/usr/ = unix system resource
수업의 핵심타겟
- C 언어 고급&응용
- 리눅스 개발환경에 익숙해지는 것
sudo halt -- 서버 종료
이 명령어는 서버를 종료하는 명령어입니다.
참고로 서버를 종료하는 동일한 명령어를 정리하면 아래와 같다.$ hlat $ shutdown -h now $ poweroff $ init 0
라즈베리파이 그냥 전원선 뽑아서 끄지 말고, 위 명령어로 꺼라.
리눅스는 모든 정보를 버퍼에 저장하는데, 그냥 꺼버리면 그 버퍼 내용이 하드디스크와 동기화가 안되고 종료되어버리기 때문에 문제가 발생할 수 있다.
halt를 치면 어플리케이션에서 썼던 메모리를 회수해주고 버퍼와 하드디스크를 동기화까지 해주고 종료를 해준다.
linux BSP
- 부트로더
- 커널
-> 커널은 만들어져있는 것을 포팅하는 것을 배움(포팅도 쉬운게 아니다)- 디바이스 드라이버
-> 우리 수업의 핵심교과: "우리의 목적은 디바이스 드라이버를 직접 만들어보는 것"- 파일 시스템
LED 제어
디바이스 드라이버: 커널 안에서 동작하는 소프트웨어(커널 소스의 일부분)
어플리케이션: 커널 바깥에서 시스템콜 함수를 통해서 커널 안의 LED를 제어하는 드라이버를 호출하여 제어
풀업 & 풀다운 // 액티브로부 & 액티브하이
anode(A) cathode(K)
외부의 유입전류(싱크 전류)가 MCU의 출력전류(소스 전류)가 훨씬 베리에이션 폭이 크다.
그래서 외부의 유입전류 값으로 on/off를 제어하는 것은 불안정 하다.
그래서 MCU의 출력전류 값으로 on/off를 제어하는 것이 더 안정적이다.
그래서 전통적으로 active-low를 사용하는 것이다.
linux booting sequence monitoring via serial communication
원격 putty 터미널은 부팅이 다 되어야만 쓸 수 있기 때문에, 리눅스가 부팅되는 과정을 볼 수 없다.
그래서 부팅되는 과정을 터미널에서 하나하나 쭈르륵 전부다 터미널 로그로 확인하기 위해서 직접 라즈베리파이 RX/TX에 시리얼 통신 라인을 연결해서 볼 것이다.
shell script language
- .sh쉘 스크립트는 실행 가능한 파일이기 때문에 쉘 스크립트 언어라고 부른다.
- 기본 골자는 C언어의 골자를 가져왔다.
일반적으로 #는 주석이지만 #!와 같이 느낌표와 함께 쓰이면 이것은 느낌표가 아닙니다. #!는 셔뱅(shebang)이라고 부르고, #! 다음에 오는 문구를 실행합니다. 예를 들어 #!/bin/bash라고 쓰면 스크립트가 실행되면 /bin/bash부터 실행하게 됩니다. 따라서 /bin/bash 이후에 나오는 명령어는 bash를 이용해서 해석할 것이라는 의미입니다.
우리가 받은 푸시버튼 어레이는 풀다운 회로가 기본 적용되어있다.(=액티브하이)
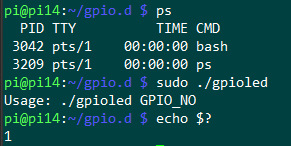
프로그램이 운영체제로 뱉어내는 return값
pi@pi14:~/gpio.d $ sudo ./gpioled
Usage: ./gpioled GPIO_NO
pi@pi14:~/gpio.d $ echo $?
1bash shell의 $? 변수에는 직전 프로그램의 리턴값이 담겨있다.
위의 경우 gpioled라는 프로그램이 운영체제에 뱉은 리턴값이 1이었기 때문에, echo로 ? 변수를 찍어보면 1이 담겨있는 것을 알 수 있다.
그런데 여기서 중요한 것은 운영체제가 리턴값을 받아서 bash shell에서 그것을 echo로 찍어서 볼 때 unsigned char 형태로 찍기 때문에 만약 직전 프로그램의 리턴값이 음수라면 무조건 255만 출력하게 된다.
이렇게 되면 나중에 디버깅을 할 때 문제가 되므로, 이왕이면 프로그램이 운영체제에 뱉어내는 리턴값은 양수로 하여 0~255 바운더리 안에 오도록 설정하는 것이 '관례'이다.
