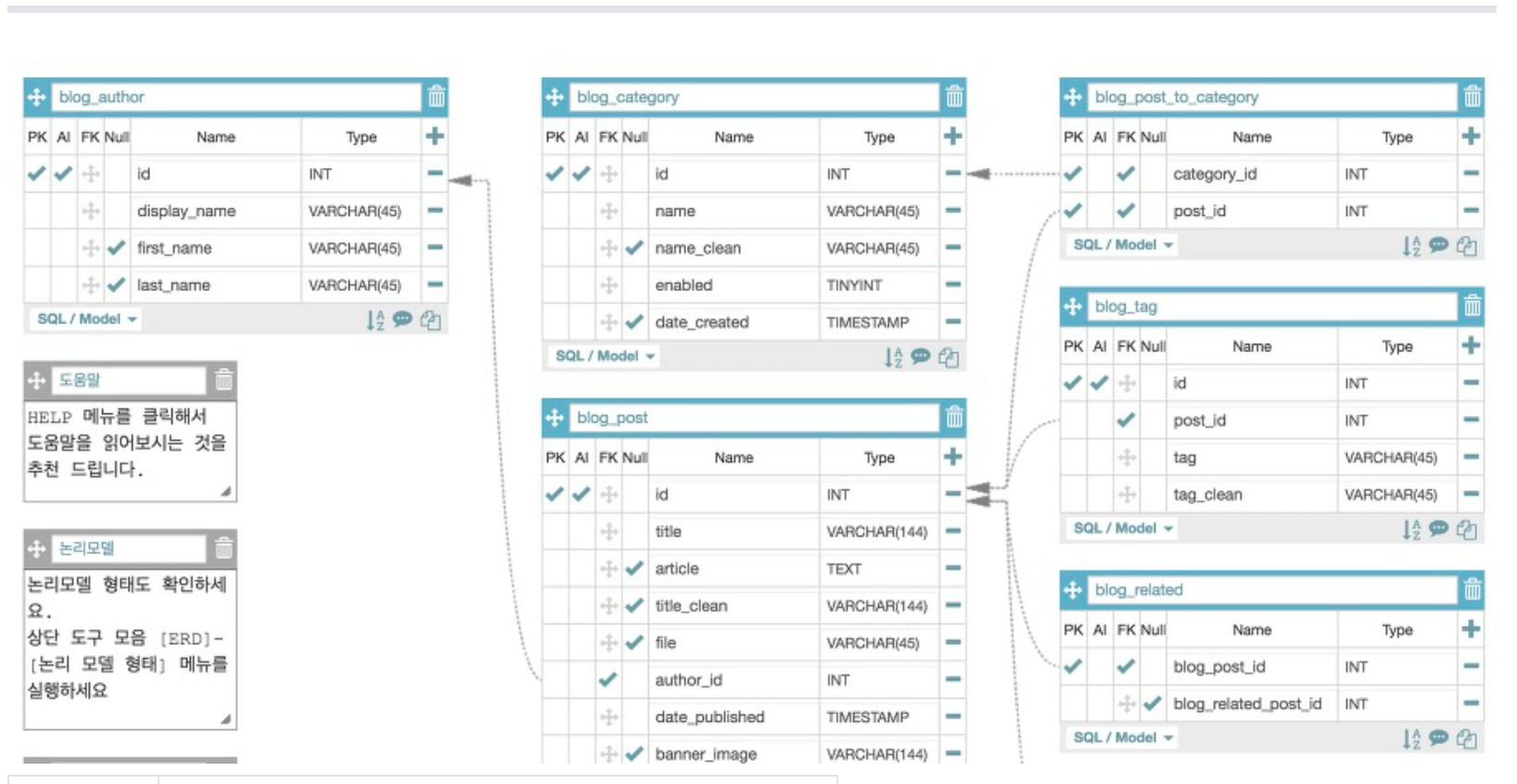
데이터베이스
백엔드에서의 핵심은 데이터를 처리하는 API를 만드는 것이었다.
뷰와 urls등을 통해 요청/응답의 프로세스를 구축하였다.
하지만 오늘 세션을 통해 최종 핵심이 뭔지 배우게 됐다.
그건 바로 데이터베이스다.
