📌 Pandas
구조화된 데이터의 처리를 지원하는 python 라이브러리로 numpy와 통합하여 강력한 스프레드시트 처리 기능을 제공한다. 그래서 데이터 처리 및 통계 분석을 위해 많이 사용되고 있다.
구글 코랩으로 실습하기
판다스 10분 완성
📌 Neural network
비선형 모델인 신경망(Neural network) 의 기본적인 개념과 그 의미를 풀어나가기 위한 도구들을 정리해본다.
📄 처음으로 되돌아가볼까?
신경망의 개념을 이해하는데 도움이 될 문제들을 살펴보도록 한다.
✏️ 선형회귀(Linear Regression)

선형회귀(다중선형회귀,Multiple Linear Regression) 는 수치형 설명변수 X 와 연속형 숫자로 이루어진 종속변수 Y 간의 관계를 선형으로 가정하고 이를 잘 표현할수 있는 회귀계수 β 를 데이터로부터 추정하는 모델 이다.
y=f(x)=β0+β1x1+⋯+βpxp=βTx,
xT=[1,x1,…,xp]βT=[β0,β1,…,βp]
데이터를 가장 잘 표현할수 있는 회귀계수 β 를 찾기 위해서 모델의 예측값(y^)과 실제값(y)의 차이, 즉 최소제곱법(Least Squared Method)를 이용하여 잔차(Residual)의 합이 최소가 되도록 한다.
∑residual2=i∑(yi−f(xi,β))2
✏️ 다항 회귀(Polynomial Regression)

선형회귀를 확장하여 단순 직선이 아닌 d차 다항함수 에 대해 생각해 볼 수 있다.
y=β0+β1x
를 확장하여
y=β0+β1x1+β2x2+⋯+βdxd
다항 회귀 모델을 생성할 수 있다.
✏️ 로지스틱회귀(Logistic Regression)

연속형 숫자가 아닌 범주형(Categorical) 종속 변수 는 근본적으로 범주형 데이터의 숫자 자체가 의미를 지니고 있지 않기 때문에 다중선형회귀(Multiple Linear Regression)를 적용할수 없다. 그래서 제안된 것이 로지스틱 회귀 모델 이며, 이를 이해하기 위해 하나씩 살펴보도록 한다.
- Odds
Odds 는 사건A가발생하지않을확률사건A가발생할확률=P(Ac)P(A)=1−P(A)P(A) 이다. odds 는 P(A)의 값이 커진다면(1에 가까워진다면) 증가 / 값이 작아진다면(0에 가까워진다면) 감소하게 된다. 다르게 생각한다면 odds값이 크다는 것은 사건 A가 발생할 확률이 커진다는 것이다.

1−P(Y1∣x)P(Y1∣x)=eβTx
⇒P(Y1∣x)=eβTx(1−P(Y1∣x))=eβTx−eβTxP(Y1∣x)⇒P(Y1∣x)(1+eβTx)=eβTx
∴P(Y1∣x)=1+eβTxeβTx=1+e−βTx1

- 결정경계(Decision Boundary)
임의의 입력 벡터 x 의 클래스를 결정하기 위한 방법은 P(Y=1∣X=x) 와 P(Y=0∣X=x) 의 값을 비교하는 것이다. 다음 수식을 통해 결정 경계는βTx=0 인 hyperplane 임을 알 수 있다.
P(Y1∣x)>P(Y0∣x)
⇒P(Y0∣x)P(Y1∣x)>1⇒log1−P(Y1∣x)P(Y1∣x)>0
∴βTx>0

- 다항 로지스틱 회귀(Multinomial Logistic Regression)
만약 클래스가 3개 이상 이라면 다음과 같이 2개의 이항 로지스틱 회귀 로 문제를 해결할수 있다.(1) logP(Y3∣x)P(Y1∣x)=β1Tx⇒P(Y1∣x)=eβ1TxP(Y3∣x)⋯(∗1) (2) logP(Y3∣x)P(Y2∣x)=β2Tx⇒P(Y2∣x)=eβ2TxP(Y3∣x)⋯(∗2)
(3) P(Y3∣x)=1−P(Y1∣x)−P(Y2∣x)⇒P(Y3∣x)=1−(∗1)−(∗2)⇒P(Y3∣x)(1+eβ1x+eβ2x)=1
∴P(Y3∣x)=1+eβ1x+eβ2x1
확장하여 K개의 클래스를 분류하는 문제는 다음과 같다.
P(Yk∣X=x)=1+∑i=1K−1eβiTxeβkTx ,(k=0,1,…,K−1)P(YK∣X=x)=1+∑i=1K−1eβiTx1
의 두 식을 일반화한다면 다음과 같다.
P(Yi∣x)=eβiTxP(YK∣x)=eβiTx1+∑i=1K−1eβiTx1=eβKTx+∑i=1K−1eβiTxeβiTx (∵P(YK∣x)=eβKTxP(YK∣x))
∴P(Yi∣x)=∑i=1KeβiTxeβiTx
✏️ 단층 퍼셉트론(Single-layer Perceptron)
퍼셉트론은 다수의 신호를 입력으로 받아 step function 을 이용하여 임계값을 기준으로 0 또는 1의 신호를 출력한다. 다음은 단층 퍼셉트론을 표현하였다.


