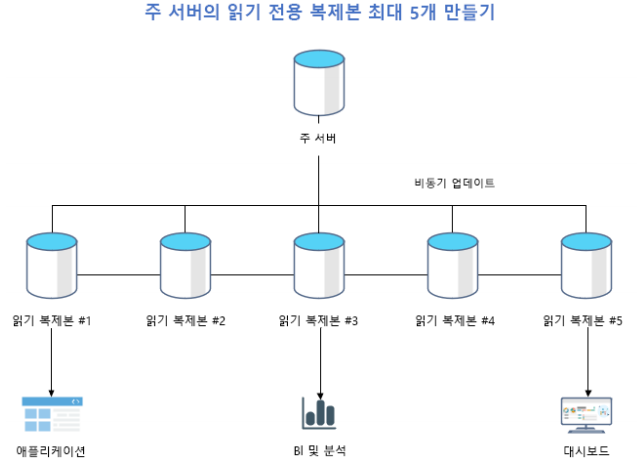
2.3 읽기 전용 복제본 (Read Replicas)
읽기 집약적인 워크로드의 성능을 개선하기 위해 최대 5개의 복제본을 만들 수 있습니다. 이는 BI 분석 성능 향상뿐만 아니라 다른 지역에 복제본을 생성하여 재해 복구(DR) 계획에도 활용됩니다.
3. 데이터 플랫폼 아키텍처 및 Python 실습
<학습 목표>
- 간단한 앱을 파이썬으로 개발해보고 MySQL과 연결하기 위한
요소들을 살펴보고 직접 코딩해 본다.
3.1 MySQL Connector 라이브러리 활용
Python에서 MySQL 데이터베이스에 연결하기 위해 Oracle에서 공식 지원하는 MySQL Connector 라이브러리를 사용했습니다.
import mysql.connector
cnx = mysql.connector.connect(
host="127.0.0.1",
port=3306,
user="root",
password="password",
database="database_name"
)
cursor = cnx.cursor()
cursor.execute("SELECT * FROM table_name")
results = cursor.fetchall()
cnx.close()<My sql Connector 라이브러리>
- 특징: 순수 Python으로 작성되어 추가 종속성이 없으며 사용이 간편합니다.
- 설치: 터미널에서
pip install mysql-connector-python명령어로 설치합니다.
3.2 실습: Python 기반 데이터베이스 연동
실제 코드에서는 다음과 같은 흐름으로 데이터를 처리합니다.
1. mysql.connector.connect()를 통해 호스트, 사용자, 비밀번호 정보를 입력하여 DB에 연결합니다.
2. cursor()를 생성하고 execute() 메서드로 SQL 쿼리를 실행합니다.
3. fetchall()로 결과를 가져온 후 close()를 통해 연결을 해제합니다.
4. 학습 소감 및 결론
4주차 수업을 통해 관계형 데이터베이스의 이론적 구조부터 클라우드 서비스 모델의 실질적인 차이점까지 폭넓게 배울 수 있었습니다. 특히 SQL이 단순히 데이터를 조회하는 것을 넘어 DB 객체의 구조까지 관리하는 강력한 도구임을 다시금 확인했습니다.
또한, 실습을 통해 Python 코드로 MySQL과 통신해 보며, 개발자가 클라우드 환경에서 데이터를 조작하기 위해 어떤 라이브러리와 아키텍처를 선택해야 하는지 체감할 수 있었습니다.
다음 시간에는 유연한 데이터 처리를 가능케 하는 클라우드 기반의 NoSQL에 대해 학습해 보겠습니다!
