
개요
Java, Spring으로 백엔드를 구성하면 데이터베이스를 다룰 일이 있을 것입니다.
저의 주변에선 주로 JPA나 Mybatis를 이용해서 데이터를 다루는 것을 확인했습니다.
저 역시 일반적으로는 JPA와 QueryDSL과 같은 기술들을 이용하지만 특정 상황에서 성능이 너무 떨어진다면 JdbcTemplate이나 Mybatis를 고려하게 되는 일들이 있었습니다.
이번 포스팅에서는 이처럼 다양한 DB 접근 방법 중 insert를 하는 방법에 대해서 알아보고, 각 방법의 성능을 비교해 보도록 하겠습니다.
Insert를 하는 다양한 방법
기본적으로 Java에서 DB에 접근하기 위해선 JDBC를 이용해야 합니다. 하지만 직접 JDBC를 이용해서 DB를 조작하는 것은 여러 반복 코드가 발생하고, 커넥션 관리 등 신경 써줘야 할 문제들이 많습니다. 그래서 백엔드 개발을 할 때엔 JDBC를 직접 사용하지 않습니다. 트랜잭션, 커넥션 관리 등은 스프링이 처리해 주고, 쿼리를 작성하는 것은 위에서 작성한 여러 라이브러리인 JPA, Mybatis, JdbcTemplate 등을 이용합니다. 각 방법에서 insert를 할 수 있는 방법을 간단하게 알아봅시다.
insert를 할 때 사용한 테이블은 아래와 같습니다. 기억해주세요!
CREATE TABLE `TEAM`
(
`id` int not null auto_increment,
`name` varchar(255) not null,
primary key (id)
);JPA
첫 번째로 소개할 방법은 JPA를 이용한 방법입니다. JPA는 ORM기술입니다. Object Relation Mapping이라는 말의 약자로, OOP 진형의 패러다임과 DB 진형의 패러다임을 매핑해 주는 기술이라고들 알고 있을 겁니다.
JPA의 특징으로는 쿼리를 자동 생성해 주는 점과 객체를 다루듯이 연관 관계가 있는 객체를 탐색할 수 있다는 점입니다. 그 외에도 여러 특징이 있지만, insert를 할 때엔 객체 자체를 save() 혹은 persist() 메서드의 인자로 넣을 수 있다는 점입니다. 그럼 JPA 진영에서 이용할 수 있는 다양한 insert 방법에 대해서 소개하겠습니다.
JPA에서 사용할 Entity 클래스는 아래 클래스입니다.
public class TeamEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String name;
}EntityManager.persist()
첫 번째 방법은 EntityManager의 persist() 메서드입니다.
EntityManager 클래스를 주입받은 후 persist() 메서드의 인자로 엔티티 클래스를 넣습니다.
entityManager.persist(new TeamEntity("team"));이 방법은 처음 삽입할 때만 사용이 가능합니다. 이후 소개할 Spring Data JPA의 메서드인 save()의 경우 저장과 수정이 동시에 가능하다는 차이가 있습니다.
JpaRepository.save()
두 번째 방법은 Spring Data Jpa의 JpaRepository가 제공하는 save() 메서드입니다. 바로 앞에서 소개했지만, 이 메서드는 id가 있는 객체라면 저장을, 없는 객체는 수정을 합니다.
teamRepository.save(new TeamEntity("team"));JpaRepository.saveAll()
세 번째 방법은 JpaRepository가 제공하는 saveAll() 메서드입니다. 객체를 리스트 형태로 받아서, 반복해서 저장합니다.
List<TeamEntity> teams = new ArrayList<>();
for (int i = 0; i < n; i++) {
teams.add(new TeamEntity("team"));
}
teamRepository.saveAll(teams);JpaRepository.saveAndFlush()
네 번째 방법은 JpaRepository가 제공하는 saveAndFlush() 메서드입니다. save()와 동일한 형태로 나가지만, entityManager의 flush() 메서드를 바로 호출합니다. entityManager는 일정 양의 쿼리를 모아둔 후 flush를 하는 시점에서 db로 전달을 하는데, 이 메서드는 즉시 flush()를 호출하기 때문에, 바로 쿼리를 전달해야 하는 시점에서 사용해야 할 것입니다. 아래와 같이 사용합니다.
teamRepository.saveAndFlush(new TeamEntity("team"));JpaRepository.saveAllAndFlush()
다섯 번째 방법은 JpaRepository가 제공하는 SaveAllAndFlush() 메서드입니다. 앞서서 확인한 saveAll() 메서드를 사용하고, flush()를 호출하는 형태로 동작합니다.
