Sliding Window
Sliding Window 기법이란?
데이터를 늘리기 위한 기법(Augmentation기법.. 이라고 할 수 있을듯?)
시계열 데이터가 많지 않을때 데이터셋을 늘리기 위해 사용하며
window size는 시계열 데이터의 특성을 고려하여 설정함
Code
window_sliding_data = time_series_data.values[np.arange(window_size)[None, :]
+ np.arange(time_series_data.shape[0]-window_size)[:, None]]원래는 pytorch 딥러닝입문책에서 보던 for문 엄청나게 쓰는 코드를 참고해서 썼다.
근데 속도가 너무 느리지만 참고 썼다..
그런데..
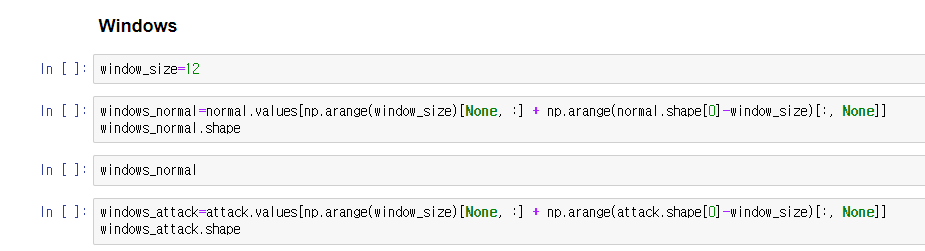
최근 USAD 논문을 계속 보고있는데.. 이 연구에서도 window slide 기법을사용하였다
근데 코드가 너무 간결하더라.. 속도도 기존에 내가쓰던 for문 덕지덕지바른 코드보다 훨씬 빠르다
잡담
학습데이터 처리과정에서 너무 시간이 오래걸렸었다
특히 데이터를 쌓는 과정과, window sliding 하는 과정에서 시간이 많이 소요됬었는데
처음에는 list형 보다 dataframe형이 그냥 무거워서 인줄 알았다
근데 그냥 for문을 사용하니 그런거더라
for문은 최대한 사용하면 안된다는 깨우침을 얻었다
끝.

인공지능 초보