기본 데이터 타입
string(문자열)
- 복수개의 문자를 순서대로 나열 한 것
- 문자열은 '(작은따옴표)' 혹은 "(큰따옴표)" 사이에 문자를 넣어서 생성
- 문자열 자체에 ',"가 있는 경우에는 각각 그 반대의 기호를 생성
a = '"Hello" World'
b = "Hello' World"
"It's wonderful world"c = '''Hello
World'''
d = """Hello
World"""escape string (이스케이프 문자)
- 문자열내의 일부 문자의 의미를 달리하여 특정한 효과를 주는 것
\n: new line\t: tab 등
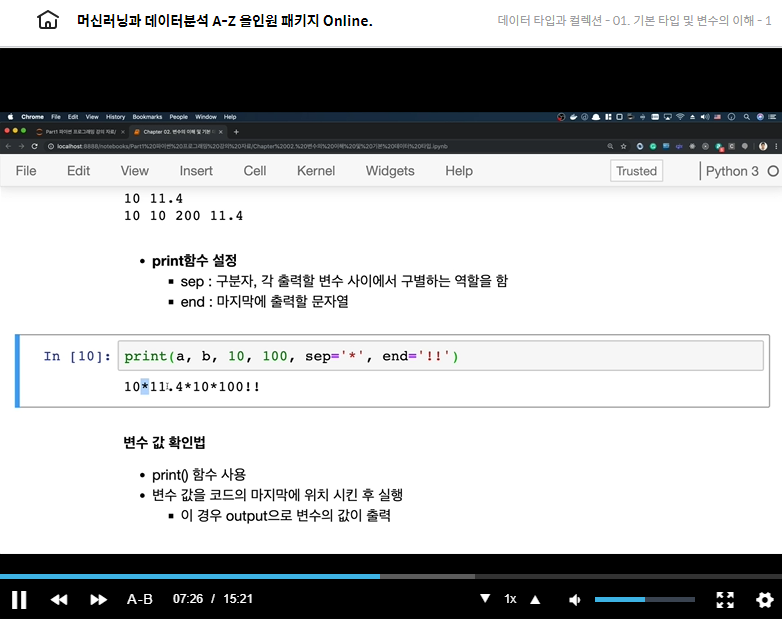
print('Hello World\n\n')
print('ha\thahaha')indexing & slicing string (문자열 인덱스 및 추출)
- 문자열의 각 문자는 순서가 있음
- 이때 각 문자열의 순서를 인덱스 라고 함
- 첫번째 문자부터 마지막까지 차례대로의 순서를 가짐
- 첫번째 시작문자의 순서는 0으로 시작
- -1이 가장 마지막 인덱스, -2가 마지막에서 두번째 인덱스
인덱스의 범위
- 인덱스는 [0,문자열의 길이)의 범위만 유효
- 범위를 넘어갈 경우 에러 발생
문자열 슬라이싱
- 부분 문자열 추출 가능
- [시작:끝]와 같이 명시하여 [시작,끝)에 해당하는 부분 문자열 추출
- 시작, 끝 인덱스가 생략이 되어 있다면, 0부터 혹은 끝까지로 간주
a = 'Hello World'
print(a[0:11]) # Hello World
print(a[0:1]) # H
print(a[:5]) # Hello
print(a[3:]) # lo World
print(a[:]) # Hello World문자열 함수
- upper
- 대문자로 변경
a = 'hello world'
a.upper() # 'HELLO WORLD'- replace
- 문자열 내의 특정 문자를 치환
a = 'hello world'
a.replace('h', 'j') # 'jello world'- format
- 문자열내의 특정한 값을 변수로부터 초기화하여 동적으로 문자열을 생성
temperature = 25.5
prob = 80.0
a = '오늘 기온은{}도 이고, 비올 확률은 {}% 입니다.'.format(temperature, prob)
print(a) # 오늘 기온은25.5도 이고, 비올 확률은 80% 입니다.- split
- 문자열을 특정한 문자를 기준으로 구분하여 문자열의 리스트로 치환
a = 'hello world what a nice weather'
a.split('w') # ['hello ', 'orld ', 'hat a nice ', 'eather']컬렉션 타입
리스트 & 튜플
- 복수개의 값을 담을 수 있는 데이터 구조
- list - mutable(생성된 후에 변경 가능)
- tuple - immutable(생성된 후에 변경 불가능)
리스트 초기화
- [] 안에 값을 담아서 생성
- list() 함수로 생성
- str.split()함수로 생성
a = []
b = [1,2,3,4,5,6]
c = ['korea','canada',1,23,[34,56]]a = 'hello world'
b = list(a)
c = (1,2,3)
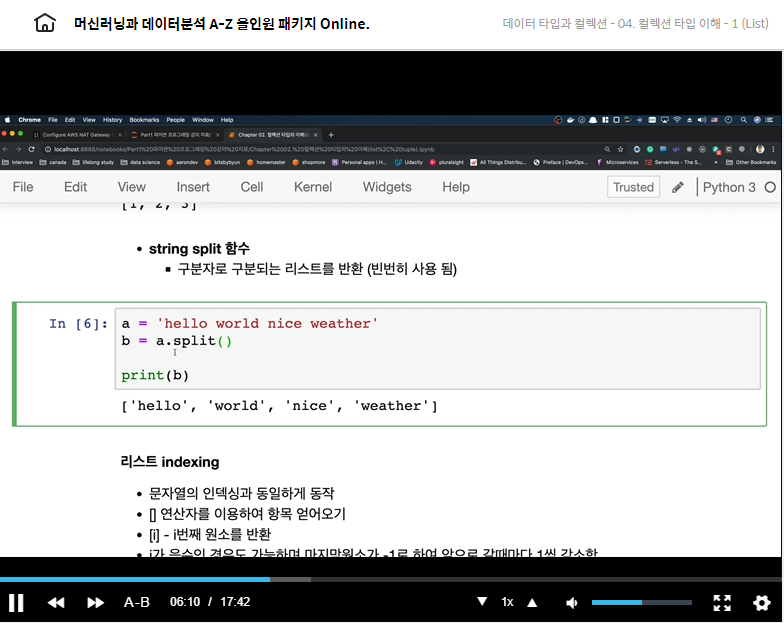
