오늘은 many to many 데이터 연결 관계에 대한
실습을 진행하려고 한다. (음료와 알레르기 유발요인)
- ERD구성도 기반으로 웹 스크래핑 및 csv파일 생성
- 음료와 알레르기 유발 요인에 대한 models.py 작성하기
- 외부모듈(db_uploader.py)에 csv파일 import하여
장고 및 mysql 데이터베이스로 옮기기)- 값 검증하기
1. 웹 스크래핑 및 csv파일 생성
- 음료와 알레르기 유발요인
지난 시간에 작성한 음료-알레르기의 ERD구성도는 아래와 같다.
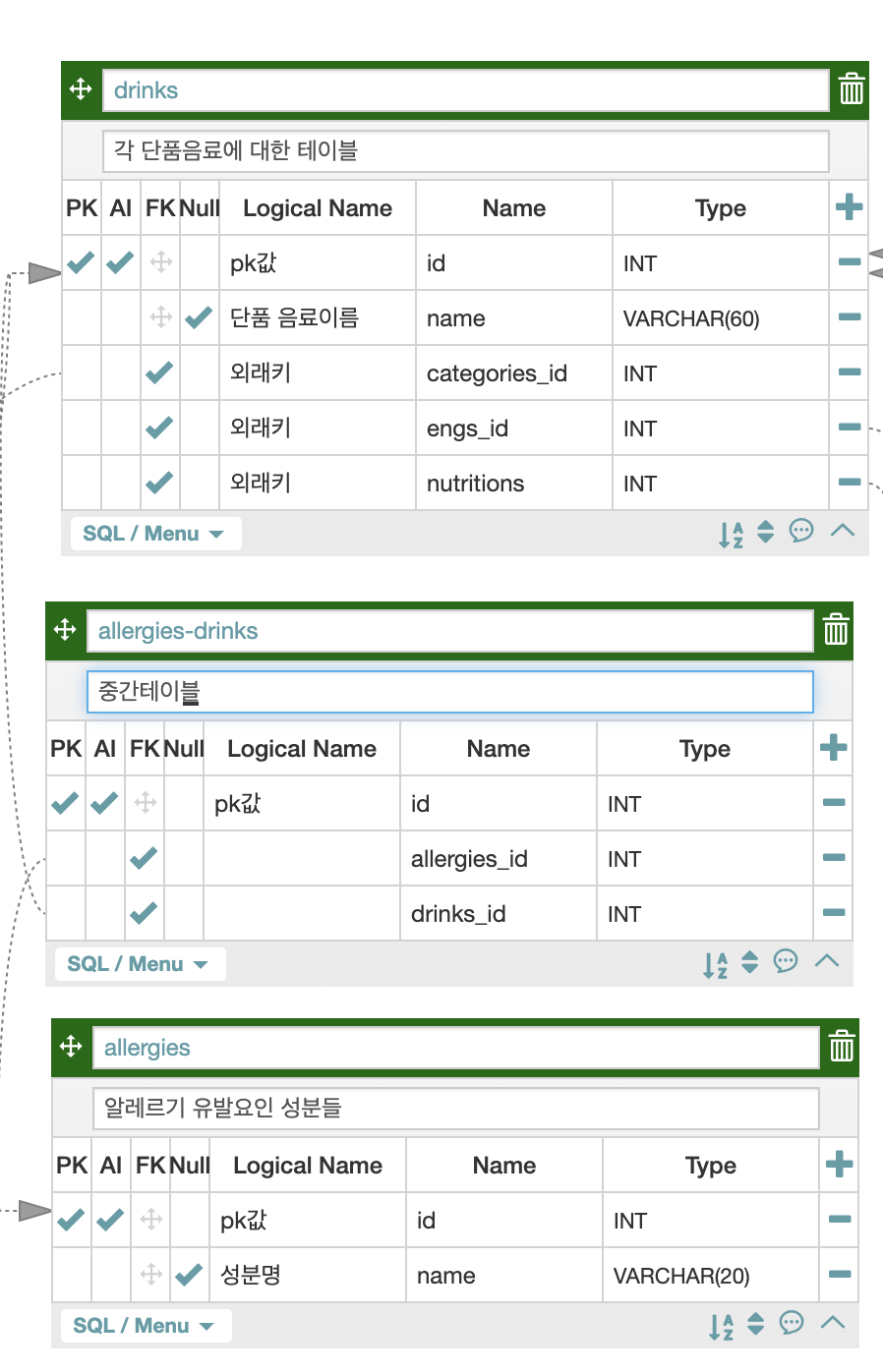
- 음료는 알레르기 유발요인을 1개 이상 포함할 수도, 아무것도 포함하지 않을 수도 있다.
