개요
MySQL이 인덱스를 어떤 식으로 사용해서 실제 레코드를 읽어내는지 알아보자.
인덱스 스캔
인덱스 레인지 스캔
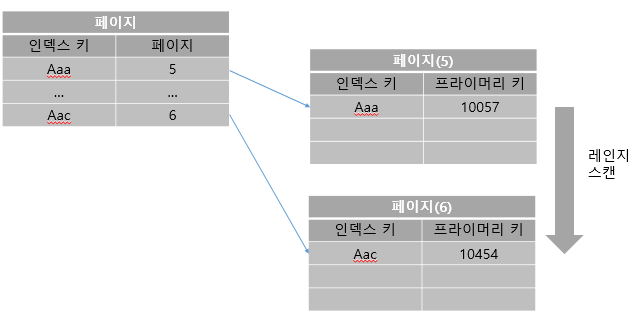
인덱스 레인지 스캔은 인덱스의 접근 방법 가운데 가장 대표적인 접근 방식이다. 나머지 두가지 접근 방식보다 빠르다.
인덱스 통해 레코드를 한 건만 읽는 경우와 한 건 이상을 읽는 경우를 각각 다른 이름으로 구분하기는 한다.
인덱스 레인지 스캔은 검색해야 할 인덱스의 범위가 결정됐을 때 사용하는 방식이다. 검색하려는 값의 수나 검색 결과 레코드 건수와 관계 없이 레인지 스캔이라고 표현한다.
일단 시작할 위치를 찾으면 그 때부터는 리프노드의 레코드만 순서대로 읽으면 된다. 이처럼 차례대로 쭉 읽는 것을 스캔이라 표현한다. 만약 스캔하다가 리프노드의 끝까지 읽으면 리프 노드 간의 링크를 이용해 다음 리프노드를 찾아가서 다시 스캔한다.
B-Tree 인덱스에서 루트와 브랜치 노드를 이용해 스캔 시작 위치를 검색하고 그 지점 부터 필요한 방향으로 인덱스를 읽어 나가는 과정을 확인할 수 있다.
어떤 방식으로 스캔하든 관계없이, 해당 인덱스를 구성하는 칼럼의 정순 또는 역순으로 정렬된 상태로 레코드를 가져온다는 것이다. 이는 별도의 정렬 과정을 거치는 것이 아니라 인덱스 자체의 정렬 특성 때문에 자동으로 그렇게 된다.
한가지 중요한것은 인덱스의 리프노드에서 검색 조건이 일치하는 건들은 데이터 파일에서 레코드를 읽어오는 과정이 필요하다는 것이다. 이 때 리프노드에 저장된 레코드 주소로 데이터 파일의 레코드를 읽어오는데, 레코드의 한 건 한 건 단위로 랜덤 I/O가 한 번 씩 일어난다.
이 때 쿼리가 필요로 하는 데이터가 인덱스에 관한 정보만 필요로 한다면 레코드에 대한 랜덤 I/O가 일어나지 않는다. 이를 커버링 인덱스라고 하며, 디스크의 레코드를 읽지 않아도 되기 때문에 랜덤 읽기가 줄어들고 성능은 그만큼 빨라진다.
인덱스 풀 스캔
인덱스의 처음부터 끝까지 모두 읽는 방식을 인덱스 풀스캔이라 한다.
대표적으로 쿼리의 조건절에 사용된 칼럼이 인덱스의 첫 번째 칼럼이 아닌 경우 인덱스 풀 스캔 방식이 사용된다.
일반적으로 인덱스의 크기는 테이블의 크기보다 작으므로 직접 테이블을 처음부터 끝까지 읽는 것보다는 인덱스만 읽는 것이 효율적이다.
쿼리가 인덱스에 명시되니 칼럼만으로 조건을 처리할 수 있는 경우 주로 이 방식이 사용된다.
인덱스 뿐만 아니라 데이터 레코드 까지 모두 읽어야 한다면 절대 이 방식으로 처리되지 않는다.
인덱스 리프 노드의 제일 앞 또는 제일 뒤로 이동한 후, 인덱스의 리프 노드를 연결하는 링크드 리스트를 따라서 처음부터 끝까지 스캔하는 방식을 인덱스 풀 스캔이라 한다. 인덱스 레인지 스캔보다는 빠르지는 않지만 테이블 풀 스캔보다는 효율적이다. 앞에서도 언급했듯이 인덱스에 포함된 칼럼만으로 쿼리를 처리할 수 있는 경우 테이블의 레코드를 읽을 필요가 없다.
인덱스 전체 크기가 테이블 자체의 크기보다는 훨씬 작으므로 인덱스 풀 스캔은 테이블 전체를 읽는 것보다는 적은 디스크 I/O로 쿼리를 처리 가능
루스 인덱스 스캔
느슨하게 듬성듬성하게 인덱스를 읽는 것
인덱스 레인지 스캔과 비슷하게 작동하지만 중간에 필요치 않은 인덱스 키 값은 무시하고 다음으로 넘어감
일반적으로 GROUP BY 또는 집합 함수 가운데 MAX() 또는 MIN()함수에 대해 최적를 하는 경우 사용
인덱스 리프 노드를 스캔하면서 불필요한 부분은 그냥 무시하고 필요한 부분만 읽음
인덱스 스킵 스캔
인덱스의 핵심은 값이 정렬돼 있다는 것, 이로 인해 인덱스를 구성하는 칼럼의 순서가 매우 중요
인덱스 스킵 스캔과 비슷한 최적화를 수행하는 루스 인덱스 스캔은 GROUP BY 작업을 처리하기 위해 인덱스를 사용하는 경우에만 적용 가능했음.
MySQL 8.0 버전에 도입된 인덱스 스킵 스캔은 WHERE 조건절의 검색을 위해 사용 가능하도록 용도가 훨씬 넓어짐
- type: range
- Extra:Using index for skip scan
단점
- 인덱스 스킵 스캔은 인덱스의 선행 칼럼이 가진 유니크한 값의 개수가 소량일 때만 가능하다.
- 쿼리가 인덱스에 존재하는 칼럼만으로 처리 가능해야함 (커버링 인덱스)
다중 칼럼 인덱스
2개 이상의 칼럼을 포함하는 인덱스를 다중 칼럼 인덱스라고 하며, 또한 2개 이상의 칼럼이 연결되었다고 해서 Concatednated Index 라고도 한다.
루트 노드와 리프노드는 항상 존재하지만, 브랜치 노드는 없는 경우도 있을 수 있다.
다중 칼럼 인덱스일 때 각 인덱스를 구성하는 칼럼의 값이 어떻게 정렬되어 있는지 보자.
인덱스의 두 번째 칼럼은 첫 번째 칼럼에 의존해서 정렬돼 있다는 것이다.
출처
RealMySQL