d = list(c)a = 'hello world nice weather'
b = a.split()
print(b) # ['hello', 'world', 'nice', 'weather']리스트 인덱싱
- 문자열의 인덱싱과 동일하게 동작
- [] 연산자를 이용하여 항목 얻어오기
- [i] - i번째 원소를 반환
- i가 음수인 경우도 가능하며 마지막원소가 -1로 하여 앞으로 갈때마다 1씩 감소함
리스트 슬라이싱
- 문자열 슬라이싱과 동일하게 동작
- 슬라이싱의 결과 역시 list
list 멤버함수
- append
- 리스트의 끝에 항목을 추가함
a = [1, 2, 3, 4, 5]
a.append(10)
print(a) # [1, 2, 3, 4, 5, 10]- extend
- 리스트를 연장
- +=로도 가능
a = [1, 2, 3, 4, 5]
b = [6, 7, 8, 9, 10]
a.extend(b) # a += b
print(a) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]- insert
- 리스트의 원하는 위치에 추가 가능
- 앞에 인덱스를, 뒤에 아이템을 명시
a = [1, 3, 4, 5, 6]
a.insert(1, 40)
print(a) # [1, 40, 3, 4, 5, 6]- remove
- 값으로 항목 삭제
a = [1, 2, 30, 30, 4, 5]
a.remove(4) # [1, 2, 30, 30, 5]
print(a)- pop
- 지우고자 하는 아이템을 반환 후, 삭제
a = [1, 2, 3, 4, 5]
d = a.pop(2)
print(a) # [1, 2, 4, 5]
print(d) # 3- index
- 찾고자 하는 값의 인덱스 반환
a = [2, 6, 7, 9, 10]
a.index(9) # 3- in 키워드
- 리스트 내에 해당 값이 존재하는지 확인
- value in list
- True, False 중 한가지로 반환
a = [1, 2, 3, 4, 5, 10]
b = 10
c = b in a
print(c) True- list 정렬
- sort() → 리스트 자체를 내부적으로 정렬
- sorted() → 리스트의 정렬된 복사본을 반환
a = [9, 10, 7, 19, 1, 2, 20, 21, 7, 8]
a.sort(reverse=True)
b = sorted(a)
print(a) # [21, 20, 19, 10, 9, 8, 7, 7, 2, 1]
print(b) # [1, 2, 7, 7, 8, 9, 10, 19, 20, 21]tuple
- 리스트와 같이 복수개의 값을 갖는 컬렉션 타입
- 생성된 후 변경이 불가능
a = [1, 2, 3]
b = (1, 2, 3)
print(type(a)) # <class 'list'>
print(type(b)) # <class 'tuple'>
a[0] = 100
print(a) # [100, 2, 3]
b[0] = 100 # error
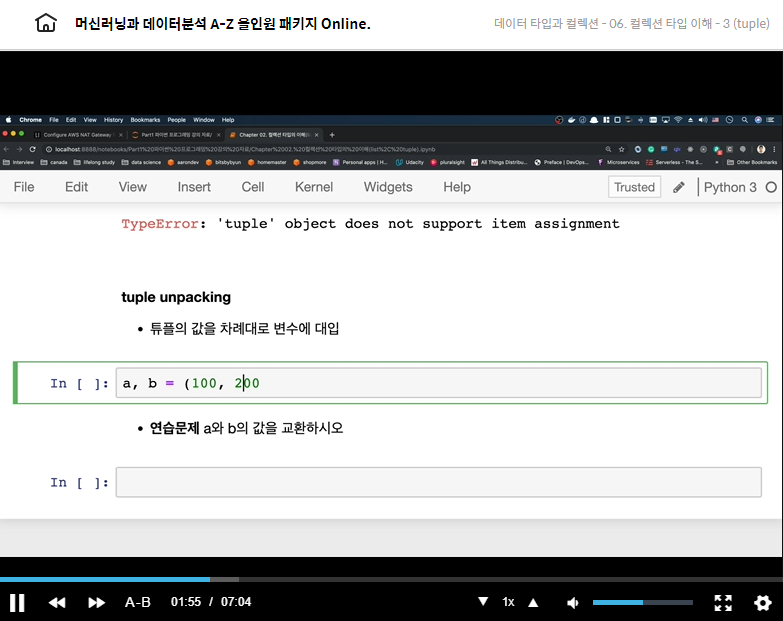
print(b)tuple unpacking
a, b, c, d = 100, 200, 300, 400
print(a, b, c, d) # 100 200 300 400a = 5
b = 4
print(a, b) # 5 4
a, b = b, a
print(a, b) # 4 5머신러닝과 데이터 분석 A-Z 올인원 패키지 Online. 👉 https://bit.ly/3cB3C8y