데이터베이스를 장고에서 제공하는 쉘을 통해 확인하지 못하거나(검증)
데이터베이스에 대한 이해없이 그저 뷰 모듈 구축에만 집중하는 것은
잘못된 방법이었다.
1) 데이터베이스(DB)란 무엇인가?
중복된 정보들을 어떻게 조직화하여 최적의 데이터셋을 구축할 것인가에 대한 설계 관점이 필요하다.
중복된 데이터들의 집합들 역시 명시적으로는 '데이터베이스'라고 말할 수 있다.
그러나 웹을 구축하면서 프론트엔드 및 클라이언트의 요청에 대한
서버의 응답을 위한 효율적인 데이터 구축을 강조하는 의미가 더해진다.
(1) 데이터의 중복을 최소화해야 하며,
(2) 이를 위해 효율적인 데이터 구축에 대한 설계 검토를 충분히 해야 한다.
(너무나 많은 시간을 뷰모듈에만 집중한 것을 반성한다ㅜㅜ)
2) DB 분류
(1) 관계형 DB
RDMS (Relational DataBase Management System)
-
각각의 테이블은 컬럼(column)과 row(로우)로 구성된다.
-
각 로우는 저만의 고유 키(Primary Key)가 있다.
primary key를 통해서 해당 로우를 찾거나 인용(reference)하게 된다. -
각각의 테이블들은 서로 상호관련성을 가지고 서로 연결될 수 있다.
-
테이블끼리의 연결에는 크게 3가지 종류가 있다.
- one to one
- one to many
- many to many
-
ex) MySQL, PostgreSQL
(2) 비관계형(Non-relational) DB
-
NoSQL
3) 테이블 연결 종류
(1) one to one
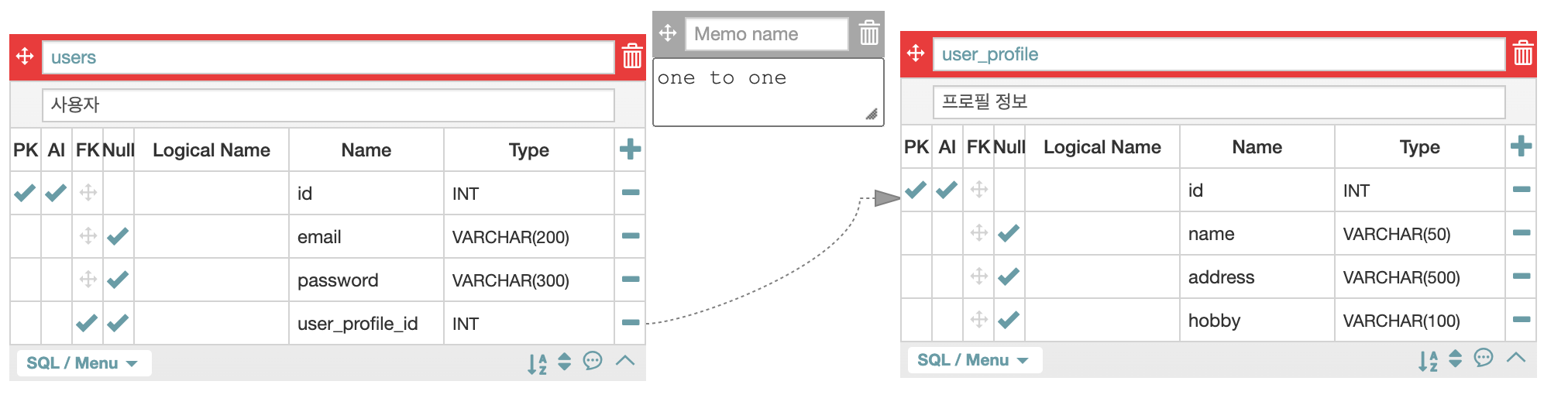
쉽게 생각해보자. 네이버나 인스타그램을 로그인했다고 하자.
나라는 사용자와 나의 프로필은 1 대 1 매칭이어야 한다.
내 계정을 로그인했더니 연예인 유인영의 프로필도 볼 수 있게 되면 안 된다.
