BMP파일 데이터는 상하 반전 형태로 저장
옛날에 생각하던 관습때문에 그렇다.
다만 사진이 180도 회전되어있다는게 아니라, 그저 좌표계가 반대로 되어있다는 것을 말하는 것이다.
영상개선
인간이 주관적으로 화질이 좋다고 느끼는 방향으로 신호를 변환하는 것을 말한다.
전처리 과정의 중요성
아무리 좋은 알고리즘이더라도, 꼭 전처리 과정으로 입력 데이터를 깨끗하게 해주고 넣어줘야 최상의 결과를 기대할 수 있다. 이러한 전처리 과정의 중요성은 비단 영상개선 알고리즘 뿐만 아니라 AI의 인공신경망에도 적용되고 있다. Neural Net에 데이터를 넣기 전에 전처리를 해줘서 결과의 신뢰성을 높였던 CNN이 것이 바로 그것이다.
영상 포화
영상의 데이터에 포화가 이루어진 상태이면, 영상 개선을 하고 싶어도 개선을 할수가 없다.
히스토그램 평활화
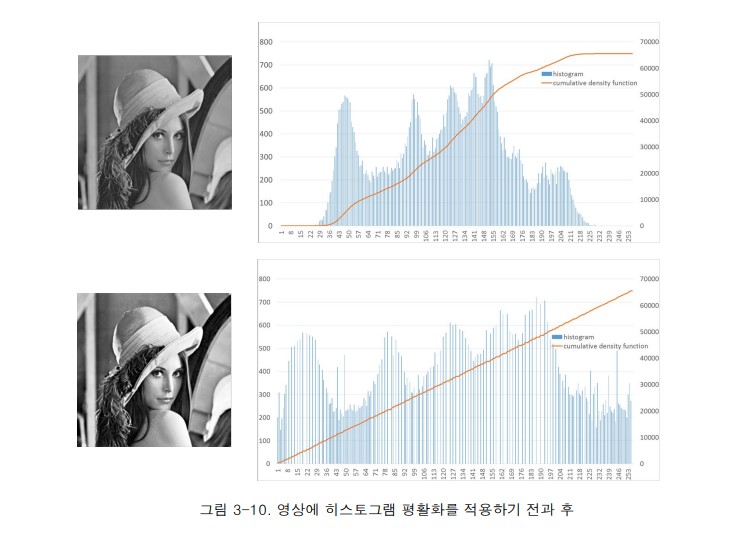
히스토그램 누적 분포함수를 선형함수로 만들면, 그것이 히스토그램 평활화가 된다.
히스토그램 평활화를 하게 되면 0~255 까지 모든 벨류값을 고르게 가져가고 있어서 이미지가 개선되었다고 말을 한다. 그러나 때로는 주관적인 판단에서 사람들은 무조건 평활화된 영상을 더 화질이 좋다고 느끼지 않을수도 있다.
그래서 히스토그램 매칭을 한다.
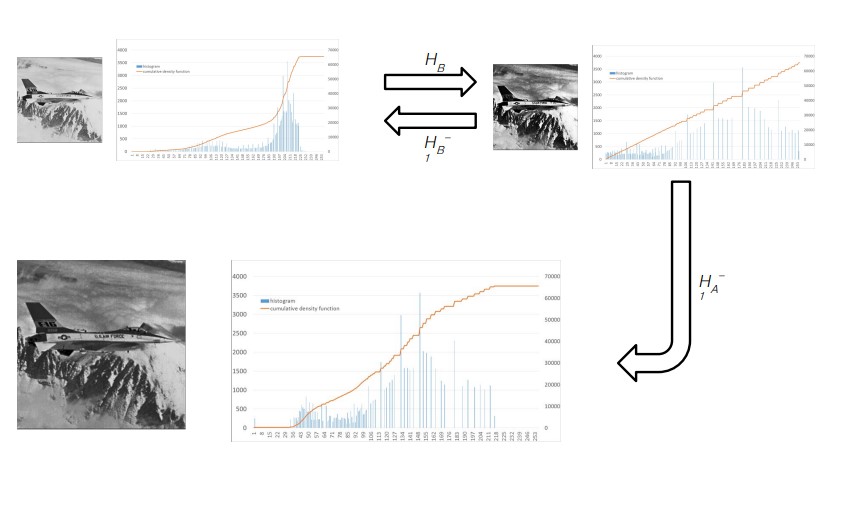
히스토그램 누적 분포함수를 무조건 선형 함수로 만드는 것이 아니라, 원본 사진의 경향성을 따르면서 히스토그램 스트레칭을 시켜준다. (이 과정에서 평활화된 히스토램에 히스토그램 변환함수를 이용하여 역 평활화를 위한 역 변환함수를 구해야 한다.)
감마보정
인간은 0~255 밝기 영역에서 중간 밝기 영역의 밝기변화에 상대적으로 민감하다.
적절한 감마값을 주면 영상 포화없이 감마보정을 통해 영상의 밝기를 조절할 수 있게 된다.(감마값을 지나치게 크게 주면 영상포화가 일어나서 데이터 손실이 발생할 수도 있다.)
