Unix File System
Unix (Linux) File System
- 파일 시스템은 파일을 저장소에 저장하는 로지컬한 구조를 가짐
- 파일 시스템은 '/' 부터 시작하는 트리 모양
- 마운트 : 여러가지 디바이스를 하나의 파일 시스템에 마운트 하는게 가능
- ex) 4GB SSD에 저장된 파일 시스템이 있고, 2TB HDD에 대한 파일 시스템이 있을 때, 두가지 파일 시스템을 하나의 파일 시스템 으로 묶어서 관리하는 것, (HDD 파일시스템을 SSD 파일 시스템의 HOME 디렉토리로 마운트한다)
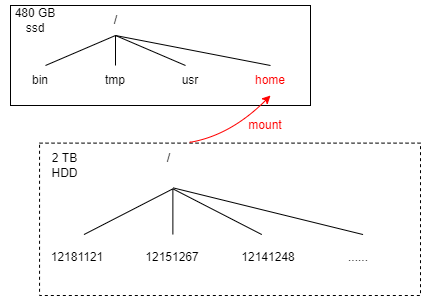
- ex) 4GB SSD에 저장된 파일 시스템이 있고, 2TB HDD에 대한 파일 시스템이 있을 때, 두가지 파일 시스템을 하나의 파일 시스템 으로 묶어서 관리하는 것, (HDD 파일시스템을 SSD 파일 시스템의 HOME 디렉토리로 마운트한다)
Unix (Linux) File System
- 앞서말한 것은 로지컬한 구조, 실제로는 이전주차에서 보여준 i-node blocks과 data blocks들로 이루어지며, 여기서 추가적으로 bootstrap block과 super block이 있음
- Bootstrap area
- 컴퓨터가 부팅될때 실행되어야 하는 코드. 이것은 여러 디바이스 시스템중 하나의 파일 시스템에서만 존재해야함.
- Super block
- i-node block들은 각각의 파일들에 대한 정보를 담지만, Super block은 파일 시스템에 대한 정보를 가짐. 앞에서 각각의 디바이스들은 모두 파일시스템을 가지고 있기 때문에 마운트를 통해 묶는것이 가능하다고 함. 고로 파일시스템이 여러개기 때문에 Super block 역시도 여러개를 가짐. (반면 Bootstrap 은 여러 디바이스 시스템중 하나의 파일 시스템에서만 존재해야함)
- Super block이 관리하는 정보 :
- 파일 시스템에서 total number of blocks
- i-node free list에서 i-node의 수
- the size of block in bytes
- the number of free blocks
- the number of used blocks
- i-node blocks
- 앞주차에서 설명한 바와 같은 파일에 대한 정보를 가짐
- Data blocks
- 파일 데이터
Caching
- file system에서 Super block은 자주 접근 되는 block임. 그대신 많은 정보를 담고 있지 않기 때문에 빠른 접근이 가능해 자주 반영 될 수 있는 것임
- os는 memory에서 disk로 write를 할때 항상 disk로 직접 write하는 것이 아니라, buffer에 write해놨다가, 파일을 사용할 일이 생길때 한번에 buffer에 있던 정보를 write를 함 (memory - disk 접근 시간이 너무 길기 때문에 한번에 한다.)
- 이때 sync()와 fsync()와 같은 시스템 콜을 통해 buffer에 저장된 내용을 disk로 write를 함
System Call: sync(2) and fsync(2)
- 메모리에 있는 data를 disk에 반영하는 시스템 콜
- sync는 모든 파일시스템에 있는 buffer내용을 write
- fsync는 특정 파일만 선택해 그 파일과 관련된 내용을 write
- 중요한 차이점 : sync는 모든 파일에 대한 write가 끝날 때 까지 기다려주지 않고 그냥 리턴함. 반대로 fsync는 특정 파일에 대한 write만 기다리기 때문에 write가 끝날 때 까지 기다렸다가 return함
- sync는 그래서 일반 user 프로그램이 보통 사용하는 call이 아닌 os가 반복적으로 호출하는 call임
4.6 Unix (Linux) Device Files
- 지금까지 regular, directory파일을 봤으니 이번엔 device file
Device of Unix (Linux)
- 각각의 디바이스들은 디바이스 넘버를 받는데, 하나는 major number, 하나는 minor number
- major number : device의 type을 구분해줌
- minor number : type안에서 몇번째인지 구분해줌
- 이때 유저들은 device number를 통해 device를 접근하는 것이 아니라 device 파일을 통해 접근한다.