- 알레르기 유발요인 중
우유는 여러 음료에 포함될 수도, 아무것도 포함하지 않을 수도 있다.
(또는복숭아또는오징어등등)
알레르기 성분을 웹 스크래핑하는데 예상치 못한 삽질(?)이 있었다.ㅎㅎ
스타벅스 코리아의 메인 홈페이지의 개발자 도구를 확인하면
모든 음료에 대한 제품 코드번호가 있다.
하지만,
BeautifulSoup로만 웹 스크래핑을 하면 제품코드를 구할 수가 없었다.
혹시나 해서 셀레니움 모듈을 사용했더니 그제서야 제품코드를 스크래핑 할 수 있었다.
더 큰 문제는, 음료별 알레르기 유발요인을 찾기 위해서는
각 음료(131개)를 위해 별도 마련된 페이지로 이동을 해야 관련 태그를 스크래핑할 수 있다는 것이었다.
예를 들어, 아이스 카라멜 마키아또음료 페이지의 URL은
https://www.starbucks.co.kr/menu/drink_view.do?product_cd=110582
제주 쑥떡 크림 프라푸치노음료 페이지의 URL은
https://www.starbucks.co.kr/menu/drink_view.do?product_cd=9200000002090
product_cd=전까지는 URL이 동일하고, 그 이후의
음료 제품 코드가 각기 다른 것이다.
때문에,
먼저 제품코드만 추출한 뒤
DEFAULT_URL ='https://www.starbucks.co.kr/menu/drink_view.do?product_cd='
product_tags = html.select('a.goDrinkView')아래와 같은 방식으로 접근했다.
for tag in product_tags:
product_url = DEFAULT_URL + tag['prod']여기서 더더 큰 문제는
유발요인 성분이 잘 나오다가도
셀레니움이 강제종료가 되는 것이었다.
time.sleep(1) 혹은 time.sleep(2) 등을 주면서까지 해봤지만
해결되지 않았다.
구글링을 해도 뚜렷한 해결법이 없었다.
그래서
print(page)각 음료의 URL(page)를 출력하면서
에러가 발생되기 직전이 어떤 음료였는지 알 수 있었다.
그리고 스타벅스 홈페이지로 들어가 print로 확인했던 음료의
바로 다음 음료를 클릭했더니
아래와 같은 alert 메시지가 나왔다.
