문제
프로덕션 환경에서의 Elasticache(Redis) 문제로 외부 메시지 발송 작업이 작동되지 않았다.
진단
AWS 공식문서를 보면 아래와 같이 조치하라고 하고 있다.
- 노드에서 키의 TTL 값을 설정합니다.
- 다른 maxmemory-policy 파라미터를 사용하도록 파라미터 그룹을 업데이트합니다.
- 수동으로 기존의 몇 개 키를 삭제하여 메모리를 확보합니다.
- 더 큰 노드 유형을 선택합니다.
참고: 해결 방법을 정확히 어떻게 조합할지는 각 사용 사례에 따라 달라집니다.메모리, CPU 상태를 점검해 봤다.
- 메모리 사용률 🥺
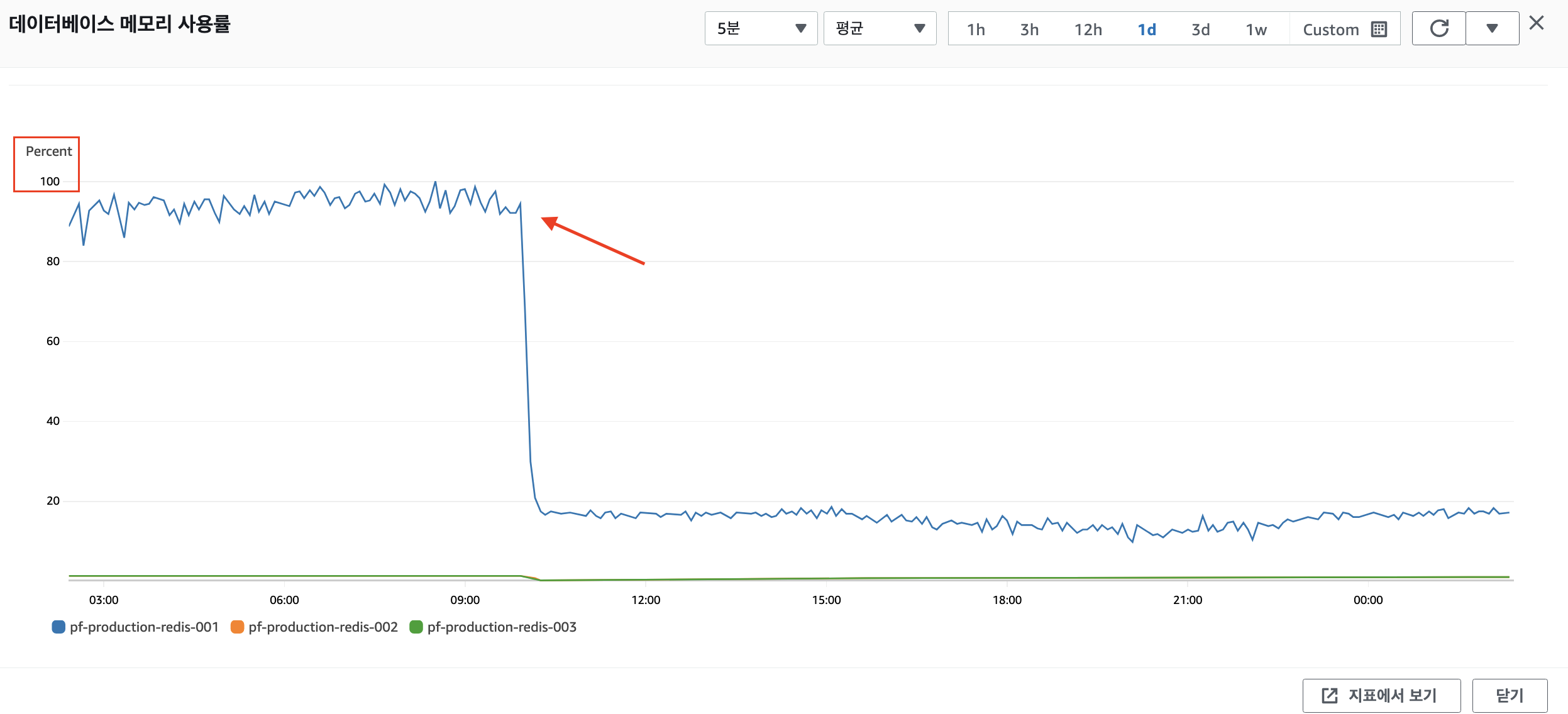
와우......