(물론, 내 계정을 로그인했더니 내 프로필이 아니라 유인영의 프로필이 나오게 되면 테이블 연결 종류는 `one to one이나 로직이 잘못된거다.
(2) one to many
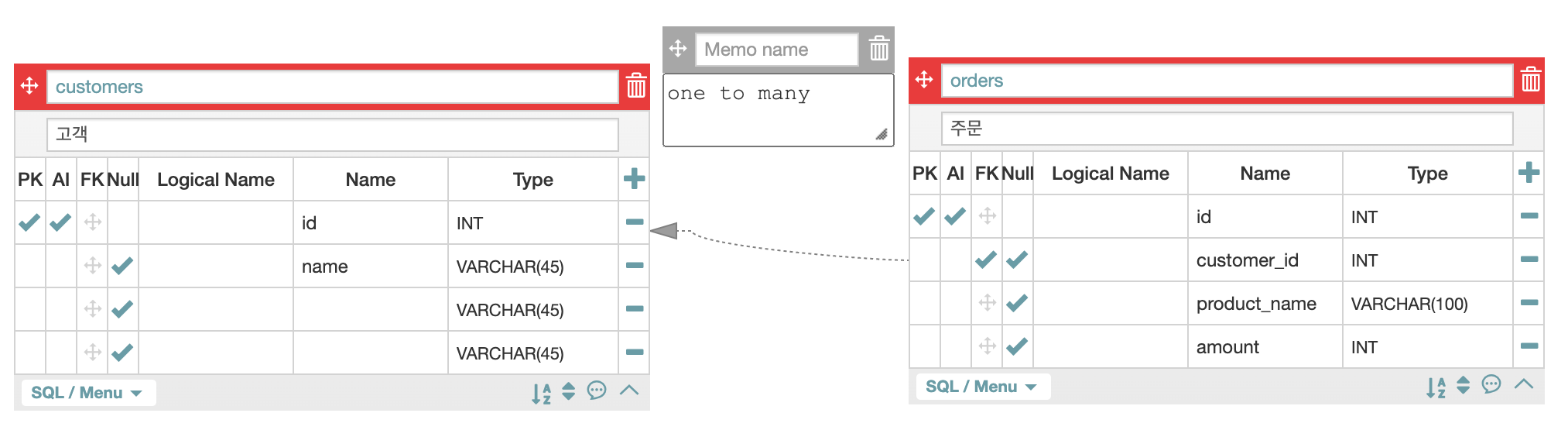
얼마 전에도 쿠팡에서 노트북 스탠드와 방향제 그리고 로션을 주문했었다.
고객은 나(one) 하나 뿐이지만, 내가 구매한 제품은 여러 개다.
고객을 바라보는 수많은 상품들이 있다.
앞으로 프로젝트를 진행하며 가장 많이 접하게 될 데이터 연결 종류 중 하나라고 한다.
잠시 짚고 넘어가야할 개념과 컨셉이 있다.
Foreign Key
앞으로 너무나 많이 사용할 용어다.
대부분의 관계형 데이터베이스는 Foreign Key를 통해
다른 테이블과 cross-reference를 한다.
즉, 테이블 간 연결 관계가 형성되기 전까지는 수면 위로 드러나지 않는 개념이다.
외래키라고도 하며, 테이블 내의 열 중 다른 테이블의 기본키를 참조하는 열이다.
출처: https://futurists.tistory.com/14 [미래학자]
Cascade
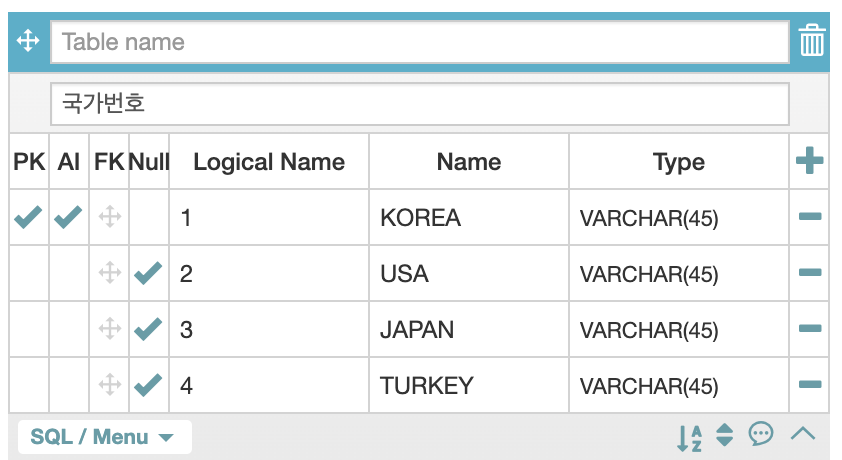
다음과 같이 id와 국가명이 one to one 데이터 연결로 이뤄진 2차원 테이블이 있다고 하자.
