1. 버블 정렬이란?
Bubble sort : unordered한 배열을 오름차순(혹은 내림차순)으로 정렬시키는 알고리즘.
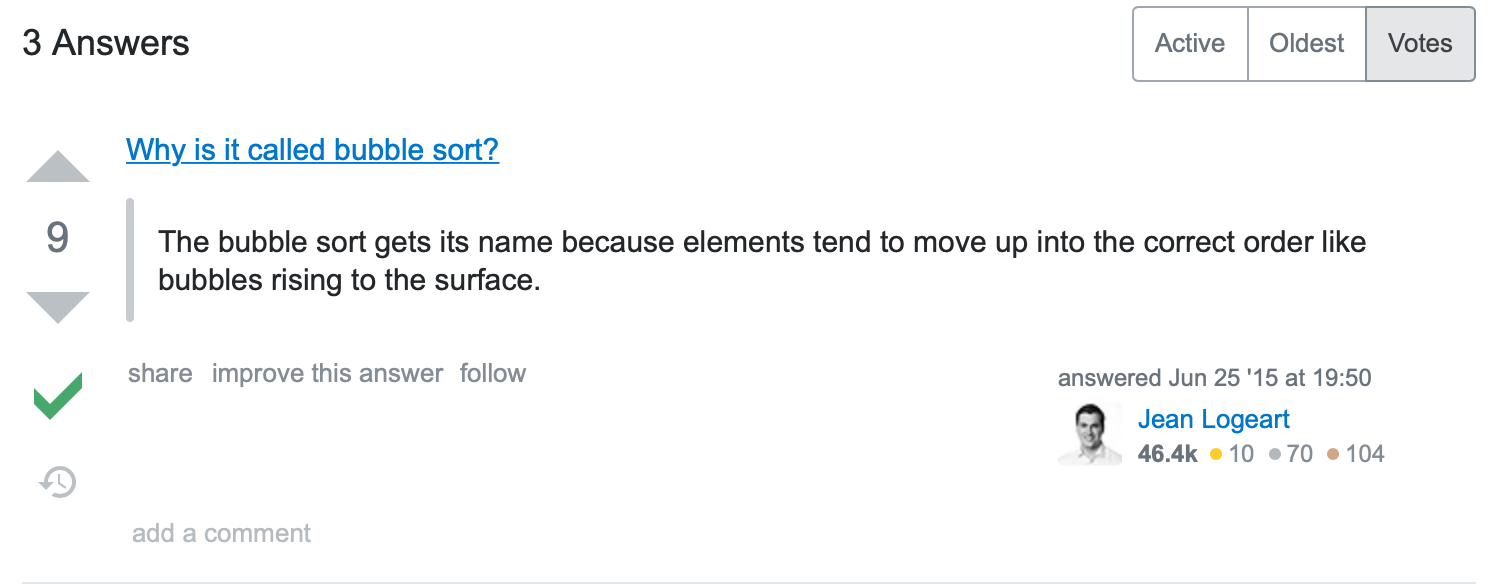
stack overflow에 왜 '버블'정렬이라고 이름이 붙여졌는지에 대해 나와있다.
기포들이 표면에 뾰보복 하고 나오는 것처럼, 배열 내 요소들이 특정 순서대로 뾰보복 정렬되기 때문이라는......
구글링을 하던중 버블정렬을 보며
구현하면 재밌을 것 같아 구현해 봤다.
배열에서 연속된 두 인덱스를 비교하는 원리를 통해
결국엔 오름차순이든, 내림차순으로 정렬되는 것이다.
2. 버블 정렬 설명
normal_list = [5, 4, 2, 6] 이 있다고 하자.
- 규칙 : 인덱스 0,1 비교 -> 인덱스 1,2 비교 -> 인덱스 2,3 비교, 쭉쭉쭉
[1] 첫 번째 반복문 일 때,
1) 5와 4를 비교한다. 맨 앞의 5가 더 큰 수다.
-> [4, 5 ,2, 6]으로 자리 전환!
2) 5와 2를 비교한다.
-> [4, 2 ,5, 6]으로 자리 전환!
3) 5와 6을 비교한다.
-> [4, 2 ,5, 6]
[2] 두 번째 반복문 일 때,
4) 4와 2를 비교한다.
-> [2, 4 ,5, 6]
5) 4와 5를 비교한다.
-> [2, 4 ,5, 6]
[3] 세 번째 반복문 일 때,
5) 2와 4를 비교한다.
-> [2, 4 ,5, 6]3. 버블정렬 코드
내가 작성한 코드는 이중 loop를 사용했다.
자료구조 책을 살펴보니 나와는 조금 다르게 작성한 코드가 있었다.
우선 내가 작성한 코드는 아래와 같다.
normal_list = [ 5, 4, 2, 6, 3, 9, 1, 0 ]
def bubble_sort(normal_list):
for i in range(len(normal_list)-1): # 0, 1, 2, 3, 4
for j in range(1, len(normal_list) - i):
# 다음 인덱스의 값이 크다면 바꿀 필요가 없다.
if normal_list[j] > normal_list[j-1]:
continue
# 다음 인덱스의 값이 작다면, 바로 앞의 값과 바꾼다.
else:
temp = normal_list[j]
normal_list[j] = normal_list[j-1]
normal_list[j-1] = temp
return normal_list
bubble_list = bubble_sort(normal_list)
print(bubble_list)결과

이번엔 자료구조 책에 나온 방식이다.
def bubble_sort(list):
unsorted_until_index = len(list) - 1
sorted = False
while not sorted:
for i in range(unsorted_until_index):
if list[i] > list [i+1]:
sorted = False
list[i], list[i+1] = list[i+1], list[i]
unsorted_until_index = unsorted_until_index - 1
if unsorted_until_index == -1:
sorted = True
list = [65, 55, 45, 35, 25, 15, 10,9,8,4,3,21,2,1,0]
bubble_sort(list)
print(list)결과

나는 range(len()) 방식을 사용했는데,
저자의 방식처럼 unsorted_until_index로 변수선언을 통해 가독성을 높인 점이 좋았다. 다음엔 나도 저렇게 활용해야겠다ㅎㅎㅎㅎ
음....그니까 무엇을 반복할지에 대해 좀 더 명확하다고 할까?! 단순히 len(배열 이름)의 경우와
len(정렬시켜야할 배열 인덱스)로 작성한 경우,
좀 더 개발자의 의도를 확실히 알 수 있다고 본다.
4. 버블정렬의 효율성에 대해서
[1] '비교'프로세스
원소가 2개인 배열에서는 (1)번의 '비교'
원소가 3개인 배열에서는 (2+1) 번의 '비교'
원소가 4개인 배열에서는 (3+2+1) 번의 '비교'
즉, 원소가 N개인 배열은 시그마(N-1)번의 '비교'가 필요
[2] '값 교환'프로세스
알고리즘을 평가할때, 최악의 경우가 default로 본다.
원소가 2개인 배열에서 (1)번의 '교환'
원소가 3개인 배열에서는 (2+1)번의 '교환'
원소가 4개인 배열에서는 (3+2+1) 번의 '교환'
즉, 원소가 N개인 배열은 시그마(N-1) 번의 '교환'이 필요