-
CPU 사용률
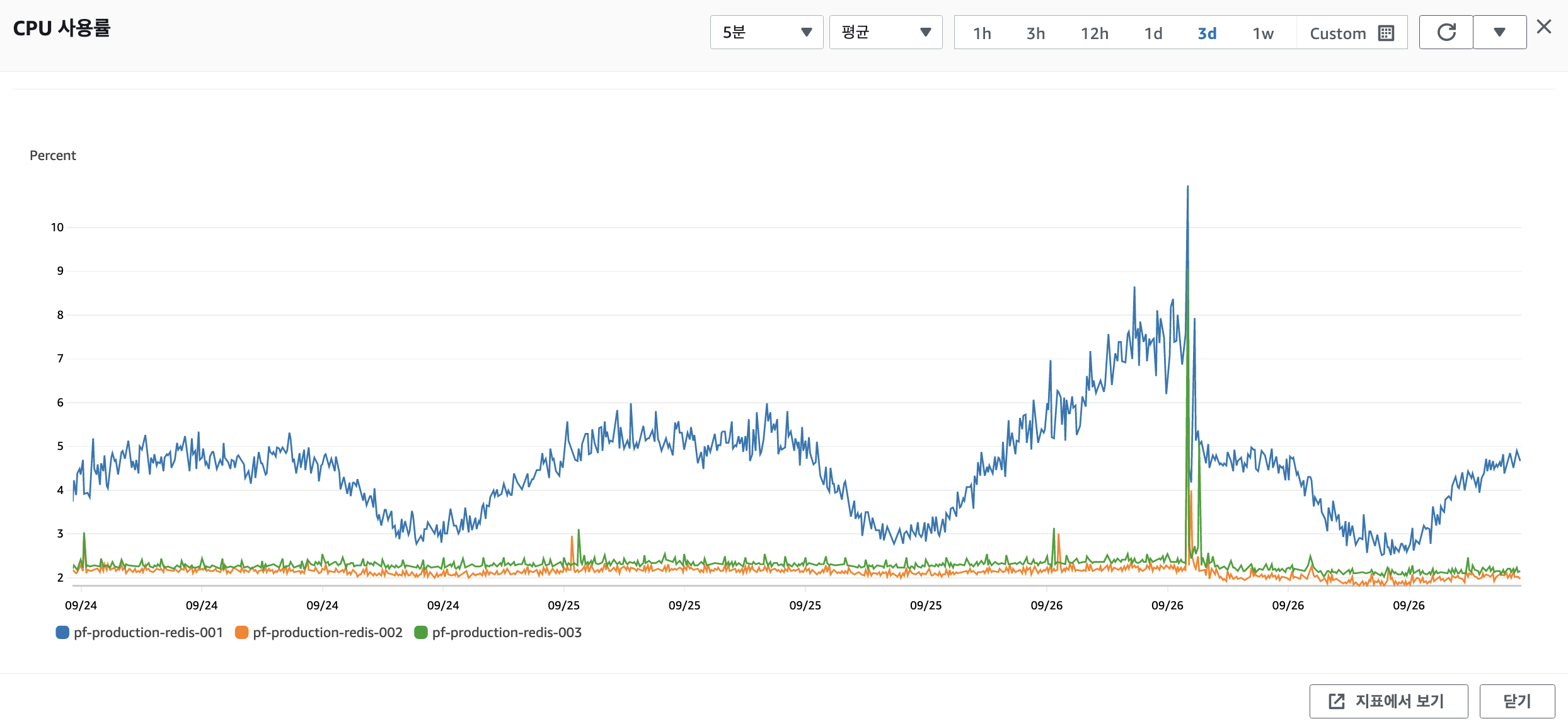
튀는 값이 보이지만, 10%에 불과하다. -
캐시 적중률
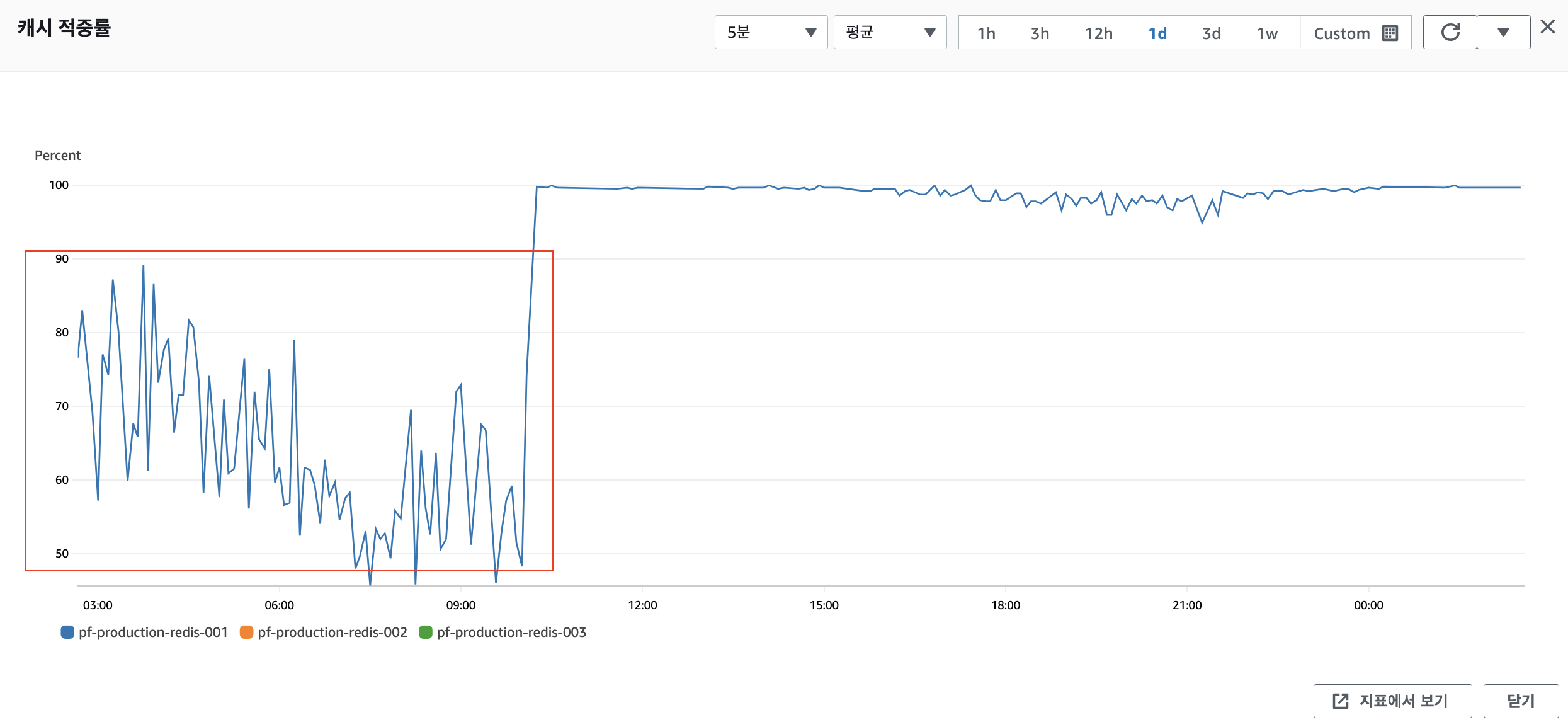
해결방법
유형 업그레이드를 진행하기로 했다.
우려되는 점은 다운타임이다.
엘라스틱 캐시 다운타임에 대해서도 공식문서를 참고했다.
인상깊은 설명은 아래와 같다.
but if Multi-AZ is enabled, the downtime is minimized. The role of primary node will automatically fail over to one of the read replicas. There is no need to create and provision a new primary node, because ElastiCache will handle this transparently. This failover and replica promotion ensure that you can resume writing to the new primary as soon as promotion is complete.
다중-AZ가 설정되어 있다면, 다운타임은 최소화된다.
평소라면 유저의 활동이 적은 새벽 시간에 진행했겠지만,
지금 당장 쏟아지는 에러를 해결하기 위해 약간의 다운타임을 감수하기로 했다.
총 17분이 소요됐다. 다행히 업그레이드 되는 동안
캐시 적중률(hit)가 꾸준히 증가했고, 메모리 사이즈도 마지막엔 증가했다. 하길 잘 했다.!