만약 내가 LogicalName 과 Name이 있는 가장 위의 행을(parent row) 삭제한다고 생각해보자.
그렇다면 그 아래 나라 정보들은 어떻게 될까?
분류체계를 정의한 상단의 기준 행이 삭제되어 의미가 없는 데이터가 되어 버린다.
즉, 이 상단의 parent row가 삭제되면 그 이하의 child row들도 전부 삭제되는 것을 DB에서는 `A cascading delete.라고 한다.
('폭포'같은 연쇄적인 삭제의 의미)
(3) many to many
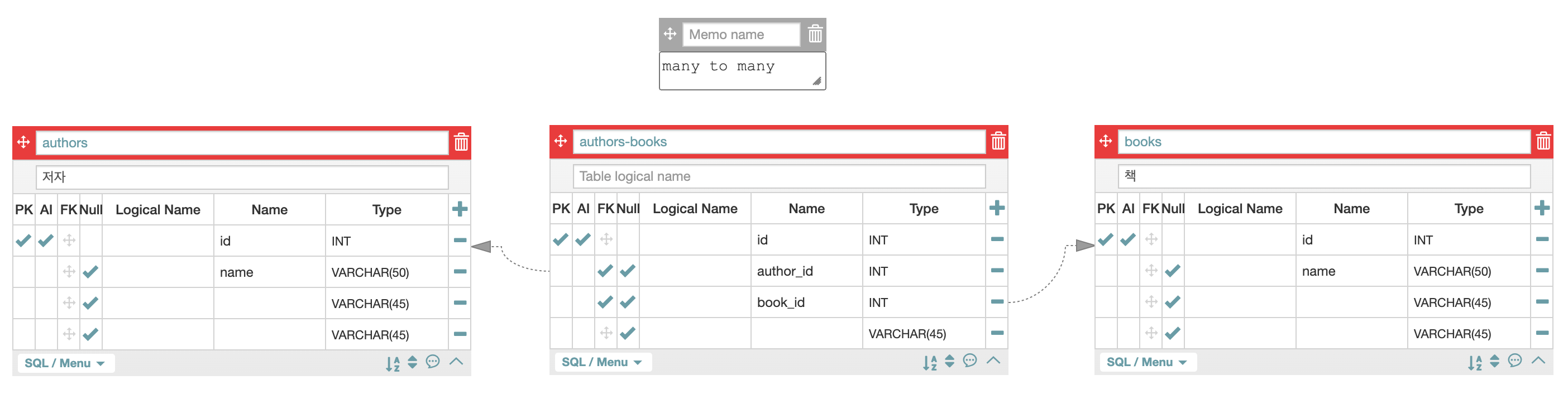
저자와 책은 one to many 데이터 연결 관계로 보기 쉽다.
하지만, 저자1, 저자2가 공동저자로 책을 집필하는 경우도 있다.
왜 논문들도 그렇지 않은가.
이렇게 중간 테이블을 통해 many to many 데이터 연결 관계를 만들어 준다.
