1. Selenium을 활용한 웹 스크래핑
1) BeautifulSoup로 할 수 없는 것
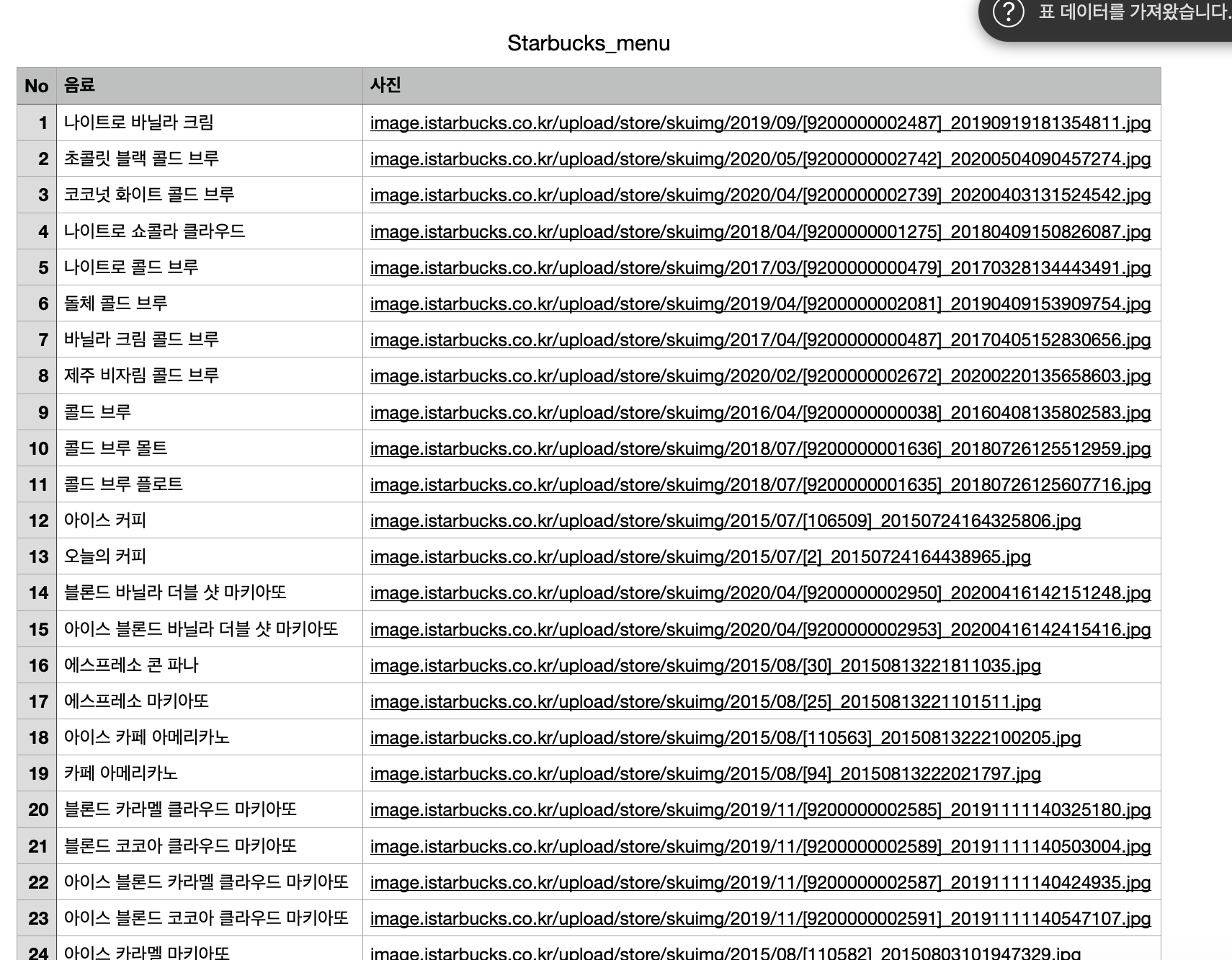
스타벅스코리아에 있는 모든 음료 이름과 이미지를 스크래핑하려고 했다.
BeautifulSoup으로만 구현하려고 했으나, 치명적인 문제가 생겼다.
일반적으로 웹 스크롤을 내려 모든 이미지들을 확인하기 전까진
( = 웹 하단까지 있는 이미지 파일들이 사용자가 확인하기 전까진)
img가 활성화 되어있는 상태가 아니다.
근데 단순히 활성화가 안되어 있다고만 생각했으나,
더한 난관이 있었다. 스크롤을 내려주지 않으면
개발자 도구를 통해 확인한 html에 있는 태그정보들 역시 없다.
따라서 BeautifulSoup로 아무리 정확한 태그 및 클래스명을 지정해줘도
리턴값은 None이었다.
2) Selenium 라이브러리 추가
Selenium을 사용하기 위해서는 크롬 드라이버가 필요했다.
(물론, Selenium이 크롬에서만 작동되는건 아니다. 다른 웹들도 가능하다.)
- 크롬 드라이버를 통해 '스타벅스코리아의 메뉴 url'정보를 파싱한다.
- 크롬 드라이버가 해당 웹의 스크롤을 가장 최하단으로 움직이게 한다.
(크롬 드라이버 공식 문서에 스크롤 이동과 관련한 코드 및 설명이 있다.)
- 크롬 드라이버에 의해 활성화된 웹의 주소를 BeautifulSoup 클래스에 입력한다.
soup = BeautifulSoup(driver.page_source, 'lxml')
웹 스크래핑 방법은 유튜브나 구글 문서에 참고자료들이 정말 많이 나왔다.
하지만 BeautifulSoup만으로는 구현이 안되는 이유를 알아내는 과정이
오래 걸렸다. 정확한 원인을 파악하지 위의 3.번에서 언급한 방식으로 크롬 드라이버가 활성화시킨 주소의 url을 바로 BeautifulSoup에 줄 수 있었다.
soup = BeautifulSoup(driver.page_source, 'lxml')(만약, 위의 과정 없이 웹주소를 복사해서 입력한다면,
크롬 드라이버 기반의 웹과 BeautifulSoup에서 requests.get한 웹은
서로연결되어 있지 않은 각각 독립적인 웹이 돼 버린다.
즉, 원하는 tag를 가져올 수 없다는 말이다.
3) 결과 - csv format
- One step at a time - 