List<TeamEntity> teams = new ArrayList<>();
for (int i = 0; i < n; i++) {
teams.add(new TeamEntity("team"));
}
teamRepository.saveAllAndFlush(teams);JpaQueryFactory.insert()
여섯 번째 방법은 QueryDSL을 이용하는 insert() 메서드입니다. QueryDSL은 쿼리를 작성할 때, 메서드와 Q클래스를 이용해 String으로 쿼리를 작성하는 다른 방법에 비해 오류를 줄일 수 있습니다. 다음과 같은 방법으로 insert를 할 수 있습니다.
jq.insert(teamEntity)
.columns(teamEntity.name)
.values("name")
.execute();JPA를 활용해서 insert를 하는 방법은 여기까지입니다. JPA를 사용하면 직접 쿼리를 작성하지 않아도 된다는 편리함이 있습니다. 하지만 이후 성능에서 확인할 수 있지만, 직접 SQL를 작성하는 다른 방법에 비해서는 현저하게 성능이 떨어진다는 점이 있습니다. 아무래도 한번 SQL을 변환하는 과정이 있어서가 아닌가..라는 생각이 드는데요. 성능을 일정 수준 떨어져도, 개발 편의성이 좋기 때문에 많은 개발자들이 선택하는 방법인 것 같습니다.
Mybatis
JPA 다음 방법은 Mybatis입니다. JPA에 대한 관심이 이렇게 올라오기 전에는 대부분 Mybatis를 사용했다고 합니다. 그리고 현재에도 Mybatis를 이용하는 기업이 많기 때문에, 사용 방법과 특징에 대해서 알아봅시다.
Mybatis with XML
Mybatis를 사용하는 첫 번째 방법이자, 가장 대중적인 방법은 XML을 이용하는 방법입니다. XML에 쿼리를 작성하고, 해당 XML과 매핑되는 인터페이스를 선택해 그 인터페이스에서 메서드를 호출하면 XML에 작성된 쿼리가 불리는 형태로 사용합니다.
작성한 XML은 다음과 같습니다.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.kk.springsql.mapper.TeamMapper">
<insert id="insertTeamXML">
insert into team (name) values (#{name})
</insert>
</mapper>그리고 얘를 호출하는 TeamMapper 클래스에는 insert에 적힌 id에 해당하는 메서드가 존재합니다.
void insertTeamXML(Team team);본래는 어떤 객체가 들어오는지, 어떤 객체로 리턴하는지 등에 대해서 상세하게 작성해서 사용할 수 있지만, 각 방법을 자세히 다루는 것이 아니기 때문에, 간단하게 소개하겠습니다.
이렇게 클래스와 XML을 준비했다면 아래와 같이 사용할 수 있습니다.
teamMapper.insertTeamXML(new Team("team"));Mybatis with Annotation
Mybatis를 사용할 수 있는 두 번째 방법은, 쿼리를 어노테이션에 직접 작성해서 사용하는 방법입니다. TeamMapper라는 클래스에 다음과 같이 작성해 줍니다.
@Insert("insert into Team (name) values (#{name})")
void insertTeamDirect(Team team);앞에서 본 XML의 내용과 동일하게 쿼리를 작성해 준다면, 마찬가지로 사용할 수 있습니다.
teamMapper.insertTeamDirect(new Team("team"));Mybatis with SQLProvider
Mybatis를 사용할 수 있는 마지막 방법은, SQL을 작성한 다른 클래스로부터 쿼리를 제공받아서 사용하는 방법입니다.
아래와 같이 SQL을 제공하는 클래스를 작성하고
public String insertQuery(){
return new SQL().INSERT_INTO("team")
.VALUES("name", "#{name}")
.toString();
}해당 메서드를 아래와 같이 제공받습니다.
@InsertProvider(type = TeamProvider.class, method = "insertQuery")
void insertTeamProvider(Team team);그리고 마찬가지로 사용하시면 됩니다.
teamMapper.insertTeamProvider(new Team("team"));Mybatis의 경우 XML만 알고 있었는데, 찾아보니 여러 방법이 있다는 것을 찾을 수 있었습니다. 특히 2번째, 3번째 방법은 JPA나 QueryDSL과 유사한 측면이 있어서 신기했었고, JPA를 이용하지 않는 상황이라면 고려해 볼 만하다고도 느꼈습니다.
하지만 대체로 XML에 대한 레퍼런스가 많고, 기업의 경우 쿼리의 길이가 매우 길기 때문에, 어노테이션이나 클래스에서 관리하는 것은 어려움이 있을 수 있다고 생각되어 XML을 많이 이용하지 않을까 싶습니다.