⎩⎪⎨⎪⎧y=1, if ∑i=1nxiwi=wTx≥θy=0, if ∑i=1nxiwi=wTx<θ
위의 식에서 임계값을 좌변으로 넘기고 편향(b,bias) 으로 표현할수도 있는데, 보통 다음과 같이 표현된다. (다음 그림에서는 wo 가 bias 로 표현되었다.)

⎩⎪⎨⎪⎧y=1, if ∑i=1nxiwi+w0=wTx+w0≥0y=0, if ∑i=1nxiwi+w0=wTx+w0<0
단층 퍼셉트론을 이용하면 AND,NAND,OR 게이트 를 쉽게 구현할 수 있다.

- AND 게이트

- NAND 게이트


✏️ 다층 퍼셉트론(Multi-layer Perceptron)
단층 퍼셉트론으로 AND,NAND,OR 문제를 풀 수 있었지만 XOR 문제는 풀 수 없었다. 즉 XOR 문제는 직선 하나로 나누는 것(선형분리)은 불가능하였고, 비선형 영역으로 분리했어야 했다.


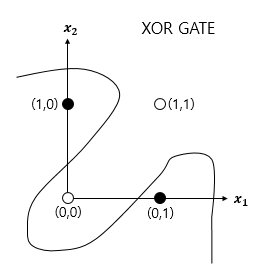
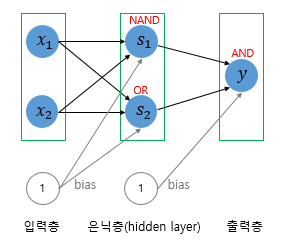
그래서 은닉층(Hidden layer)을 추가하여 XOR 문제를 해결하려 제안된 것이 바로 MLP(Multi-layer Perceptron) 이다.

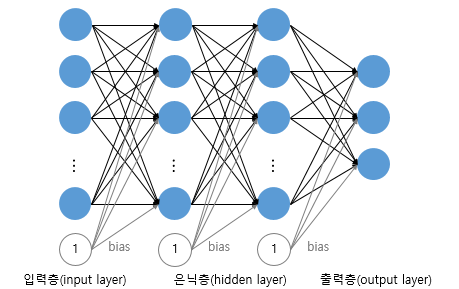
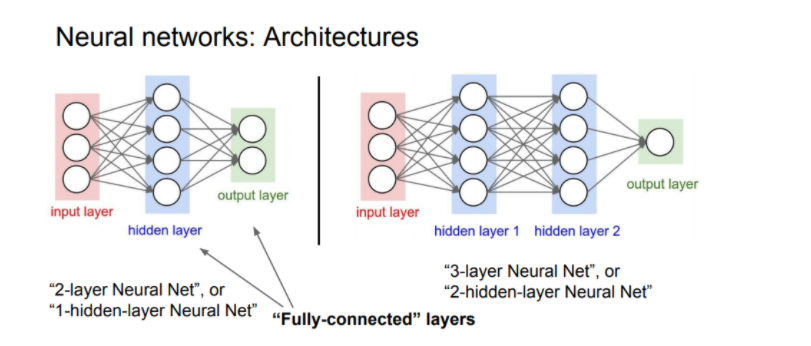
이후로 더 복잡한 문제을 풀기 위해 은닉층은 늘려졌고, 아래와 같이 은틱층이 2개 이상인 신경망을 심층 신경망(Deep Neural Network, DNN) 이라고 한다.
📄 이제 신경망을 살펴볼까?
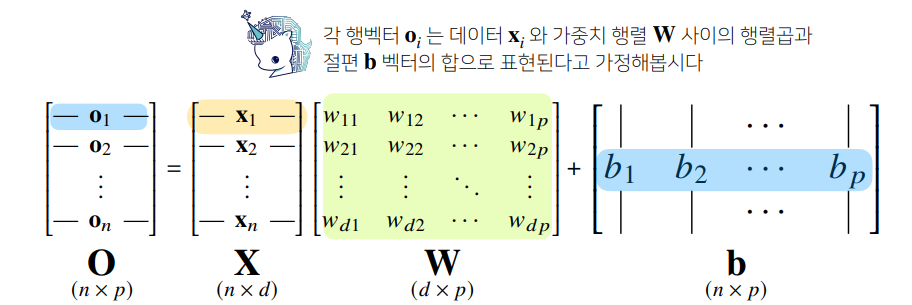
신경망을 수식으로 살펴본다면 각 데이터에 대해 d개의 변수로 p개의 선형모델 을 생각해 볼 수 있다.
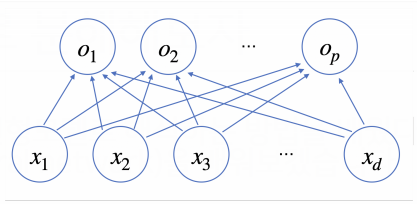
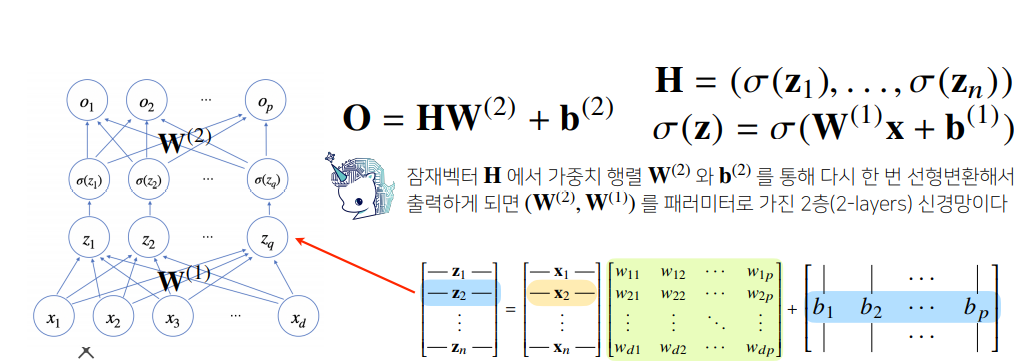
신경망에서 출력벡터 O 를 얻기 전 활성함수 σ 가 적용되는 하나의 은닉층 H 를 생각해본다면, 다음과 같이 각 잠재벡터 zi=(z1,z2,…,zp)에 활성함수 σ 를 적용하여 생성된 H=(σ(z1),σ(z2),…,σ(zn)) 를 얻을 수 있다.