어제 썼던 쉘 스크립트에서도 이러한 운영체제에 대한 리턴값을 사용했다.
#!/bin/bash
#vi ~/.profile
#if [ -f /mnt/nfs.sh ] ; then
# . /mnt/nfs.sh
#fi
SERVIP=10.10.141.30
if ! df | grep lect_nfs > /dev/null ; then
ping -c 1 $SERVIP > /dev/null
if [ $? -eq 0 ] ; then
sudo mount -t nfs $SERVIP:/srv/nfs /mnt/lect_nfs
df | grep lect_nfs
fi
fi" if [ $? -eq 0 ] ; then " 이 라인을 보면 바로 위에서 다뤘던 내용이 적용되어 있다는 것을 눈치챌 수 있다. 직전 프로그램인 "ping"의 리턴값이 0이라면, 정상 핑이 되었다는 뜻이기 때문에 마운트를 연결하는 행위를 했던 것이다.
open()으로 받은 fd의 정체
...
int ledControl(int gpio)
{
int fd;
char buf[BUFSIZ];
fd = open("/sys/class/gpio/export", O_WRONLY);
sprintf(buf, "%d", gpio);
write(fd, buf, strlen(buf));
close(fd);
...
}open()이라는 low-level함수로 파일을 열면 int 3번부터 할당하여 변수값이 들어가면서 열린다. 우리는 그 번호로써 파일을 열고 닫고 할 수 있다.
fd는 3번부터 열린다. 0번, 1번, 2번은 미리 다른 것에 할당되어있다.
(0번: stdin 표준입력, 1번: stdout 표준출력, 2번: stderr 표준오류)
하지만 여기서 "3"이라는 숫자는 전혀 중요한 것이 아니다. 우리는 open이라는 함수가 리턴하면서 저장된 fd라는 "변수의 주소"에 관심이 있는 것이다.
C를 통한 명령행 인수 처리
C를 통한 명령행 인수 처리
C 교재의 497페이지 부분에 있다.
"main함수의 명령행 인수 사용"
결국은 ls, cd, mv, cp, gcc, ... 전부다 main(int argc, char* argv[])가 있는 프로그램인 것이다.
C에서 홑따옴표와 쌍따옴표
C에서 '6'과 "6"은 다르다.
'6'은 1바이트이다(0x36). '6'에 대한 아스키값인 0x36만 들어가 있다.
"6"은 2바이트이다(0x36 0x00). 뒤에 널문자가 붙어있다. '6'에 대한 아스키값인 0x36과 '\0'(널문자)에 대한 아스키 값인 0x00이 들어가 있다.
리눅스에서 디바이스를 제어하는 두가지 큰 틀
리눅스에서 디바이스를 제어파는 방식은 두가지가 있다.
-
첫째는 라이브러리를 사용하지 않고 그냥 로우레벨에서 echo 명령을 통해서 low level에서 파일시스템 입출력을 통해서 값을 직접 써주면서 제어하는 것이다. 모든 기능이 되는 것은 확실하지만 그 과정이 대단히 불편한다.
-
둘째는 Wiring Pi 같은 라이브러리를 사용하는 것이다. 그러면 C언어 함수를 통해서 low level에서 파일시스템 입출력 없이도 편하게 제어가 된다.
(아두이노도 내부적으로는 WiringPI를 사용하고 있다.)
라즈베리파이는 ADC(Analog Digital Converter)가 없다.
Wiring Pi 설치
<교재 124페이지 참고>
-
github에서 Wiring Pi 소스를 git clone으로 가져온다.
-
클론된 폴더 안에 들어가서 ./build를 실행하여 빌드한다.
-
예제를 가져와서 실행해보자.
pi@pi14:~/gpio.d $ cp WiringPi/examples/blink.c . -
led포트 gpio를 내가 꽂은 것에 맞게 변경해준다.
-
이제 컴파일을 해보자.
pi@pi14:~/gpio.d $ gcc blink.c -o blink /usr/bin/ld: /tmp/ccDkh9gO.o: in function `main': blink.c:(.text+0x10): undefined reference to `wiringPiSetup' /usr/bin/ld: blink.c:(.text+0x1c): undefined reference to `pinMode' /usr/bin/ld: blink.c:(.text+0x28): undefined reference to `digitalWrite' /usr/bin/ld: blink.c:(.text+0x30): undefined reference to `delay' /usr/bin/ld: blink.c:(.text+0x3c): undefined reference to `digitalWrite' /usr/bin/ld: blink.c:(.text+0x44): undefined reference to `delay' collect2: error: ld returned 1 exit status pi@pi14:~/gpio.d $ gcc blink.c -o blink -lwiringPi위를 보면 알 수 있듯이 그냥 일반적으로 "gcc blink.c -o blink"으로 컴파일 하면 blink.c에서 include한 라이브러리들을 linking하지 못하여 컴파일이 안된다.