Device of Unix (Linux)
- peripheral device
- 파일 시스템에서 파일 이름을 통해 접근
- 이 디바이스 파일들은 하드디스크 data block에 공간을 차지하고 있지 않음. 즉, 그냥 device 그 자체임. 만약 device 파일을 read, write한다는 것은 실제 device로 접근해 read, write를 한다는 것을 의미
- 이 디바이스 파일들은 '/dev'라는 directory에 저장되어 있음
- /dev/tty00
- /dev/lp
- /dev/pts/as
- 디바이스 파일들은 레귤러 파일처럼 사용됨
Block and Character Device Files
-
Block Device file
- block 단위로 접근하는 것. 데이터를 보낼때 항상 block 단위로 보내짐
- random access가 가능함 = 주소가 주어지면 바로 접근이 가능함 (반대되는 개념은 sequential access )
- file system은 block devices로만 구성이 가능하다.
※ Raw device : block device지만, character device처럼 사용가능한 디바이스.(block으로 접근하는 것이 아닌 직접적인 접근이므로 fast access가 가능하다 하지만 전체 파일 시스템이 raw device로 구성되면 전체적으로는 느려짐->느려지는 이유는 데이터베이스 내용.. )
-
Character Device file
- Block device file과는 다르게 character 단위로 접근이 가능함.
- ex) terminal, printer, network
- random access가 보통은 불가능함 (가능한 경우도 있음)
- 데이터를 한바이트씩 이동시킬 수 있고, 여러개씩 이동시킬 수도 있음
Block and Character Device Files
-
두가지 peripheral device와 상호작용을 위한 configuration tables들이 있음
- block device switch table
- character device switch table
-
두가지의 테이블들은 device file의 i-node에 저장된 major device number 값을 이용해 indexing 되어있음

Block and Character Device Files
-
peripheral device로 데이터를 받거나 보낼때 순서
- read, write system call을 통해 device file의 i-node로 접근한다.(레귤러파일, 디렉토리 파일과 똑같음)
- 시스템이 i-node 구조체를 보고 이것이 어떤 파일인지 확인하고, device파일이면, 이것이 또 block device 파일인지, character device 파일인지 검사한다.
- major number와 minor number를 가져옴
- 적절한 configuration table을 선택하고, major number를 사용해 해당 index의 device로 이동함.
- minor number를 통해 device의 적절한 port 번호를 찾는다.

Revisiting stat structure
struct stat{
mode_t st_mode; // 파일의 타입, 모드 (권한 = permission)
ino_t st_ino; // i-node 번호
dev_t st_dev; // device 번호
dev_t st_rdev; // special 파일에대한 device 번호
nlink_t st_nlink; // link 카운트
uid_t st_uid; // user id of owner
gid_t st_gid; // group id of owner
off_t st_size; // byte 크기 (for regular files)
time_t st_atime; // 마지막 접근 시간
time_t st_mtile; // 마지막 수정 시간
time_t st_ctime; // 마지막 상태 수정 시간
blksize_t st_blksize; // block size (for file system i/o
blkcnt_t st_blocks; // 할당된 disk block 수
};| type | special | permission |
|---|---|---|
| 4bit | ugs | rwxrwxrwx |
binary 0001 -> FIFO
binary 0010 -> character device
binary 0100 -> directory
binary 0110 -> block dev
binary 1000 -> regular
binary 1010 -> symolic link
- st_mode 즉 권한은 사실 16bit임 상위 4bit를 통해 파일의 종류를 파악 (directory 파일인지, 레귤러 파일인지, 디바이스 파일인지) 이때 디바이스 파일이면 character device 파일인지, block device 파일인지도 구분 가능
- st_rdev : 디바이스의 major and minor number
File System Information
#include <sys/statvfs.h>
int statvfs(const char *path, struct statvfs *buf);
int fstatvfs(int fd, struct statvfs *buf)- 파일 시스템의 정보를 읽어오고 싶을 땐, statvfs, fstatvfs를 사용함 (return 0 on success, -1 on error)
struct statvfs {
unsigned long f_bsize //File system block size
unsigned long f_frsize //Fundamental file system block size
fsblkcnt_t f_blocks //Total number of blocks on file system in unis of f_frsize
fsblkcnt_t f_bfree //Total number of free blocks
fsblkcnt_t f_bavail //The number of free blocks available to non-privileged process