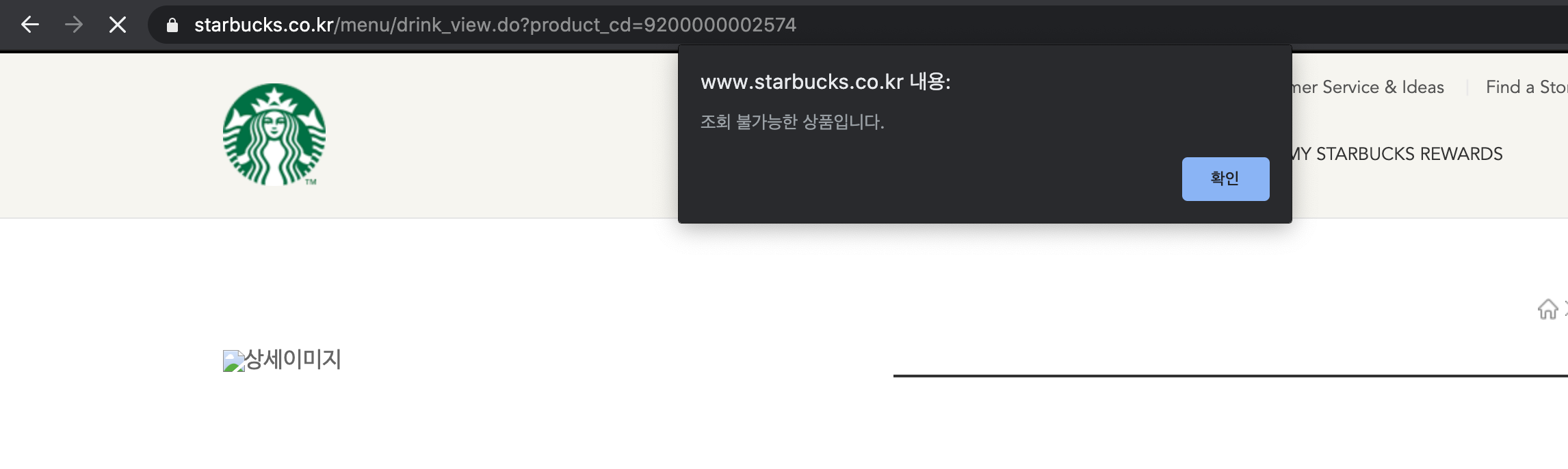
이런 제품들이 총 4개가 있었다.
이 에러를 찾는 과정이 시간이 많이 소요됐다.
결과

(중략)

2. models.py 작성하기
장고 공식문서에 나와있는 문서를 확인해보자.
(출처)https://docs.djangoproject.com/en/3.0/topics/db/examples/many_to_many/
In this example, an Article can be published in multiple Publication objects, and a Publication has multiple Article objects:
장고에서는 기사와 출판매체를 예시로 들고있다.
- 기사는 여러 매체에 출판될 수 있다.
- 한 매체는 여러개의 기사를 작성(출판)할 수 있다.
딱, many to many 데이터 연결 관계 케이스다.

장고 예제를 좀 더 보자.
우선, 출판 매체의 객체를 생성하고 있다.

(참고)
아래와 같이 p1.save()를 하지않으면
데이터베이스에 p1 객체 데이터가 저장되지 않는다.
왜냐하면
쿼리셋(QuerySet)은 전달받은 모델의 객체 목록을 보여주는 명령어이기 때문이다.
명령어를 입력하면 쿼리셋은 우선 데이터베이스의 데이타 값을 읽기 때문이다.
p1 = Publication(title='The Python Journal')나는 순서를 좀 바꿔서 진행해봤다.
(장고문서를 그대로 따라하면 이해없이 맹목적으로 타이핑만 하게 될 것 같아서....)
from django.db import models
class Article(models.Model):
headline = models.CharField(max_length=100)
publication = models.ManyToManyField('Publication')
class Meta:
db_table = 'articles'
class Publication(models.Model):
title = models.CharField(max_length=30)
class Meta:
db_table = 'publications'난 Article 클래스에 ManyToManyField 를 정의했다.
이제
makemigrations 및 migrate을 통해
models.py의 변경점 저장 및 데이터베이스 반영을 진행해야 한다.
그리고 shell을 열고 데이터를 확인하는 프로세스다.
튜토리얼은 이쯤하고 스타벅스 음료를 바로 적용하자.
from django.db import models
class Drink(models.Model):
name = models.CharField(max_length = 60 )
class Meta:
db_table = 'drinks'
class Allergy(models.Model):
allergy_drink = models.ManyToManyField(Drink)
class Meta:
db_table = 'allergies'< db_uploader.py >
1 import os
2 import sys
3 import csv
4 import django
5
6 os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'starbucks.settings')
7 django.setup()
8
9
10 from beverage.models import Drink, Allergy
11 CSV_PATH_BEVERAGE = './drinks_image.csv'
12 CSV_PATH_ALLERGY = './allergies.csv'
13
14 def upload_drink():
15 with open(CSV_PATH_BEVERAGE) as csv_file:
16 data_reader = csv.reader(csv_file)
17 next(data_reader, None)
18 for row in data_reader:
19 drink_name = row[1]
20 Drink.objects.create(name = drink_name)
21 upload_drink()실수로 upload_drink()를 한 번더 실행해버렸다.