그래서 컴파일을 할 때 -l로 링킹 옵션을 줘야한다. 뒤에다가 "-lwiringPi"라는 옵션을 주면 wiringPi라는 라이브러리를 링킹하여 컴파일하겠다는 뜻이 된다. 그러므로 최종적으로 "gcc blink.c -o blink -lwiringPi"를 입력하면 정상적으로 컴파일이 되는 것을 볼 수 있다.
wiring pi에서 사용하는 GIPO 번호와 실제 라즈베리파이의 GIPO 번호와 다르다
교재 126쪽을 보면 실제 라즈베리파이4의 GPIO번호가 WiringPi에서는 몇번에 대응하는지 볼 수 있다.
vi용 ctags 설치
우선 선배 개발자님의 ctags 사용법 정리를 보고오자...
라즈베리파이에 ctags 설치
pi@pi14:~/gpio.d $ sudo apt install universal-ctags우분투에 ctags 설치
아래 명령어를 순차적으로 입력해본다.
$ sudo apt install ctags
$ cd /usr
$ cd include/
$ sudo ctags -R
$ ls -l tags잠시 vim설정을 해주겠다. 중요한 것은 vim 설정의 맨 마지막에 set한 tags관련 내용이다.
$ cd
$ sudo apt install vim
$ vi .vimrc
C 복습
C에서 8진수는 그냥 0을 붙인다.
코드영역
코드영역/데이터영역
- 코드영역: 우리가 작성한 코드 text 그 자체
- 데이터영역
- data영역
- read only 영역: 문자열 상수, ...
- read write 영역: 전역변수, static 변수, ...
- heap영역: 동적할당
- stack영역: 지역변수
- data영역
데이터버스와 32비트 시스템
32비트 시스템은 데이터 버스가 D0 ~ D31까지 있어서 CPU가 한번에 32비트(4바이트)씩 읽을 수 있다.
클럭 스피드와 T
MCU의 클럭 스피드가 16MHz라면 T = 62.5ns(나노 세컨드)가 된다. 즉 프로그램에서 1개의 "기계어 statement"를 실행하는데 62.5ns가 걸린다는 것이다. (중앙처리장치는 기본적으로 1클럭에 1개의 기계어를 처리한다.)(보통은 기계어 한줄에 어셈블리어 한줄이 대응하지만, 꼭 그렇지 않은 경우도 있다.)
memory mapped I/O 그리고 I/O mapped I/O
- memory mapped I/O 방식 : 프로세스들이 올라가는 메모리에 주변장치까지 전부 다 연결하는 방식
- I/O mapped I/O 방식 : PC같은 경우는 메모리가 엄청 커서 위의 방식대로 하면 하면 비효율적이라서 다른 방식(I/O mapped I/O)을 사용한다.
프로세스와 스택 포인터
프로그램은 시작할 때 스택포인터를 잡아줘야 한다. 그래서 STM32같은 MCU들이 처음 부팅되면 main()함수에 진입하기 위해 스택포인터를 어셈블리어로 잡아주는게 정석이다. 그런데 STM32의 경우 그냥 부팅하자마자 초기 sp가 셋팅되어있어서 그런 과정이 필요없다. 그래서 굉장히 C 친화적인 기기라고 한다.
로우레벨 C코드에서 굉장히 편리한 perror(argv[1]);
perror()는 표준오류를 출력해주는 함수이다. 굉장히 디버깅에 편리한 기능이다.
