

딥러닝 주요 모델
Neural Network
- 입력, 은닉, 출력층으로 구성된 모형으로서 각 층으로 연결하는 노드의 가중치를 업데이트하면서 학습
- Overfitting이 심하게 일어나고 학습시간이 매우 오래걸림
Deep Learning
- 다층의 layer를 통해 복잡한 데이터의 학습이 가능토록 함(graphical representation learning)
- 알고리즘 및 GPU의 발전이 deep learning의 부흥을 이끔
이미지 분류에서 기존 모델
- 각각의 픽셀 값(늘어뜨려서)을 독립변수로 사용
- 독립변수들은 각각 독립이라는 기본적인 가정에서 어긋남
Convolutional Neural Network
- 이미지의 지역별 feature를 뽑아서 neural network학습
Deep Learning
- 다양한 형태로 발전(CNN, RNN, AutoEncoder 등)
- 다양한 분야로 발전
- Object detection
- Image Resolution
- Style transfer
- colorization
- 네트워크 구조의 발전(ResNet, DenseNET 등)
- 네트워크 초기화 기법(Xavier, he initialization 등)
- 다양한 activation function(ReLu, ELU, SeLU, Leaky ReLU 등)
- Generalization, overfitting에 관한 문제
- Semi-supervised learning, Unsupervised learning
GAN(Generative Adversarial Network)
Data를 만들어내는 Generator와 만들어진 data를 평가하는 Discriminator가 서로 대립(Adversarial)적으로 학습해가며 성능을 점차 개선해 나가자는 개념
- Discriminator를 학습시킬 때에는 D(X)가 1이 되고 D(G(z))가 0이 되도록 학습시킴
(진짜 데이터를 진짜로 판별하고, 가짜데이터를 가짜로 판별할 수 있도록) - Generator를 학습시킬 때에는 D(G(z))가 1이 되도록 학습시킴
(가짜 데이터를 disxriminator가 구분못하도록 학습, discriminator를 헷갈리게 하도록)
강화학습(Reinforcement Learning)
- Q-learning : 현재 상태에서부터 먼 미래까지 가장 큰 보상을 얻을 수 있는 행동을 학습하게 하는 것
- Q-learning + Deep Learning : DQN(Deep Reinforcement Learning)
Deep Reinforcement Learning
- 더 효율적으로 빠르게 학습 할 수 있는 강화학습 모델
- Action이 continuous한 경우
- Reward가 매우 sparse한 경우
- Multi agent 강화학습 모델
모형의 적합성 평가 및 실험 설계
모형의 적합성을 평가하는 방법
- 모형의 복잡도에 따른 학습 집합의 MSE와 검증 집합의 MSE의 변화는 아래 그림과 같음
- 학습 집합의 MSE는 복잡한 모형일수록 감소하지만, 학습 데이터가 아닌 또 다른 데이터(검증 데이터)의 MSE는 일정 시점 이후로 증가
- 증가하는 원인은 왼쪽 그림과 같이 모형이 학습 집합에 과적합되기 때문
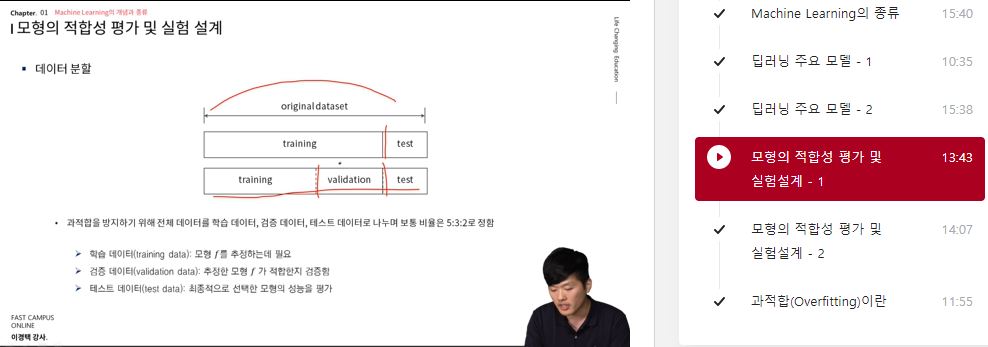
데이터 분할
- 과적합을 방지하기 위해 전체 데이터를 학습 데이터, 검증 데이터, 테스트 데이터로 나누며 보통 비율은 5:3:2로 정함
학습 데이터(training data) : 모형 를 추정하는데 필요
검증 데이터(validation data) : 추정한 모형 가 적합한지 검증함
테스트 데이터(test data) : 최종적으로 선택한 모형의 성능을 평가
1. 데이터 분할
- 전체 데이터를 학습 데이터, 검증 데이터, 테스트 데이터로 나눔
2. 모형학습
- 학습 데이터를 사용하여 각 모형을 학습함
3. 모형 선택
- 검증 데이터를 사용하여 각 모형의 성능을 비교하고 모형 선택
4. 최종 성능 지표 도출
- 테스트 데이터를 사용하여 검증 데이터로 도출한 최종 모델의 성능 지표를 계산함
k-Fold 교차검증(k-Fold Cross Validation)
- 모형의 적합성을 보다 객관적으로 평가하기 위한 방법
- 데이터를k(주로 5 또는 10)개 부분으로 나눈 뒤, 그 중 하나를 검증 집합, 나머지를 학습 집합으로 분류
- 위 과정을 k번 반복하고 k개의 성능 지표를 평균하여 모형의 적합성을 평가
LOOCV(Leave-One-Out Cross Validation)
- 데이터의 수가 적을 때 사용하는 교차검증 방법
- 총 (데이터 수 만큼)개의 모델을 만드는데, 각 모델은 하나의 샘플만 제외하면서 모델을 만들고 제외한 샘플로 성능 지표를 계산함. 이렇게 도출된 개의 성능 지표를 평균 내어 최종 성능 지표를 도출
데이터 분석과정
raw데이터 -> 전처리 된 데이터 -> 실험설계 -> Model
전처리
- Raw데이터를 모델링 할 수 있도록 데이터를 병합 및 파생 변수 생성
실험설계
- 실험설계에서 test데이터는 실제로 우리는 모델을 적용을 한다는 가정하여야 함
- Train, validation 데이터에 test정보는 없어야 함
과적합(Overfitting)이란
과적합이란
- 복잡한 모형일수록, 데이터가 적을수록 과적합이 일어나기 쉬움
- 아래 그림은 회귀분석에서 고차항을 넣었을때 만들어지는 직선
- 과적합은 data science 뿐만 아니라 AI전반적으로 매우 큰 이슈
분산(Variance)과 편파성(Bias)의 트레이드오프(Tradeoff)(Dilemma)
-
모형 로 모집단의 전체 데이터를 예측할 때 발생하는 총 error를 계산하면 reducible error와 irreducible error로 표현되며, reducible error는 다시 분산과 편파성으로 구성
-
분산 : 전체 데이터 집합 중 다른 학습 데이터를 이용했을 때, 이 변하는 정도(복잡한 모형일수록 분산이 높음)
-
편파성 : 학습 알고리즘에서 잘못된 가정을 했을 때 발생하는 오차(간단한 모형일수록 편파성이 높음)
-
복잡한 모형 을 사용하여 편파성을 줄이면, 반대로 분산이 커짐(간단한 모형일 경우엔 반대의 현상이 발생
-
따라서 분산과 편파성이 작은 모형을 찾아야 함
머신러닝과 데이터 분석 A-Z 올인원 패키지 Online. 👉 https://bit.ly/3cB3C8y