출력벡터 O 를 얻기 위해 가중치 행렬 W(2) 과 b(2) 를 통해 선형변환하면 (W(2),W(1)) 을 파라미터로 가지는 2-layers Neural Net(1-hidden-layer Neural Net) 이 만들어진다.
📄 활성함수(Activation Function)는 무엇일까?
활성함수는 입력 신호의 총합 을 그대로 사용하지 않고, 출력 신호로 변환하는 함수 입니다. 이름에서 말해주듯이 활성함수는 입력 신호의 총합이 활성화 되는지 아닌지를 정하는 역할을 합니다. 단층퍼셉트론 에서 살펴봤듯이 step function 역시 활성함수이다
<참고>
다른 활성함수에 대해 알고 싶다면 여기 를 참고하자.
📄 활성함수(Activation Function)는 왜 비선형 함수여야만 할까?
활성함수의 가장 중요한 특징은 비선형성 이다. 단층퍼셉트론 에서 살펴봤듯이 step function 역시 비선형 함수이다. 만약 활성함수를 선형함수 로 쌓게 된다면 층을 무한정 깊게 쌓더라도 선형성 을 띄기 때문에 선형함수를 사용한 하나의 은닉층을 가지는 뉴럴넷과 깊게 쌓은 뉴럴넷은 차이가 없다.
📄 층을 여러개 쌓는 이유는 무엇일까?
이론적으로는 Universal Approximation Theorem (하나의 은닉층과 비선형 활성함수를 가진 뉴럴넷을 이용해 어떠한 형태의 연속함수든 모델링 할 수 있다. )에 의해서 2-layers Neural Net 으로도 임의의 연속함수를 근사할 수 있다. 그러나 층이 깊어진다면 목적함수를 근사하는데 필요한 뉴런의 숫자가 훨씬 빨리 줄어들어 효율적으로 학습이 가능하기 때문에 층을 여러개 쌓게 된다.( 물론 층을 계속 깊게 쌓게 되면 최적화와 모델 학습 부분에 있어 어려워진다.)

📄 순전파(Forwardpropagation) vs 역전파(Backpropagation)
✏️ 순전파(Forwardpropagation)
순전파(forward propagation) 은 뉴럴 네트워크 모델의 입력층부터 출력층까지 순서대로 변수들을 계산하고 저장하는 것을 의미하며 학습과정이 아닌 단순히 값들을 다음 층으로 넘겨주는 과정이다.
✏️ 역전파(Backpropagation)
역전파(back propagation) 는 뉴럴 네트워크의 파라미터들에 대한 그래디언트(gradient)를 계산하는 방법을 의미합니다. 일반적으로는 뉴럴 네트워크의 각 층과 관련된 목적 함수(objective function)의 중간 변수들과 파라미터들의 그래디언트(gradient)를 출력층에서 입력층 순으로 연쇄법칙(Chain rule) 을 통해 계산하고 저장한다.

📚 Reference
Logistic Regression1
Logistic Regression2
Linear Regression, Polynomial Regression
Perceptron1
Perceptron2
Perceptron3
Activation Function

