회사의 주요 데이터는 대부분 RDBMS에 저장되어 있다. 스쿱(Sqoop)은 RDBMS에서 HDFS로 데이터를 보내는 작업과 HDFS에서 RDBMS로 데이터를 보내는 작업을 쉽게 처리해주는 오픈소스 도구이다.
스쿱은 내부적으로 RDBMS의 테이블에서 행을 추출하는 맵리듀스 잡을 실행한다.
Import (RDBMS -> HDFS)
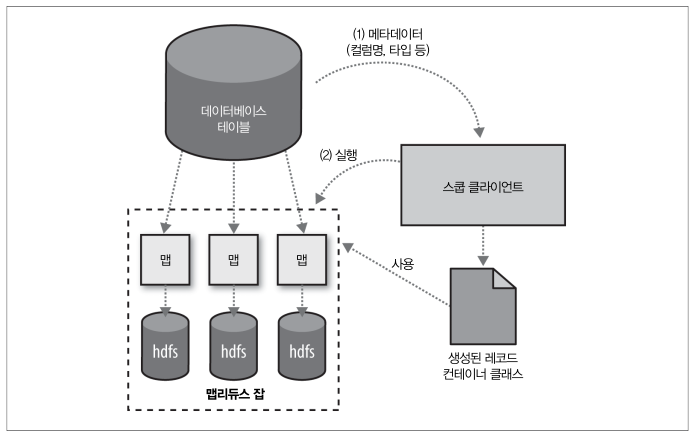
스쿱은 import를 시작하기 전에 import 대상 테이블의 모든 컬럼 목록과 SQL 데이터 타입을 추출한 후에 SQL 데이터 타입을 자바 자료형으로 매핑한다. 그 후 테이블에서 추출한 레코드에 적용할 테이블 특화 클래스를 생성하고, 생성된 클래스를 이용해 맵 태스크를 진행한다.
분할 기준 컬럼(splitting column)
테이블을 읽을 때 SELECT col1, col2, ... FROM tableName 과 같은 쿼리를 수행하는데 이러한 쿼리를 다수의 노드에 분산시키면 import 성능을 높일 수 있다. 쿼리를 분리하기 위해서는 분할 기준 컬럼(splitting column)이 중요하다. 스쿱은 테이블의 메타데이터 정보를 기반으로 분할에 적합한 컬럼을 예상한다. 테이블에 기본키가 있으면 이 컬럼을 분할 기준 컬럼으로 사용한다. 기본키 컬럼의 최댓값과 최솟값을 조회한 후 태스크 수를 기준으로 각 맵 태스크가 수행할 쿼리를 정한다.
예를 들어 10,000개의 데이터가 있는 table이 있을 경우, 스쿱은
SELECT MIN(id), MAX(id) FROM table과 같은 쿼리를 수행 후 이 결과값으로 전체 데이터의 범위를 산정한다. 스쿱의 병렬로 실행하는 맵 태스크 수를 네 개로(-m 4) 지정할 경우 각 맵 태스크는SELECT id, ... FROM table WHERE id >= 0 AND id < 2500,SELECT id, ... FROM table WHERE id >= 2500 AND id < 5000등과 같은 쿼리를 수행한다.
Export (HDFS -> RDBMS)
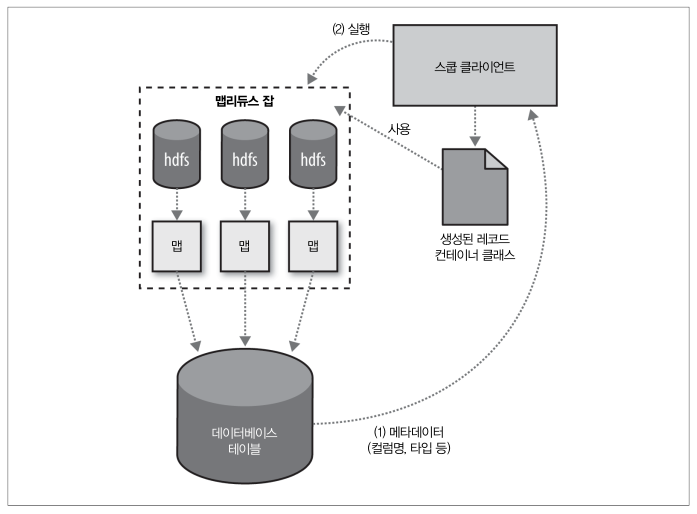
스쿱은 자바 타입을 SQL 데이터 자료형으로의 전환이 완전히 가능하지 않기 때문에 HDFS에서 RDBMS로 테이블을 export 하기 전에 데이터를 받을 수 있는 타겟 테이블을 미리 생성해 놓아야 한다. 그 후 export 명령을 실행한다.
MySQL에 export 할 때 스쿱은 mysqlimport를 이용할 수 있다. 각 맵 태스크는 mysqlimport 프로세스를 생성하여 데이터베이스에 반영한다.
참고자료