4) [실습 1] 데이터 연결 관계
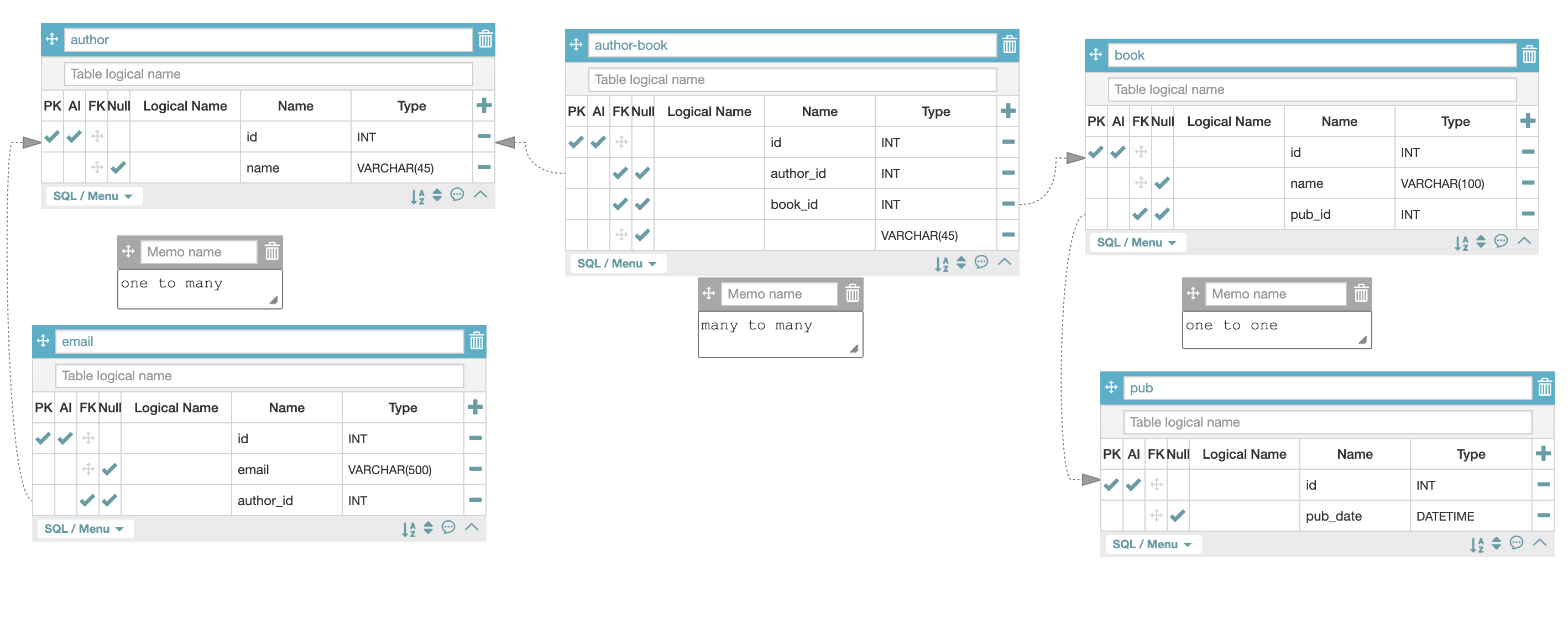
- 테이블 총 5개 생성
- author 테이블
- email 테이블
- author-book 테이블
- book 테이블
- pub 테이블(date-published)
1) author-book 테이블이 존재하는 이유는 공동저자인 책이 있기 때문이다.
(many to many)
2) author-email 테이블은 one to many로 설정했다.
저자 한 명에게는 여러 email이 존재하기 때문이다.
3) book과 pub는 one to one 테이블로 설정했다.
책 한 권과 출판일은 일 대 일 관계이기 때문이다.
(출판일만 뿐만 아니라 개정판 데이터 역시 DB 관리 대상이라면
개정판 테이블 역시 구축해야 한다. 개정판은 책 한권에 대해 여러개가 나올 수 있으므로, one to many 관계다.)
