mock 데이터 구축을 위한 csv파일을 받았다.
현재 쿠돈은 고도몰을 통해 서비스를 진행하고 있다.
즉, 제품 데이터가 쿠돈 자체 서버에 있는 것이 아니라
고도몰이란 서비스 대행 업체의 서버에 있다는 말이다.
제품의 카테고리를 추출하려 한다.
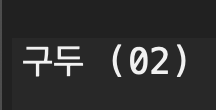
구두 (02) 를 파싱하고 우리가 구축하고 있는 데이터베이스에 넣어야 한다.
1. csv 파일
2. 파싱과정
1. 가장 아래의 문자열만 파싱
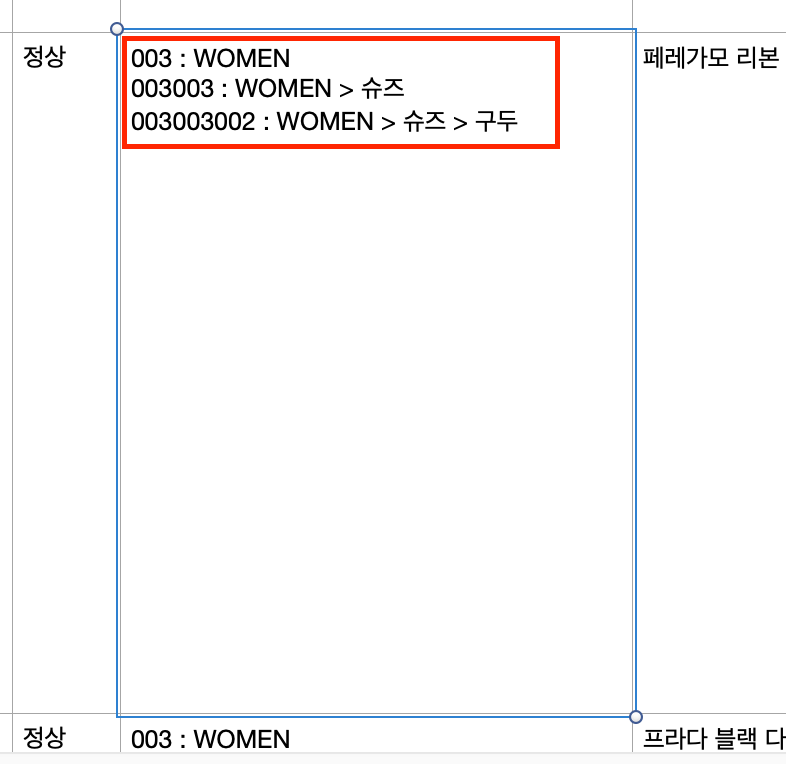
category = """003 : WOMEN
003003 : WOMEN > 슈즈
003003002 : WOMEN > 슈즈 > 구두"""
category = category.split(sep='\n')
print(category)결과

2. 가장 마지막 인덱스의 값만 파싱
여기서 중요한 것은 인덱스 2번째 접근(category[2])
과 같은 방식은 안 된다.
csv파일에 카테고리 부분이 작성되지 않은 부분,
혹은 한 줄만 있거나 여러 줄이 있는 경우 등 다양하기 때문이다.
따라서,
category = """003 : WOMEN
003003 : WOMEN > 슈즈
003003002 : WOMEN > 슈즈 > 구두"""
category = category.split(sep='\n').pop()
print(category)결과

3. 기준 세우기
- 필요한 것은 003003002에서 뒤에서 두 번째까지의 숫자인
02다.- 그리고
구두라는 키워드가 필요하다.
[1] 코드넘버 파싱하기
category_code = category.split(sep=' : ')[0][-2:]:를 기준으로 문자열을 split하였다.
:을 기준으로 앞의 숫자들이 필요하므로 [0]인덱스로 접근하였다.
또한, 뒤를 기준으로 2번째까지의 숫자만 필요하므로 [-2:]를 활용하였다.
[2] 카테고리 이름 파싱하기
category_name = category.split(sep=' > ')[-1]
print(category_name)>을 기준으로 가장 마지막 인덱스의 값만 필요하다.
따라서 [-1]을 활용하였다.
약간의 추가수정을 했고 (요구사항에 맞게)
그 결과는 아래와 같다.
결과