#include <unistd.h> /* 유닉스 표준(UNIX Standard) 시스템 콜을 위한 헤더 파일 */
#include <stdio.h> /* perror() 함수 */
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/fcntl.h>
#include <string.h>
int main(int argc, char * argv[])
{
int n, in, out, i,j;
char buf[1024];
/* 명령행 인수로 복사할 파일명이 없는 경우에 에러를 출력하고 종료한다. */
#if 0
printf("argc : %d \n",argc);
for(i=0;i<argc;i++)
{
printf("%s\n",argv[i]);
for(j=0;j<strlen(argv[i]);j++)
printf("%c\n",argv[i][j]);
}
#endif
if (argc < 3) {
// write(2, "Usage : copy file1 file2\n", 25);
fputs("Usage : copy file1 file2\n",stderr);
return 1;
}
/* 복사의 원본이 되는 파일을 읽기 모드로 연다. */
if ((in = open(argv[1], O_RDONLY)) < 0) {
perror(argv[1]);
return 2;
}
/* 복사할 결과 파일을 쓰기 모드(새로운 파일 생성 | 기존에 파일 내용 지움)로 연다. */
// if ((out = open(argv[2], O_WRONLY|O_CREAT|O_TRUNC, S_IRUSR|S_IWUSR)) < 0) {
if ((out = open(argv[2], O_WRONLY|O_CREAT|O_TRUNC, 0644)) < 0) {
perror(argv[2]);
return 3;
}
/* 원본 파일의 내용을 읽어서 복사할 파일에 쓴다. */
while (1)
{
n = read(in, buf, sizeof(buf));
printf("read : %d\n",n);
if(n == 0) {
printf("Done\n");
break;
}
else if(n < 0)
{
perror("read()");
break;
}
else
write(out, buf, n);
}
/* 열린 파일들을 닫는다. */
close(out);
close(in);
/* 프로그램의 정상 종료 시 0을 반환한다. */
return 0;
}
void pointer
void pointer를 함수의 parameter로 사용하고 싶으면, 반드시 같이 size_t 형식의 parameter를 같이 설정해줘야 한다.
왜냐하면 void pointer를 사용했다는 것은 호출 시점까지 자료형의 타입을 모른다는 것이다. 그러므로 포인터의 타입이 int, double, char 이냐가 정해져있지 않아서 void pointer로 가리키고 있는 주소에 있는 데이터를 어느 사이즈까지 읽어야 하는지 반드시 명시해줘야 한다는 것이다.
위의 코드에서 void pointer가 사용된 함수를 발췌하면 아래와 같다.
(void pointer 파라미터 = read()함수의 두번째 파라미터, write함수의 두번재 파라미터)
(size_t 형식의 파라미터 = read()함수의 세번째 파라미터, write함수의 세번재 파라미터)
...
while ((n = read(in, buf, sizeof(buf))) > 0 )
write(out, buf, n);
...위 코드는 정말 중요한 부분이다.
read()함수를 사용할 때는 size_t 파라미터 부분에 sizeof(buf)를 준다. 이렇게 주는 이유는 읽어들일 때 최대 어디까지 읽어들어야 하는지를 설정해준다. 그러면 read()함수는 널문자가 나올 때까지 계속 읽어나간다. 그러나가 최대 크기에 도달하기 전에 널문자가 등장하면 읽기를 멈추고 읽은 갯수를 return한다. 그래서 n에는 읽은 바이트의 갯수가 들어가는 것이다.
그렇기 때문에 write()함수를 사용할 때는 size_t 파라미터 부분에 반드시 앞서 read()함수가 return한 'n'값을 넣어줘야 한다. 절대로 write()함수를 사용할 때 size_t 파라미터 부분에 sizeof(buf) 형식으로 넣어주면 안된다. write() 함수는 뭐 '널문자가 오면 멈춘다' 뭐 이런 로직으로 동작하는게 아니기 때문에, 딱 읽은 만큼만 써줘야 한다. 만약 write()의 size_t 파라미터 부분에 sizeof(buf)를 넣어버리면 필요없는 쓰레기 값까지 전부 write()되는 불상사가 발생한다.
서버 클라이언트 코드 테스트

터미널을 두개를 띄워놓고 한쪽은 서버, 한쪽은 클라이언트로 실행해보고 테스트해보자.

하나의 머신 안에서 서버 클라이언트를 다 돌리기 때문에, 클라이언트는 루프백 주소인 127.0.0.1(localhost)로 ip를 지정하여 서버에 접속했다.
이 서버 클라이언트 코드는 반드시 손으로 한번 쳐보면서 이해해야 한다.
소켓프로그램은 형식이 다 똑같다.
형식이 다를 수가 없다. 우리는 이미 있는 코드에 read() write() 부분만 바꿔주면 된다.
하고 싶었던 것 1
32 ~ 35번째 라인에서 read() write()를 while문으로 돌리고 싶었다.
하고 싶었던 것 2
클라이언트에서 fgets()로 키보드 문자열을 받아서 서버로 write()를 하자는 것이다.
