
들어가며
알림 시스템은 최근 많은 프로그램에서 채택하는 인기 있는 기능이다. 최신 뉴스, 제품 업데이터, 이벤트, 선물 등 고객에게 중요할 만한 정보를 비동기적으로 제공한다.
이러한 알림 시스템을 순차적으로 확장하며 설계해보려 한다.
1단계. 문제 이해 및 설계 범위 확정
하루에 백만건 이상의 알림을 처리하는 확장성 높은 시스템을 구축하는게 쉬운 과제가 아니다. 알림 시스템이 어떻게 구현되는지에 대한 깊은 이해가 필요한 작업이다.
이에 관한 문제가 면접에 출제될 때는 보통 정해진 정답이 없고, 문제 자체가 모호하게 주어지는 것이 일반적이므로, 적절한 질문을 통해 요구사항이 무엇인지 우리가 스스로 알아내야 한다.
- 지원자 : 이 시스템은 어떤 종류의 알림을 지원해야 하나요?
- 면접관 : 푸시 알림, SMS 메시지, 그리고 이메일입니다.
- 지원자 : 실시간 시스템이어야 하나요?
- 면접관 : 연성 실시간(soft real-time) 시스템이라고 가정합니다. 알림은 가능한 빨리 전달되어야 하지만, 시스템에 높은 부하가 걸렸을 때 약간의 지연은 무방합니다.
- 지원자 : 어떤 종류의 단말을 지원해야 하나요?
- 면접관 : ios 단말, 안드로이드 단말, 그리고 랩탑/데스크탑을 지원해야 합니다.
- 지원자 : 사용자에게 보낼 알림은 누가 만들 수 있나요?
- 면접관 : 클라이언트 애플리케이션 프로그램이 만들 수도 있고, 서버 측에서 스캐줄링 할 수도 있습니다.
- 지원자 : 사용자가 알림을 받지 않도록 설정할 수도 있어야 하나요?
- 면접관 : 네. 해당 설정을 마친 사용자는 더 이상 알림을 받지 않습니다.
- 지원자 : 하루에 몇 건의 알림을 보낼 수 있어야 하나요?
- 면접관 : 천만 건의 모바일 푸시 알림, 백만 건의 SMS 메시지, 5백만 건의 이메일을 보낼 수 있어야 합니다.
2단계. 개략적 설계안 제시 및 동의 구하기
iOS 푸시 알림, 안드로이드 푸시 알림, SMS 메시지, 이메일을 지원하는 알림 시스템의 개략적 설계안을 만들어보자.
- 알림 유형별 지원 방안
- 연락처 정보 수집 절차
- 알림 전송 및 수신 절차
알림 유형별 지원 방안
iOS 푸시 알림
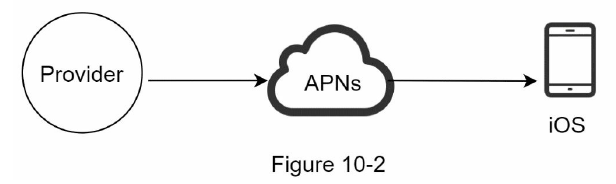
iOS에서 푸시 알림을 보내기 위해서는 3가지 컴포넌트가 필요하다.
알림 제공자(provider): 알림 요청을 만들어 애플 푸시 알림 서비스(APNS)로 보내는 주체.
알림 요청을 위해 필요한 데이터는 다음과 같다
-
(a) 단말 토큰: 알림 요청을 보내는 데 필요한 고유 식별자
-
(b) 페이로드: 알림 내용을 담은 JSON 딕셔너리
ex)
{ "aps":{ "alert": { "title": "Game Request", "body": "Bob wants to play chess", "action-loc-key": "PLAY" }, "badge": 5 }
APNS: 애플이 제공하는 원격 서비스. 푸시 알림을 iOS 장치로 보내는 역할
iOS 단말: 푸시 알림을 수신하는 사용자 단말
안드로이드 푸시 알림
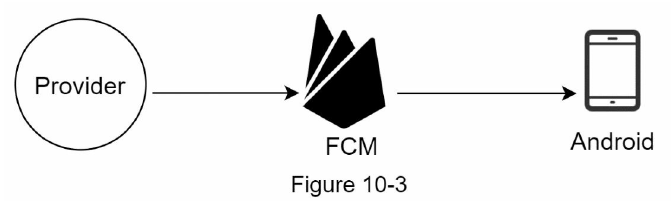
안드로이드 푸시 알림도 비슷하다. APNS 대신 FCM(Firebase Cloud Messaging)을 사용한다.
