1. Sort Merge Join
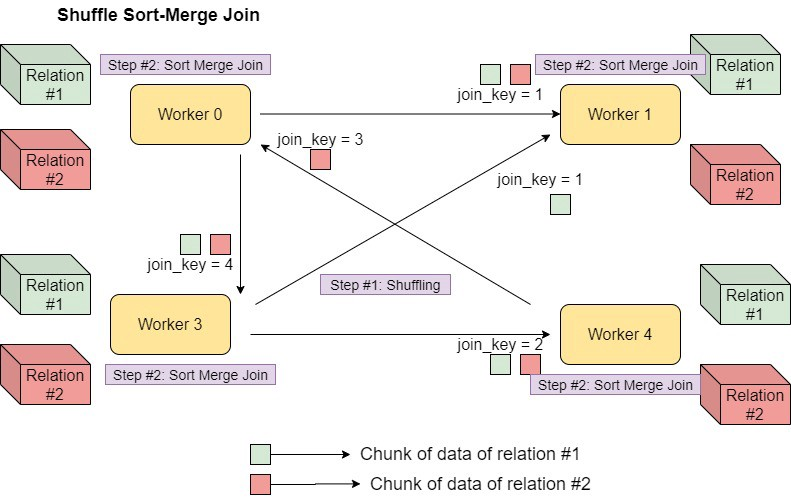
Sort Merge Join은 먼저 동일한 워커 노드로 데이터를 shuffling한 다음 join key를 기반으로 데이터를 정렬 후 데이터를 병합하는 방식이다.
참고사항
- spark 2.3 부터 기본 join strategy로 사용된다.
- join key가 정렬이 가능해야 한다.
2. Shuffle Hash Join
Shuffle Hash Join은 동일한 워커 노드에서 동일한 값의 Join Key로 데이터를 이동한 후 Hash Join을 실행한다.
참고사항
- shuffling과 hashing을 모두 포함하는 방식이기 때문에 비용이 많이 드는 join이다.
- Equal Join에만 지원된다.
3. Broadcast Join
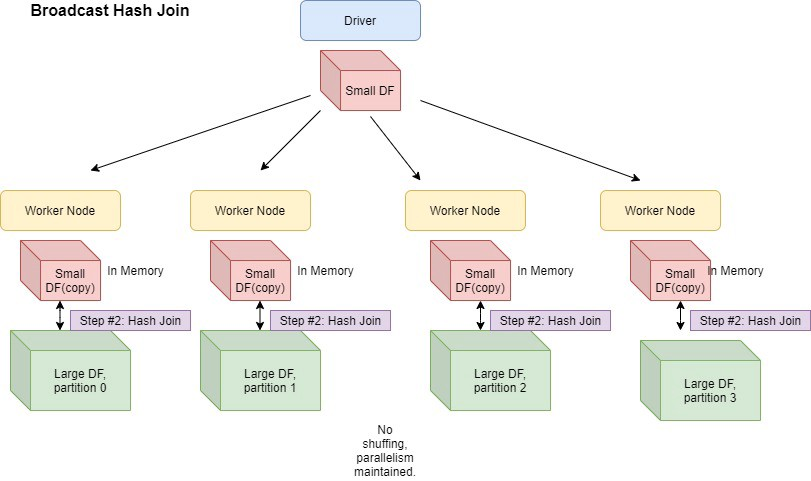
Broadcast Join은 일반적으로 큰 테이블과 작은 테이블 간의 조인에 사용되는 전략이다. 테이블이 단일 워커 노드의 메모리 크기에 적합할 정도로 충분히 작은 경우 조인 연산을 최적화 할 수 있다. 이 방법은 작은 크기의 테이블을 모든 워커 노드에 복제하기 때문에 노드간의 shuffling 비용이 절약된다는 장점이 있다.
Spark는 Join 관계의 테이블 하나의 크기가 10mb 보다 작을 때 Broadcast Join을 사용한다.
이 값은
spark.sql.autoBroadcastJoinTreshold설정을 사용하여 변경 가능
참고사항
- 너무 큰 데이터를 broadcast 하면 드라이버 노드가 비정상적으로 종료될 가능성이 있다.
- Equal Join에만 지원된다.
참고자료