그러면 서버는 그 데이터를 read()해서 다시 write()로 클라이언트로 보내주면, echo 서버가 동작할 수 있다.
과제 (제출 이메일: tidyone@naver.com)
copy.c의 49~65번째 라인 사이의 while문을 수정하면 되겠다.
그 부분에 read() write()부분만 잘 바꿔 쓰면된다.
fd만 잘 다루면 되는 것이다. read(in, buf, sizeof(buf))에서 in이 fd이다.
리눅스 프로그래밍 기초
이미 많이 만들어져있는 system call function들
이미 한 200개가 넘는 시스템 콜 함수가 만들어져있다.
우리 수업의 목표는 이러한 커널 단의 시스템 콜 함수를 '직접'만들어보는 것이다.
가상 파일시스템
일반 파일을 다루듯이 다양한 장치들을 다룰 수 있도록 하기 위해서 인터페이스를 일원화했다. 다양한 장치들을 일원화된 인터페이스로 다루기 위해서 제안된 개념이 바로 "가상 파일 시스템"인 것이다.(어려운 개념이 아니다.)
저수준 입출력 함수 / 표준 입출력 함수
- 저수준 입출력함수 : open(), close(), read(), write(), ...
- 표준 입출력함수 : fopen(), fclose(), fgets(), fputs(), getc(), ...
표준입출력함수는 일반 C라이브러리다. 하지만 저수준 입출력함수는 커널 함수로써 커널 시스템 콜을 호출한다.
표준입출력함수는 중간에 버퍼를 둔다. 하지만 저수준입출력함수는 버퍼를 두지 않는다. 이게 둘의 가장 큰 차이점이다.
저수준입출력함수에서 버퍼를 두지 않는 이유는 간단하다. 하드웨어 제어는 명령이 발생하는 그 즉시 일어나야 하는데, 버퍼에 담아두고 꺼내는식으로 제어하면 실시간으로 바로바로 제어가 안된다. 그래서 버퍼를 없애버리는 것이다.
리눅스 명령어 "man" (= manual 보여주는 명령어)
리눅스 man <명령어 프로그램 이름 or 함수명>
: 메뉴얼을 싹다 보여주는 명령어
$ man man
$ man ls
$ man cd
$ man 2 printf // 2 System calls (functions provided by the kernel)
$ man 3 printf // 3 Library calls (functions within program libraries)
$ man stdio
...내가 쓰고 있는 함수가 어디에 선언되어 있는 함수인지 알아야 그걸 include해와서 쓸 수 있을 것이다. 그 때 내가 쓰는 함수가 어디에 있는 것인지 알기 위해 사용하는 리눅스 명령어가 man이다. 아래는 man 명령에 대한 manual 페이지이다.("man man"을 입력한 것)
MAN(1) Manual pager utils MAN(1)
NAME
man - an interface to the system reference manuals
SYNOPSIS
man [man options] [[section] page ...] ...
man -k [apropos options] regexp ...
man -K [man options] [section] term ...
man -f [whatis options] page ...
man -l [man options] file ...
man -w|-W [man options] page ...
DESCRIPTION
man is the system's manual pager. Each page argument given to man is normally the name of a program, utility or function. The manual page
associated with each of these arguments is then found and displayed. A section, if provided, will direct man to look only in that section of
the manual. The default action is to search in all of the available sections following a pre-defined order (see DEFAULTS), and to show only
the first page found, even if page exists in several sections.
The table below shows the section numbers of the manual followed by the types of pages they contain.
1 Executable programs or shell commands
2 System calls (functions provided by the kernel)
3 Library calls (functions within program libraries)
4 Special files (usually found in /dev)
5 File formats and conventions, e.g. /etc/passwd
6 Games
7 Miscellaneous (including macro packages and conventions), e.g. man(7), groff(7)
8 System administration commands (usually only for root)
9 Kernel routines [Non standard]
A manual page consists of several sections.
결과적으로 프로그램 컴파일을 했는데, 함수 사용에 필요한 라이브러리를 include하지 못해서 발생한 에러일 경우, man 명령어에 해당 함수명을 적어주면 어느어느 라이브러리를 include해야 하는지 "SYNOPSIS" 탭에 다 나온다.
리눅스 블로킹
리눅스에서 뭐만 하면 나오는게 blocking이다.
블로킹 함수를 호출하여 대기상태에서 슬립하는 프로세스가 많다.