SMS 메시지
SMS 메시지를 보낼 때는 보통 트윌리오, 넥스모 같은 제 3 사업자의 서비스를 많이 이용한다.
이메일

대부분의 회사는 고유 이메일 서버를 구축할 역량은 갖추고 있다. 그럼에도 많은 회사가 상용 이메일 서버를 이용한다. 그 중 유명한 서비스로 센드그리드, 메일침프가 있다. 전송 성공률도 높고, 데이터 분석 서비스도 제공한다.
연락처 정보 수집 절차

알림을 보내려면 모바일 단말 토큰, 전화번호, 이메일 주소 등의 정보가 필요하다. 사용자가 우리 앱을 설치하거나 처음으로 회원가입 하면 API 서버는 해당 사용자의 정보를 수집하여 데이터베이스에 저장한다.
이 데이터베이스에 연락처 정보를 저장할 테이블 구조는 다음과 같다.
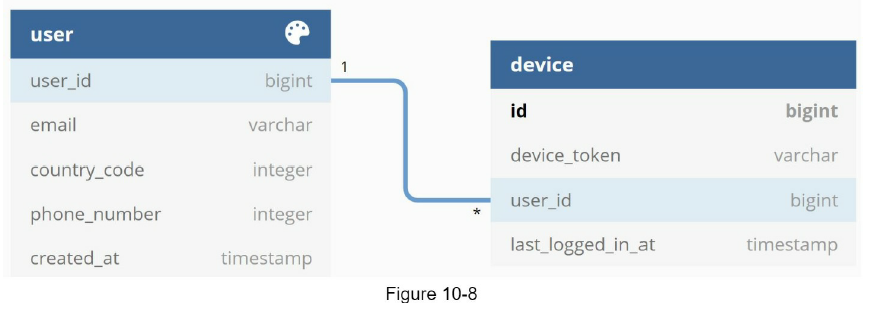
이메일 주소와 전화번호는 user 테이블에 저장, 단말 토큰은 device 테이블에 저장한다.
한 사용자가 여러 단말을 가질 수 있고, 알림은 모든 단말에 전송되어야 한다는 점을 고려하였다.
알림 전송 및 수신 절차
개략적인 설계안부터 최적화해 나가보자.
개략적인 설계안 (초안)
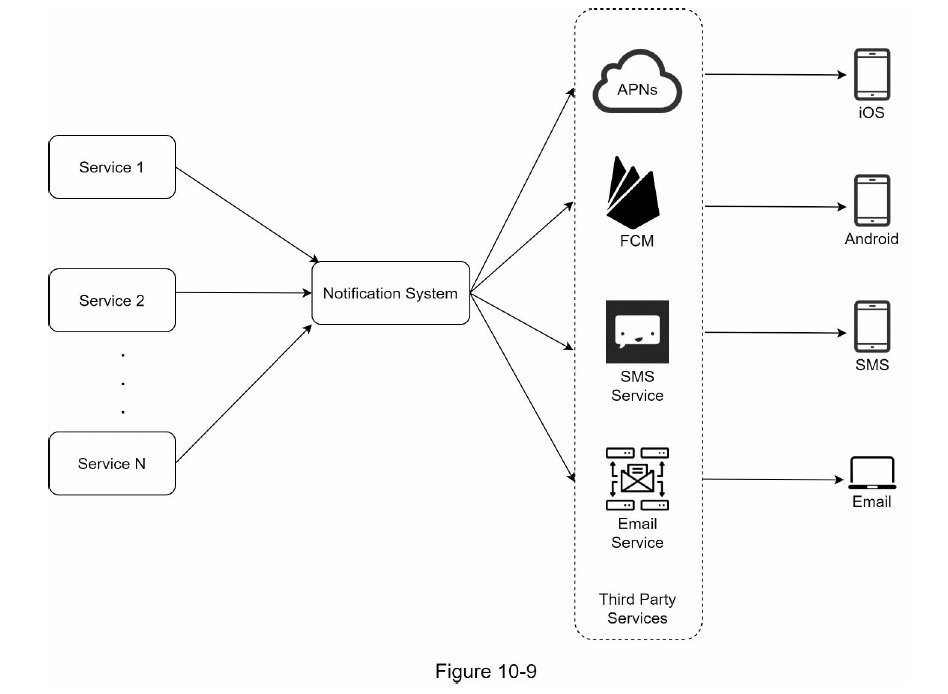
위 그림 10-9는 개략적 설계 초안이다.