JdbcTemplate
마지막으로 준비한 방법은 JdbcTemplate입니다. Jdbc를 직접 사용하기 불편함이 있기 때문에, Jdbc를 이용할 때 해야 하는 복잡한 과정을 처리해 주고 쿼리만 작성해서 사용할 수 있는 라이브러리입니다. 지금까지 소개했던 방법들과의 차이로는 bulk 연산이 가능해, 대용량 처리에 있어서 이점을 보입니다.
jdbctemplate.update
JdbcTemplate을 사용하는 첫 번째 방법은 update() 메서드를 이용하는 것입니다. update() 메서드의 인자로 insert 쿼리를 작성하고, ?에 해당하는 값을 그다음 인자로 넣어줘서 사용합니다.
jdbcTemplate.update("insert into team (name) values (?)", "team");SimpleJdbcInsert.execute
두 번째 방법은 SimpleJdbcInsert라는 클래스를 이용하는 것입니다. insert문을 작성하는 방법은 크게 차이가 날 수 없습니다. 그래서 해당 과정을 간략히 해주는 SimpleJdbcInsert 클래스를 이용합니다. SimpleJdbcInsert는 넣을 column의 이름과 값을 매핑해서 사용할 수 있습니다.
아래 경우는 위에서 본 것처럼 name column 에 "team"이라는 값을 넣기 위해서 Map을 이용했고, execute()의 인자로 해당 map 객체를 넣어준다면 자동으로 insert 쿼리가 완성됩니다.
Map<String, Object> params = new HashMap<>();
params.put("name", "team");
simpleJdbcInsert.execute(params);PreparedStatementCreator
세 번째 방법은 PreparedStatementCreator를 이용해 PreparedStatement를 만들어서 쿼리를 작성하는 방법입니다. 이전에 JDBC를 이용해 봤다면 많이 접해봤을 PrepareStatement를 만드는 방법과 동일합니다.
jdbcTemplate.update(new PreparedStatementCreator() {
@Override
public PreparedStatement createPreparedStatement(Connection con) throws SQLException {
PreparedStatement pstm = con.prepareStatement("insert into team (name) values (?)");
pstm.setString(1, "team");
return pstm;
}
});NamedParameterJdbcTemplate
네 번째 방법은 NamedParameterJdbcTemplate을 이용하는 방법입니다. 사용 방법자체는 JdbcTemplate과 크게 차이는 없지만, jdbcTemplate이나 preparedStatement나 둘 다 ?를 이용하고 인덱스로 위치를 특정 짓는 방법을 벗어나 이름으로 해당 위치를 지정하는 방법입니다.
만약 JPA를 이용해 봤다면, JPA에서 인자를 넣어줄 때 사용하는 방법을 떠올리면 될 것입니다.
우선 쿼리는 다음과 같이 작성합니다.
String sql = "insert into team (name) values (:name)";:OO 의 위치에 개발자는 넣고 싶은 값을 넣으면 됩니다.
값을 넣기 위한 방법으로는 2가지가 있습니다.
첫 번째로는 Map을 이용하는 방법입니다. 앞서서 SimpleJdbcInsert에서 본 것처럼 이용이 가능합니다.
String sql = "insert into team (name) values (:name)";
Map<String, Object> params = new HashMap<>();
params.put("name", "team");
namedParameterJdbcTemplate.update(sql, params);두 번째 방법 BeanPropertySqlParameterSource를 이용하는 것입니다. 값이 들어있는 클래스를 받아서 자동으로 세팅을 해줍니다. 하지만 이 경우 map과 달리 이름을 동일하게 설정해야 합니다.
아래와 같이 사용할 수 있습니다.
String sql = "insert into team (name) values (:name)";
Team team = new Team();
team.setName("team");
BeanPropertySqlParameterSource namedParameterSource = new BeanPropertySqlParameterSource(team);
namedParameterJdbcTemplate.update(sql, namedParameterSource);Bulk Insert
처음에 소개했던 것처럼, JdbcTemplate의 경우 Bulk 연산이 가능합니다. 기본 JdbcTemplate과 NamedParameterJdbcTemplate이 모두 사용가능하고, 대량의 데이터를 다루게 된다면, 이점을 볼 수 있습니다. 아래와 같이 사용할 수 있습니다.
JdbcTemplate
List<String> teamNames = new ArrayList<>(n);
for (int i = 0; i < n; i++) {
teamNames.add("team");
}
jdbcTemplate.batchUpdate("insert into team (name) values(?)", new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setString(1, teamNames.get(i));
}
@Override
public int getBatchSize() {
return teamNames.size();
}
});NamedParameterJdbcTemplate
SqlParameterSource[] parameterSources = new SqlParameterSource[n];
for (int i = 0; i < n; i++) {
Map<String, Object> params = new HashMap<>();
params.put("name", "team");
parameterSources[i] = new MapSqlParameterSource(params);
}
namedParameterJdbcTemplate.batchUpdate("insert into team (name) values (:name)", parameterSources);성능 비교
그럼 이제 여러 가지 방법들에 대해서 알아보았으니, 각각의 방법의 성능을 비교해 보도록 하겠습니다.
