프로젝트 진행을 위한 환경셋팅,
장고 모델링(models.py) 및 로컬 데이터베이스 구축 위한
ERD구성도까지 작성했다.
완료된 ERD구성도 기반으로 웹 스크래핑을 해보자.
1. categories 스크래핑

스타벅스의
음료에는 총 9가지의 카테고리들이 있다.
scraping.py 모듈을 생성 후,
각 테이블 정보 단위로 스크래핑을 하려고 한다.
(계획 : 각 테이블에 해당하는 정보를 스크래핑하는 함수를 만들고,
scraping.py에는 이러한 여러 함수들을 작성하려고 한다.)
vi scraping.py
STARBUCKS_URL = 'https://www.starbucks.co.kr/menu/drink_list.do'
def get_categories():
response = requests.get(STARBUCKS_URL)
html = BeautifulSoup(response.text, 'lxml')
categories = html.select('.product_list >dl > dt > a')
file_name = 'categories.csv'
f = open(file_name, 'w', encoding='utf-8', newline='')
wr = csv.writer(f)
wr.writerow(['categories'])
for category in categories:
category = category.text
wr.writerow([category])
f.close()
get_categories()결과

2. 음료이름과 이미지 스크래핑
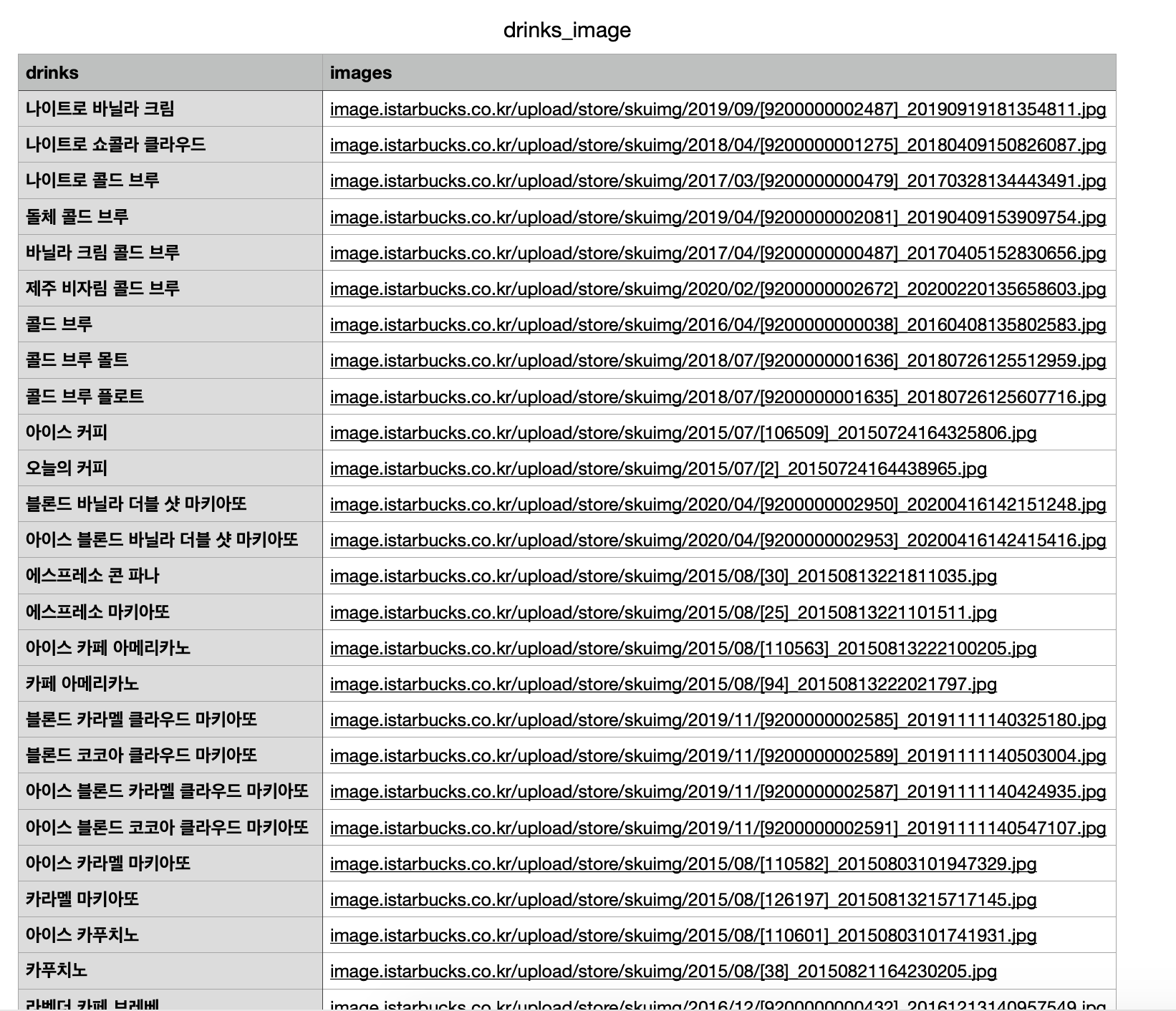
def get_drinks():
file_name = 'drinks_image.csv'
f = open(file_name, 'w', encoding='utf-8', newline='')
wr = csv.writer(f)
wr.writerow(('drinks', 'images'))
service = Service('/Users/khh180cm/Downloads/chromedriver')
service.start()
driver = webdriver.Remote(service.service_url)
driver.get(STARBUCKS_URL)
# Scroll down : to get loading data(img tag)
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(1)
html = BeautifulSoup(driver.page_source, 'lxml')
drinks = html.select('a.goDrinkView > img')
for drink in drinks:
drink_name = drink['alt']
raw_img = drink['src']
drink_img = raw_img.split('//')[1]
total = [drink_name, drink_img]
wr.writerow(total)
f.close()
get_drinks()BeautifulSoup 패키지를 사용하며 배웠고 잘 활용하고 있는 부분을
여기에 미리 정리해 두려고 한다.
- 개인적으로는 select메소드가 find_all 메소드보다 편하다.
아래의 내용이 잘 정리되어 있어서, 관련 블로그를 참조했다.
(출처는 이미지 하단에)