-
1~N까지의 서비스 : 이 서비스 각각은 MSA 일 수도 있고, CronJob 일 수도 있고, 분산 시스템 컴포넌트 일 수도 있다. 사용자에게 납기일을 알리고자 하는 과금 서비스, 배송 알림을 보내려는 쇼핑몰 웹 사이트 등이 그 예시다.
-
알림 시스템 : 알림 시스템은 알림 전송/수신 처리의 핵심이다. 우선 1개 서버만 사용하는 시스템이라고 가정해보자. 이 시스템은 서비스 1~N에 알림 전송을 위한 API 를 제공해야 하고, 제 3자 서비스에 전달할 알림 페이로드(payload) 를 만들어 낼 수 있어야 한다.
-
제 3자 서비스 (third party service) : 이 서비스들은 사용자에게 알림을 실제로 전달하는 역할을 한다. 제 3자 서비스와의 통합을 진행할 때 유의할 것은 확장성이다. 쉽게 새로운 서비스를 통합하거나 기존 서비스를 제거할 수 있어야 한다는 뜻이다. 또 하나 고려해야 할 점은, 어떤 서비스는 다른 시장에서는 사용 못 할 수도 있다는 점이다. 따라서 중국 시장에서는 제이푸시, 푸시와이 같은 서비스를 사용해야만 한다.
-
ios, 안드로이드, SMS, 이메일 단말 : 사용자는 자기 단말에서 알림을 수신한다.
문제점
하지만, 위 설계에는 몇 가지 문제점이 존재한다.
-
SPOF (Single-Point-Of-Failure) : 알림 서비스에 서버가 1대밖에 없기 때문에, 알림 서비스에 장애가 발생하면 전체 서비스의 장애로 이어진다.
-
규모 확장성 : 1대의 서비스로 푸시 알림에 관계된 모든 것을 처리하므로, 데이터베이스나 캐시 등 중요 컴포넌트의 규모를 개별적으로 늘릴 방법이 없다.
-
성능 병목 : 알림을 처리하고 보내는 것은 자원이 많이 필요한 작업이다.
예를들어 HTML 페이지를 만들고 서드파티 서비스의 응답을 기다리는 일은 시간이 많이 걸릴 가능성이 있는 작업이다. 따라서 모든 것을 한 서버로 처리하면 사용자 트래픽이 많이 몰리는 시간에는 시스템이 과부하 상태에 빠질 수 있다.
개략적 설계안 (개선된 버전)
아래 그림과 같이 개선할 수 있다.
