0603일기
학습데이터의 window size를 대폭 줄이고 난 뒤(720에서 24로)
오토인코더가 데이터의 재구성을 너무 못하는거다..
한 2~3일 돌렸는데도 말이다
여러가지 다해보다가 결국 포기하려던 찰나
내가 짠 코드 여기저기에 for문을 억지로 사용한 부분을 어느정도 고치고
pandas, numpy 기능을 이용하여 for문을 대체하였더니
학습속도가 10배넘게 빨라진듯 하다..
바뀐 학습속도로 데이터와 epoch를 늘려서 다시 학습을 시켰는데
훨씬 좋은 정량적 지표가 나온다.
기존에는 correlation이 0.4정도밖에 안나왔었고, 직접 비교했을때도 영 재구성이 시원치 않았는데(8000회쯤)
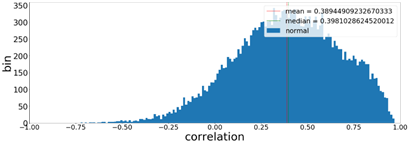
무식하게 학습데이터와 epoch를 늘리니 훨씬 좋은결과가 나오고 있다(30000epoch)

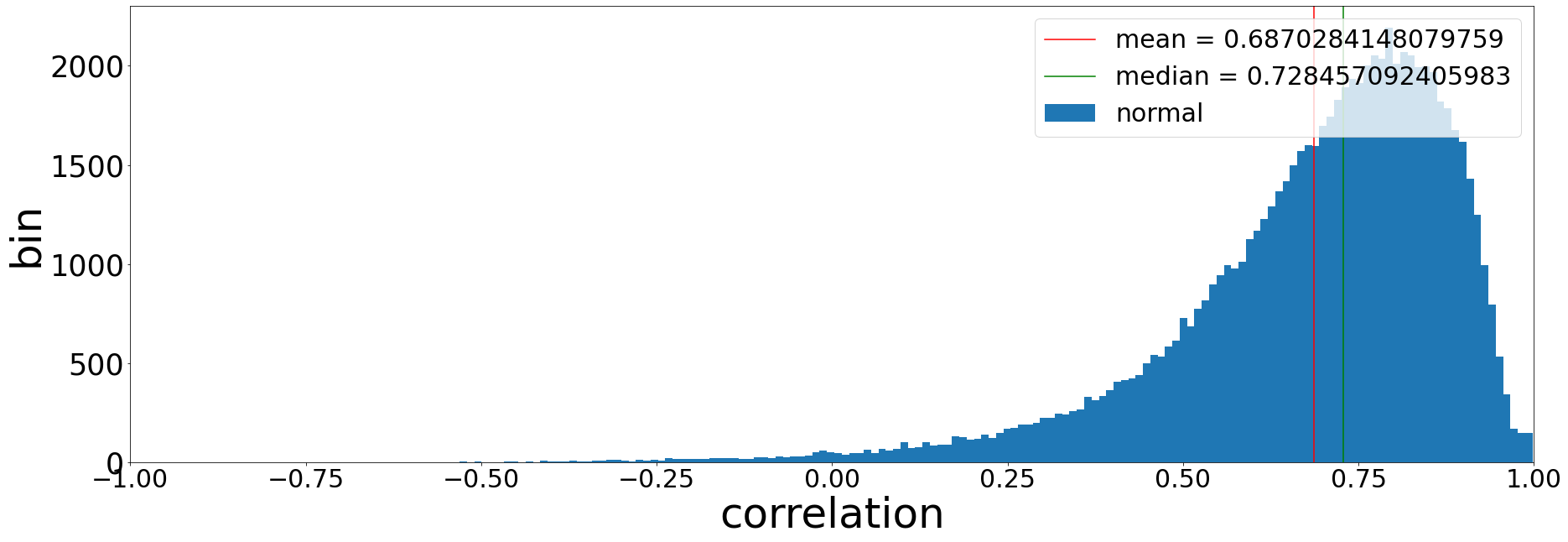 (60000epoch)
(60000epoch)
할맛난다! 상관계수값이 0.7~0.8정도면 쓸만하다는 소리를 듣긴했는데..
하지만 아무리해도 이러한 양상의 loss 그래프밖에 안나온다
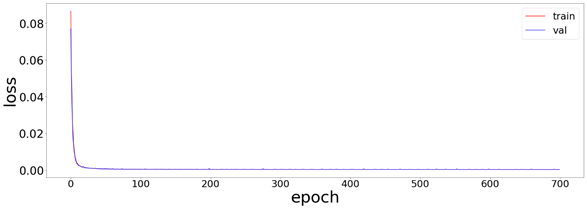
이상적인 loss그래프의 경우, 특정부분부터 validation의 loss값이 커져버리면서, 그 직전의 epoch가 가장 학습이 잘 된 모델이며, 그 이후부터는 과적합 현상이 일어난것이라고 한다.
난 왜 이상적인 loss그래프가 안나오는지 항상 고민이었는데, 그냥 epoch가 작아서 그런가? 라는 생각이 든다
우리 torch는 문제가 없었는데.. for문을 남발한 내가 문제였던 것이다..
학습에 필요한 기법을 왠만하면 내가 스스로 코딩하여 사용하고 있었는데
그냥 pandas, numpy가 다 해놨다. 내가 짠것보다 훨씬 빠르다
물론 내가 공부한건 사라지진 않겠지만, 좀 더 pandas, numpy의 위대함을 깨달아야 했다
지금 epoch를 엄청나게 늘려서 시행중이다.. 내가만든 오토인코더가 과적합 현상을 볼 때 까지..
USAD코드도 epoch를 엄청나게늘려서 해보고 있다
USAD같은경우는 논문에서 사용된 데이터셋에 비해 내가 쓰고있는 논문의 변수의 수? 차원? 이 좀 적어서 결과가 안나오나 싶었는데.. 잘나왔음 좋겠네
끝.