출처 : https://m.blog.naver.com/kiddwannabe/221177292446
프로젝트가 시작되면, 1분 1초가 아깝기 때문에 이 곳을 자주 확인하려고 한다.
또한, 아래의 stackoverflow 답변을 참고하였다.
- csv writerow 메소드 관련
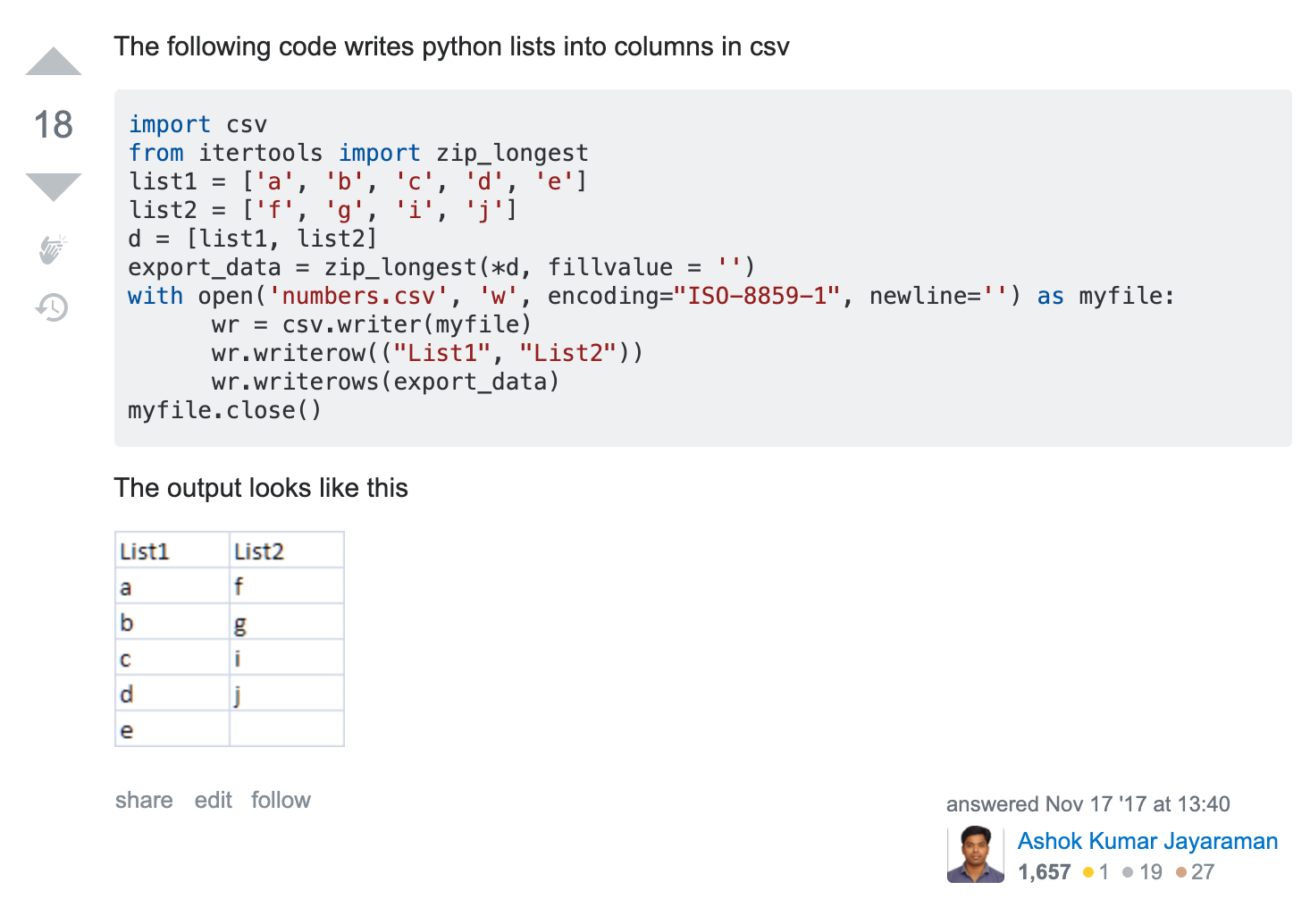
- img 태그 중 src 속성에 해당하는 이미지 주소만 추출하는 법