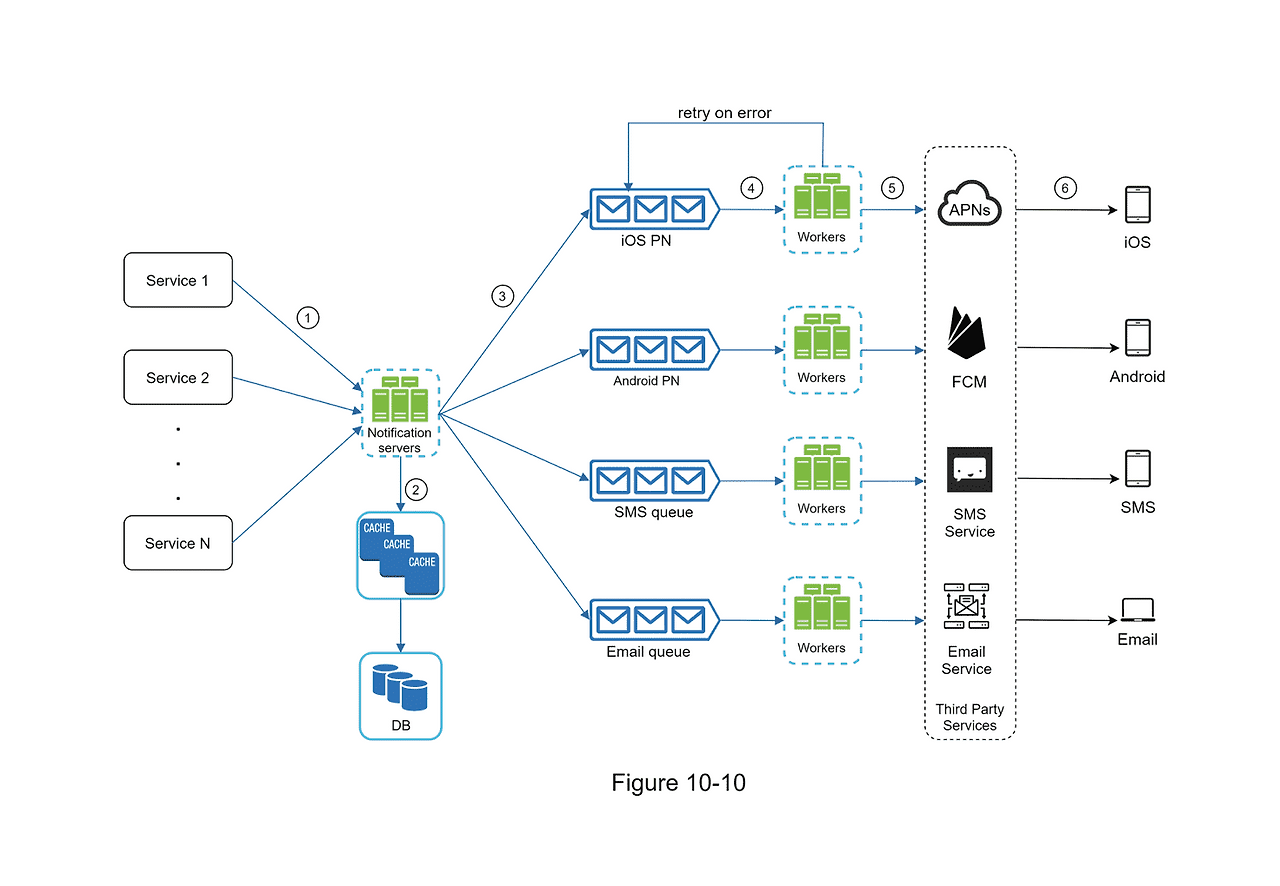
개선점
- 데이터베이스와 캐시를 알림 시스템의 주 서버에서 분리하였다.
- 알림 서버를 증설하고 자동으로 수평적 규모 확장(Scale Out) 이 이루어질 수 있도록 개선하였다.
- 메시지 큐를 이용해 시스템 컴포넌트 사이의 강한 결합을 끊었다.
각 컴포넌트의 역할
-
1부터 N까지의 서비스 : 알림 시스템 서버의 API 를 통해 알림을 보낼 서비스들
-
알림 서버
- 알림 전송 API : 스팸 방지를 위해 보통 사내 서비스 또는 인증된 클라이언트만 이용 가능하다.
- 알림 검증(validation) : 이메일 주소, 전화번호 등에 대한 기본적 검증을 수행한다.
- 데이터베이스 또는 캐시 질의 : 알림에 포함시킬 데이터를 가져오는 기능이다.
- 알림 전송 : 알림 데이터를 메시지 큐에 넣는다. 본 설계안의 경우 하나 이상의 메시지 큐를 사용하므로 알림을 병렬적으로 처리할 수 있다.