총 131개의 음료인데 262개 가 돼 버린 것이다.
커밋, 롤백, 트랜잭션 등에 대한 중요성을 다시금 깨닫는다.
일단 테이블 내 데이타를 전부 삭제했다.
아직 매우 초반이라 그렇지,
데이터베이스 내에 여러 테이블들이 많이 생성된 상황을
지금부터 미리 대비해야겠다.
DELETE FROM drinks;위 명령어로 empty set으로 만들었다.
다시 업로드를 진행했다.
그런데 문제가 생겼다.

263번 부터 id가 시작되고 있다.
스택오버플로우에 한줄기 희망이 있었다.
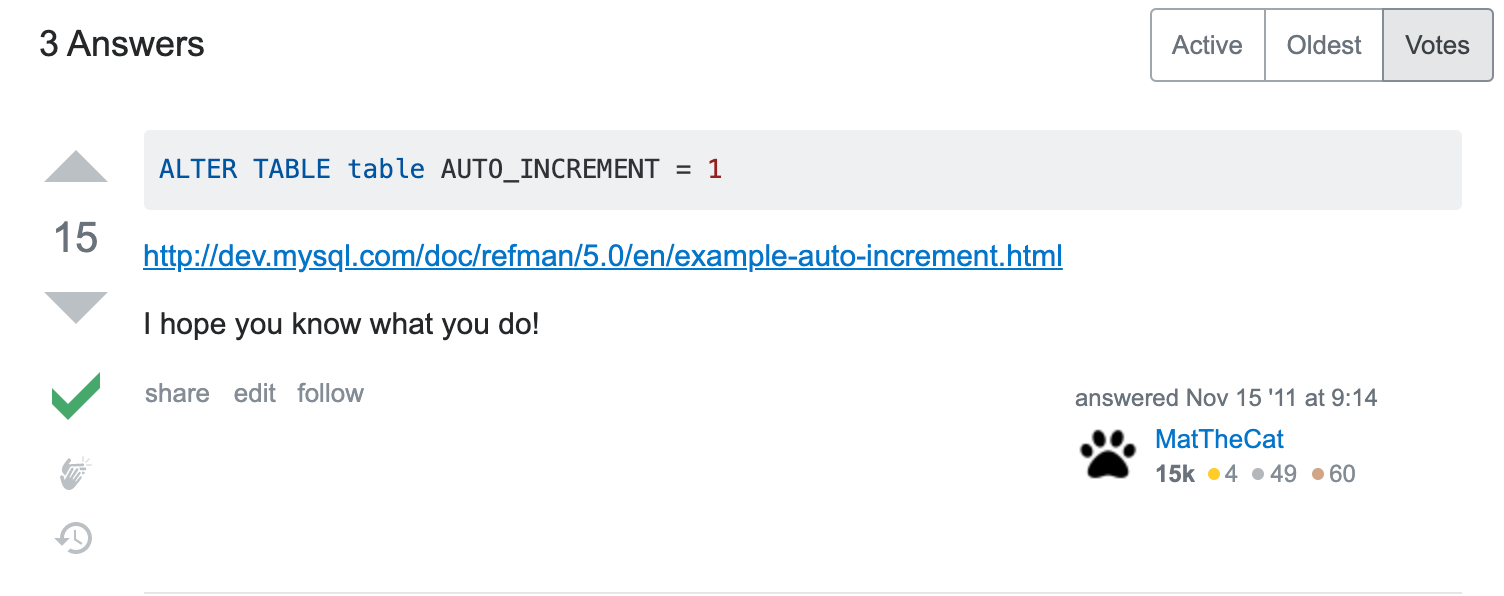
1) 다시 삭제후
DELETE FROM drinks;
2) 아래 명령어 실행
ALTER TABLE drinks AUTO_INCREMENT = 1;
3) 다시 업로드 진행
python db_uploader.py
결과