신호를 처리하던 convolution가 이미지에도 적용된 경위
주파수 축에서의 convolution(합성곱) 표현
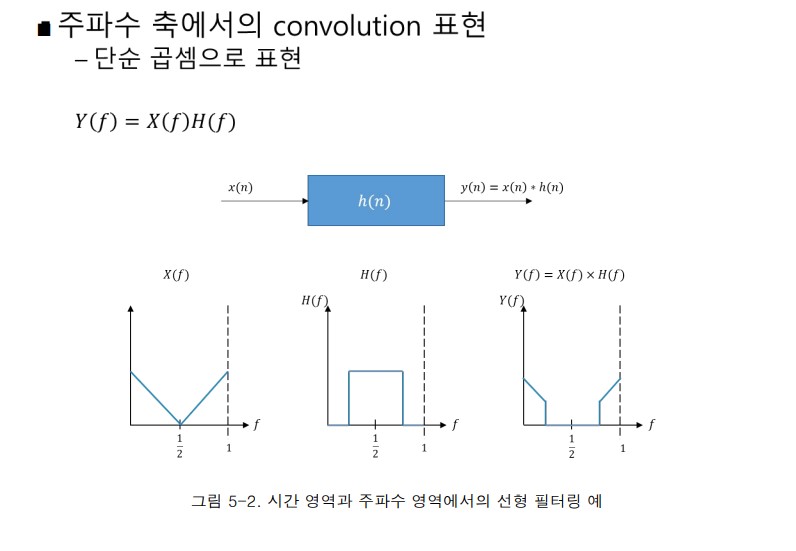
위 양상을 시스템에도 적용 가능하겠더라는 아이디어
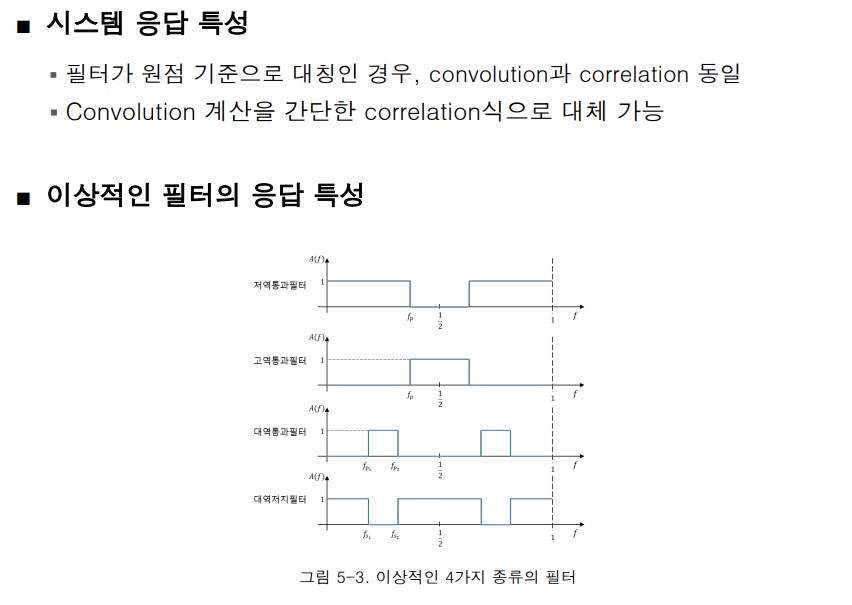
- 가우시안 필터를 쓰면 blur가 되기 때문에 날카로운 값이 억제된다.
- 영상에서는 델타y가 1이기 때문에 계산이 쉽다.
- 라플라시안 필터는 2차미분의 특성을 활용하여 zero-crossing 모델링을 구현했다.
이미지 프로세싱
이미지 프로세싱에서 정량적 수치 판단은 레거시코드가 잘되어 있다.
AI가 영상처리에 뛰어난 것은 사실이지만, 아직 정량적 수치 판단 측면에서는 레거시코드가 강점을 보인다.
SC231n의 python tutorial
-
파이썬의 클래스
python은 인터프리터 언어이기 때문에 클래스가 언제 생성되고 소멸될지를 모른다. 그래서 python에서 클래스는 항상 파라미터에 self를 넣어서 모든걸 만들게 된다. self는 일종의 C++에서의 this의 개념이며, 전역공간에서 관리되고 있는 객체포인터이다.(C계열 언어에서는 지양하는 방법이지만, python은 인터프리터언어의 특성상 저렇게 클래스를 구현할 수 밖에 없었다.) -
픽셀단위 연산의 한계
지금 우리가 배우고 있는 C++에서의 필터링은 전부 픽셀단위로 작동하고 있다. 우선 C++에서 픽셀-level에서 기본 동작의 개념을 익히는 작업을 하고 있는 것이다. 그런데 만약 영상의 해상도가 높아지면 높아질수록 도저히 픽셀단위 연산으로는 영상 필터링 작업이 불가능해지는 시점이 온다. 그때 이제 픽셀-level을 벗어나서 Matrix단위로 빵빵 계산을 찍어낼 필요가 생기는데, 그때 강력한 강점을 보이는 것이 바로 python의 numpy를 이용한 영상처리이다.
즉, 우리가 지금 C++로 openCV 여러 알고리즘들을 직접 만들어보고 하는 작업들은 전부 기초 동작 원리를 이해하고 제반지식을 이해하는 훈련을 하기 위함이다. 진짜 판은 python에서 벌어진다.
C++의 타입캐스팅을 쓰자.
습관적으로 쓰던 (type) 붙이기 식의 C 스타일의 타입캐스팅을 쓰지 말자.
C++에서의 타입캐스팅을 쓰자. (참고자료)
- static_cast< >
- dynamic_cast< >
- const_cast< >
- reinterpret_cast< >