-
캐시 : 사용자 정보, 단말 정보, 알림 템플릿 등을 캐싱한다.
-
데이터베이스 : 사용자, 알림, 설정 등 다양한 정보를 저장한다.
-
메시지 큐 : 시스테 컴포넌트 간 의존성을 제거하기 위해 사용한다. 다량의 알림이 전송되어야 하는 경우를 대비한 버퍼 역할도 한다. 본 설계안에서는 알림의 종류별로 별도의 메시지 큐를 사용하였다. 따라서 서드파티 서비스 중 하나가 장애가 발생하더라도 다른 종류의 알림 기능은 정상 동작한다.
-
작업 서버 : 메시지 큐에서 전송할 알림을 꺼내서 서드파티 서비스로 전달하는 역할을 담당하는 서버
API 요청 플로우
-
API 를 호출하여 알림 서버로 알림을 보낸다.
-
알림 서버는 사용자 정보, 단말 토큰, 알림 설정 같은 메타데이터를 캐시나 데이터베이스에서 가져온다.
-
알림 서버는 전송할 알림 종류에 알맞는 이벤트를 만들어서 해당 이벤트를 위한 큐에 넣는다.
가령 ios 푸시 알림 이벤트는 ios 푸시 알림 큐에 넣어야 한다. -
작업 서버는 메시지 큐에서 알림 이벤트를 꺼낸다.
-
작업 서버는 알림을 서드파티 서비스로 전송한다.
-
서드파티 서비스는 사용자 단말로 알림을 전송한다.
3단계. 상세 설계
개략적 설계를 진행하면서 알림의 종류, 연락처 정보 수집 절차, 그리고 알림 송수신 절차에 대해 알아보았다. 이제 아래 내용들을 더 자세히 알아보자.
- 안정성
- 추가로 필요한 컴포넌트 및 고려사항 : 알림 템플릿, 알림 설정, 전송률 제한, 재시도 매커니즘, 보안, 큐에 보관된 알림에 대한 모니터링과 이벤트 추적 등
- 개선된 설계안
안전성
분산 환경에서 운영될 알림 시스템을 설계할 때는 안정성을 확보하기 위한 사항 몇가지를 반드시 고려해야한다.
데이터 손실 방지
알림 전송 시스템의 가장 중요한 요구사항 가운데 하나는 어떤 상황에서도 알림이 소실되면 안 된다는 것이다.
이 요구사항을 만족하려면 알림 시스템은 알림 데이터를 데이터베이스에 보관하고 재시도 메커니즘을 구현해야 한다.
아래 그림과 같이 알림 로그 데이터베이스를 유지하는 것이 한가지 방법이다.

알림 중복 전송 방지
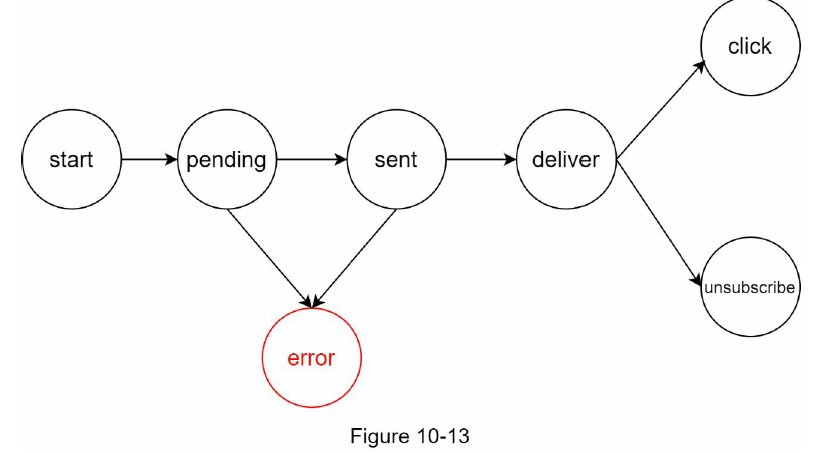
같은 알림이 여러 번 반복되는 것을 완전히 막는 것은 가능하지 않다.대부분의 경우 알림은 딱 한 번만 전송되겠지만, 분산 시스템의 특성상 가끔은 같은 알림이 중복되어 전송되기도 할 것이다. 그 빈도를 줄이려면 중복을 탐지하는 메커니즘을 도입하고, 오류를 신중하게 처리해야 한다. 다음은 간단한 중복 방지 로직의 예이다.