5) [실습 2] 수강신청 - 학생
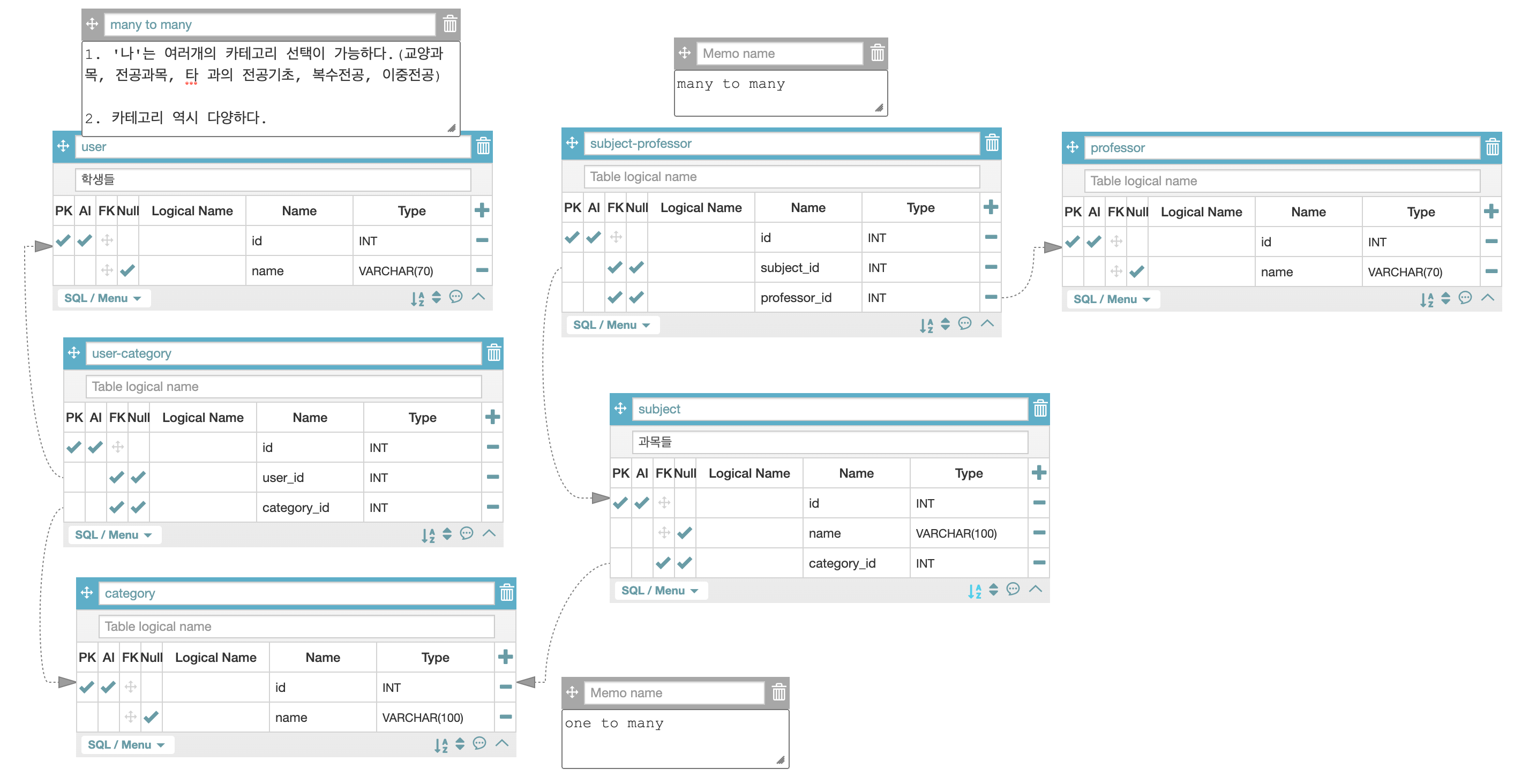
- 테이블 총 6개 생성
- user 테이블
- user-category 테이블
- category 테이블
- subject-professor 테이블
- subject 테이블
- professor 테이블
1) user-catogory 테이블이 존재하는 이유는 내가 여러 카테고리를 선택할 수 있고(교양과목, 전공과목, 이중/복수 전공인 경우 타 과의 전공 과목들),
나(user) 역시 동일 전공과목 카테고리를 여러개 선택할 수 있기 때문이다.
21학점을 전부 동일 전공과목(카테고리)로 채울 수도 있다.
따라서, many to many라고 판단했다.
2) subject-professor 테이블 역시 many to many라고 생각했다.
바로 위에서 살펴본 예시인 author-book 관계와 동일하기 때문이다.
실제로 내가 '자동차공학기초'라는 전공기초과목을 수강할 때,
책의 전반 부분은 A교수님이, 책의 중반부는 B교수님이, 책의 후반부는 C교수님이 진행했었다.

안녕하세요. ERD 그린 툴 이름이 뭔가요 ㅎㅎ?