테스트 환경은 다음과 같습니다.
| CPU | Intel i5-12500H |
|---|---|
| RAM | RAM : 24GB |
| Java | 17 |
| Test Framework | Junit5 |
하지만 테스트를 돌린 노트북이 커피를 마셔서 성능이 온전하지 않습니다.
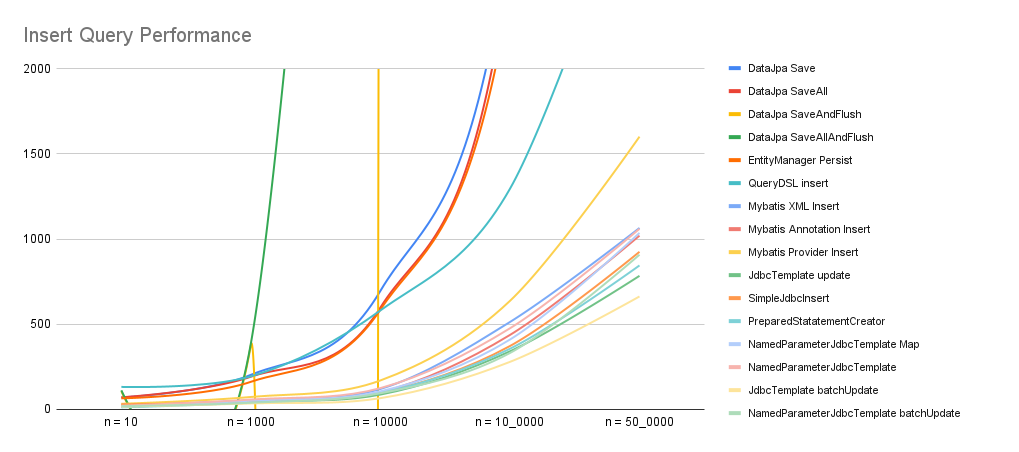
각각의 방법에 대해서 N이 100, 1000, 10000, 100000, 500000 일 때 시작 시간과 끝 시간을 계산했고 그 차이를 계산했습니다. 확인해 보시죠.
| 이름 | n = 10 | n = 1000 | n = 10000 | n = 10_0000 | n = 50_0000 |
|---|---|---|---|---|---|
| DataJpa Save | 70 | 203 | 696 | 2767 | 10754 |
| DataJpa SaveAll | 71 | 192 | 598 | 2604 | 10718 |
| DataJpa SaveAndFlush | 107 | 378 | 8737 | 950177 | ♾ |
| DataJpa SaveAllAndFlush | 112 | 388 | 8701 | ♾ | ♾ |
| EntityManager Persist | 65 | 162 | 586 | 2446 | 9474 |
| QueryDSL insert | 132 | 194 | 581 | 1295 | 3255 |
| Mybatis XML Insert | 27 | 53 | 120 | 513 | 1065 |
| Mybatis Annotation Insert | 24 | 51 | 100 | 437 | 1020 |
| Mybatis Provider Insert | 33 | 73 | 170 | 637 | 1601 |
| JdbcTemplate update | 14 | 45 | 87 | 341 | 784 |
| SimpleJdbcInsert | 30 | 45 | 98 | 372 | 925 |
| PreparedStatatementCreator | 12 | 40 | 98 | 356 | 845 |
| NamedParameterJdbcTemplate Map | 17 | 51 | 106 | 410 | 1036 |
| NamedParameterJdbcTemplate BeanPropertySqlParameterSource | 21 | 58 | 125 | 476 | 1060 |
| JdbcTemplate batchUpdate | 16 | 35 | 66 | 279 | 663 |
| NamedParameterJdbcTemplate batchUpdate | 19 | 39 | 95 | 331 | 908 |
정리
Spring에서 insert를 하는 다양한 방법에 대해서 알아보았습니다. 라이브러리가 해주는 작업이 많을수록 성능 자체는 느리다는 것을 확인할 수 있었습니다. JPA, Mybatis, JdbcTemplate 순으로의 성능이 나오는 것을 볼 수 있었고, 각각의 특징에 대해서도 알 수 있었습니다.
Spring에서 insert를 하는 여러 방법에 대해서 살펴볼 수 있었고, 다음 시간엔 select, udpate, delete와 같은 방법에 대해서도 알아보도록 하겠습니다.