- 보내야 할 알림이 도착하면 그 이벤트 ID를 검사하여 이전에 본 적이 있는 이벤트인지 살핀다.
중복된 이벤트라면 버리고, 그렇지 않으면 알림을 발송한다.
분산 시스템에서 "정확히 한 번 전달" 논쟁: 불가능한가, 가능한가?
분산 시스템을 설계할 때 가장 어려운 문제 중 하나가 바로 메시지 전달 보장이다. 특히 "정확히 한 번 전달(exactly-once delivery)"에 대해서는 업계에서 오랫동안 치열한 논쟁이 벌어져 왔다. 관련 글을 통해 정리해봤다.
메시지 전달 방식의 종류
먼저 분산 시스템에서 제공할 수 있는 메시지 전달 방식을 정리해보자
(1) At-Most-Once (최대 한 번)
- 메시지가 0번 또는 1번 전달됨
- 메시지 손실 가능성 있음
- 중복 없음
- 높은 성능
(2) At-Least-Once (최소 한 번)
- 메시지가 1번 이상 전달됨
- 메시지 손실 없음
- 중복 가능성 있음
- 중간 성능
(3) Exactly-Once (정확히 한 번)
- 메시지가 정확히 1번만 전달됨
- 메시지 손실 없음
- 중복 없음
- 이론적으로 가장 이상적이지만 구현이 어려움
불가능론: 이론적 한계
Tyler Treat는 2015년 블로그에서 분산 시스템에서 정확히 한 번 전달이 원리적으로 불가능하다고 주장했다. 근거들은 다음과 같다.
1. Two Generals Problem과 FLP 결과
- 분산 시스템에서 완전한 합의(consensus) 달성의 근본적 한계
- 네트워크 파티션과 프로세스 실패가 항상 가능
*Two Generals Problem과 FLP 결과
Two Generals Problem (두 장군 문제)과 FLP 결과는 둘 다 분산 시스템에서 합의(consensus)를 이루는 것이 매우 어렵거나, 특정 조건에서는 불가능하다는 것을 보여주는 컴퓨터 과학의 중요한 개념입
[두 장군 문제]
신뢰할 수 없는 통신 환경에서 두 팀이 동시에 공격하는 것에 합의하는 것이 불가능하다는 것을 보여주는 비유적인 이야기다.
핵심: 마지막 확인 메시지가 전달되었다는 것을 절대 확신할 수 없기 때문에, 무한히 확인 메시지를 주고받는 딜레마에 빠져 결국 합의에 실패
[FLP 결과]
메시지 전달에 시간 제약이 없고(비동기), 최소 한 개 이상의 시스템에 장애가 발생할 수 있는 상황에서는 합의에 도달하는 결정론적인 알고리즘이 존재하지 않는다는 것을 수학적으로 증명한 정리
핵심: 이 결과 때문에 현실의 분산 시스템들은 FLP 정리의 전제를 피하기 위해 메시지 전송에 시간 제한을 두거나(동기), 실패 가능성을 허용하는 확률적인 방법을 사용한다2. 확인응답(ACK)의 딜레마
- Producer가 메시지를 보내고 ACK를 기다림
- ACK 자체도 네트워크에서 손실될 수 있음
- Producer는 메시지가 실제로 전달되었는지 확신할 수 없음
- 재전송 시 중복 가능성 발생
"현존하는 모든 메이저 메세지 큐가 exactly-once를 제공한다고 주장한다면, 그들이 거짓말을 하거나 분산 시스템을 이해하지 못하는 것이다."
이렇게 강한 결론으로 마무리 짓고 있다.
가능론: 실용적 해결책
2017년 Kafka는 Apache Kafka 0.11 버전에서 exactly-once 기능을 출시하며 반박했다. 구현 핵심 내용을 간단히 알아보자.
멱등성 프로듀서(Idempotent Producer)
// 설정 예시
producer.props.put("enable.idempotence", "true");- TCP와 유사한 시퀀스 번호 사용
- Broker가 중복 메시지를 자동으로 제거
- 단일 파티션 내에서 정확히 한 번 보장
트랜잭션(Transactions)
producer.initTransactions();
try {
producer.beginTransaction();
producer.send(record1);
producer.send(record2);
producer.commitTransaction();
} catch(ProducerFencedException e) {
producer.close();
} catch(KafkaException e) {
producer.abortTransaction();
}- 여러 파티션에 대한 원자적 쓰기
- Consumer 오프셋까지 포함한 트랜잭션 처리
Kafka Streams에서의 활용
// 간단한 설정으로 exactly-once 활성화
props.put(StreamsConfig.PROCESSING_GUARANTEE_CONFIG,
StreamsConfig.EXACTLY_ONCE);성능상 결과는 멱등성 프로듀서는 성능 영향 거의 없고, 트랜잭션은 at-least-once 대비 3% 성능 감소가 있어 사실상 성능 손실이 거의 없다.
2025 현재 상황
Kafka의 exactly-once 기능은 지속적으로 발전하고 있다. 현재 많은 기업에서 Kafka의
exactly-once기능을 프로덕션 환경에서 성공적으로 사용하고 있다.
알림 시스템에서의 현실적 접근
1. 이벤트 ID로 중복 체크
만약 (이 알림을 이전에 본 적이 있다면) {
무시하고 버리기
} 아니면 {
알림 보내기
}2. 사용자 경험 우선 설계
- 중요한 알림을 놓치는 것 > 가끔 중복되는 것
- 사용자는 중복 알림보다 놓친 알림에 더 민감함
3. 클라이언트에서 추가 방어
- 앱에서 같은 내용의 알림이 짧은 시간에 여러 개 오면 하나만 표시
- 완벽하지 않더라도 사용자 경험은 보장
결론: 완벽함보다 실용성
분산 시스템에서 100% 완벽한 "정확히 한 번 전달"은 이론적으로 불가능할 수 있다. 하지만 현실에서는 99.9% 정확도로도 충분히 훌륭한 시스템을 만들 수 있다.
중요한 것은 완벽한 이론보다는 사용자에게 도움이 되는 실용적 해결책을 찾는 것이다.
추가로 필요한 컴포넌트 및 고려사항
-
알림 템플릿 : 알림 템플릿은 유사성을 고려하여 알림 메시지의 모든 부분을 처음부터 다시 만들 필요 없도록 해 준다.

-
알림 설정
- 사용자는 너무 많은 알림을 받으면 피곤함을 느낀다. 따라서 사용자가 알림 설정을 상세히 조정할 수 있도록 한다.
- 이 정보는 알림 설정 테이블에 보관되며, 이 테이블에는 다음과 같은 필드들이 필요할 것이다.

-
전송률 제한 : 사용자에게 너무 많은 알림을 보내지 않도록 하는 한 가지 방법은, 한 사용자가 받을 수 있는 알림의 빈도를 제한하는 것이다.
-
재시도 방법
- 제3자 서비스가 알림 전송에 실패하면, 해당 알림을 재시도 전용 큐에 넣는다.
- 같은 문제가 계속해서 발생하면 개발자에게 통지한다.
- 푸시 알림과 보안 : IOS와 안드로이드 앱의 경우, 알림 전송 API는
appKey와appSecret을 사용하여 보안을 유지한다.
- 큐 모니터링
- 알림 시스템을 모니터링 할 때 중요한 메트릭 하나는 큐에 쌓인 알림의 개수이다.
- 이 수가 너무 크면 작업 서버들이 이벤트를 빠르게 처리하고 있지 못하다는 뜻이다.
그런 경우에는 작업 서버를 증설하는 게 바람직할 것이다.
-
이벤트 추적
- 알림 확인율, 클릭율, 실제 앱 사용으로 이어지는 비율 같은 메트릭은 사용자를 이해하는데 중요하다.
- 데이터 분석 서비스는 보통 이벤트 추적 기능도 제공한다. 따라서 보통 알림 시스템을 만들면 데이터 분석 서비스와도 통합해야만 한다.
수정된 설계안
모두 반영해 수정한 설계안이다.
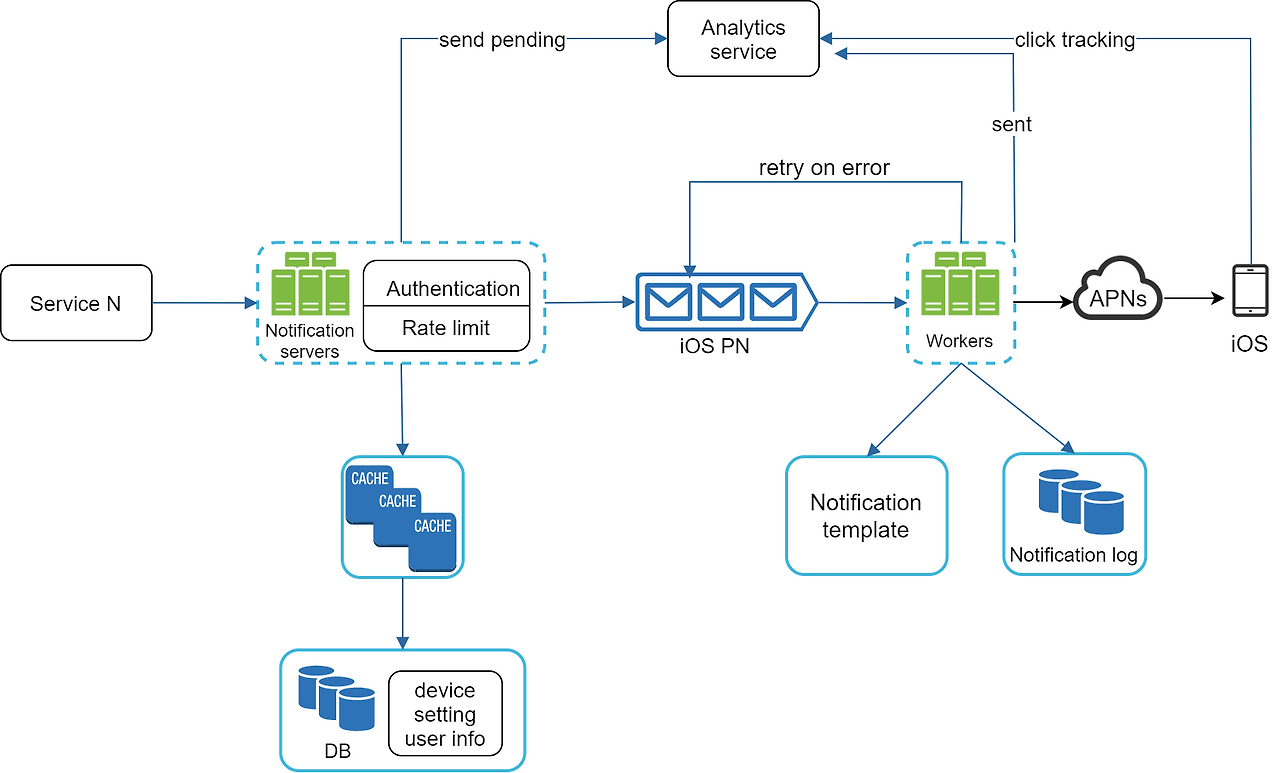
- 알림 서버에 전송률 제한 기능이 추가 되었으며, 전송 실패에 대응하기 위해 재시도 기능이 추가되었다.
- 전송에 실패한 알림은 다시 큐에 넣고 지정된 횟수만큼 재시도한다.
- 전송 템플릿을 사용하여 알림 생성 과정을 단순화하고 알림 내용의 일관성을 유지한다.
- 모니터링과 추적 시스템을 추가하여 시스템 상태를 확인하고 추후 시스템을 개선하기 쉽도록 하였다.
References