fsfilcnt_t f_files //Total number of i-nodes
fsfilcnt_t f_ffree //Total number of free i-nodes
fsfilcnt_t f_favail //The number of i-nodes available to non-privileged process
unsinged long f_fsid //File system ID
unsigned long f_flag //Bit mask of f_flag values
unsigned long f_namemax //Maximum file name length
};| f_flag | Description |
|---|---|
| ST_RDONLY | The file system is mounted for read-only access. |
| ST_NOSUID | The file system does not support setuid/setgid semantics. |
| ST_CHOWN_RESTRICTED | The file system restricts the changing of the owner or primary group to a process that has the appropriate privileges. |
| ST_THREAD_SAFE | The file system is thread-safe. Thread-safe APIs may operate on objects in this file system in a thread-safe manner. |
| ST_DYNAMIC_MOUNT | The file system allows itself to be dynamically mounted and unmounted. |
| ST_NO_MOUNT_OVER | The file system does not allow any part of it to be mounted over. |
| ST_NO_EXPORTS | The file system does not allow any of its objects to be exported to the Network File System (NFS) Server. |
| ST_SYNCHRONOUS | The file system supports the "synchronous write" semantic of NFS Version 2. |
| ST_CASE_SENSITIVE | The file system is case sensitive. |
System Call: pathconf(2) and fpathconf(2)
# include <unistd.h>
long pathconf(const char *pathname, int name);
long fpathconf(int filedes, int name);- 파일 시스템에서 특정 파일의 정보를 얻을 때 사용하는 system call (return corresponding value on success, -1 on error)
- name argument에 들어오는 값에 따라 그에 상응하는 정보를 리턴함
- _PC_LINK_MAX : The maximum file link count
- _PC_NAME_MAX : The maximum number of bytes in a file name
- _PC_PATH_MAX : The maximum number of bytes in a pathname
- …
5. The Process -1
Function: main
- Main 함수의 프로토타입
int main(int argc, char *argv[]);- argument들
- argc : command-line에서 argument의 총 수
- argv : argumet array
- ex) ./a arg1 test foo
- argc = 4,
- argv[0] = ./a
- argv[1] = arg1
- argv[2] = test
- argv[3] = foo
- c program이 실행된다는 것은 main 함수를 호출한다는 것을 의미. 이때 main 함수가 호출 되기 전 c program이 exec 함수로 호출이 되면, specail start-up routine을 진행함
- start-up routine
- commadn-line의 argument를 재가공, 정리
- 환경변수 셋팅 (환경 변수는 뒤에서 좀 더 자세히 설명)
Memory Layout of C Program
- C program은 다음과 같은 것으로 구성됨
- text segment
- 초기화된 전역 변수
- int max_count = 99;
- 초기화되지 않은 전역 변수
- long sum[1000]; -> bss 영역에 이만큼 들어가야한다고 요청
- 그러면 kernel은 공간을 그만큼 할당해주고 0이나 null로 초기화 시킨다.
- Stack : 함수내의 지역변수
- Heap : 동적 할당 메모리
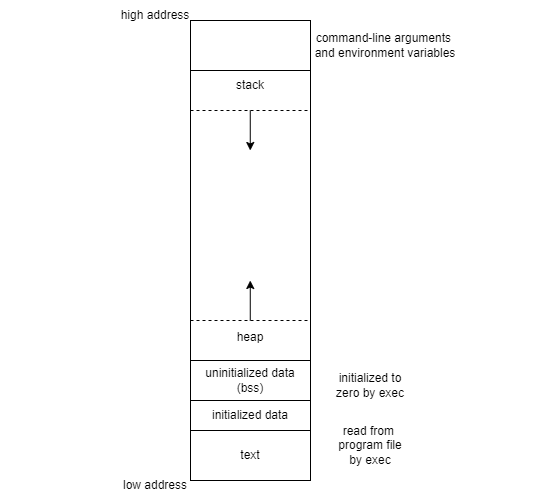
Memory Layout of C Program
/* init.c */
int init_array[50000]={0};
int main() {
return 0;
}/* noninit.c */
int noninit_array[50000];
int main() {
return 0;
}$ gcc –o init init.c
$ gcc –o noninit noninit.c
$ ls –l init noninit
-rwxr-xr-x 1 root root 214604 17 Aug 12:00 init
-rwxr-xr-x 1 root root 14598 17 Aug 12:00 noninit
$ size init noninit
text data bss dec hex filename
706 200272 4 200982 31116 init
706 252 200032 200990 3111e noninit- init.c에서 init_array[50000] = {0};은 index 0번만 초기화하고 나머지는 초기화하지 않는 구문이지만 실제로 모두 초기화 영역에 들어가서 전부 초기화 됨
- 이때 밑의 bash에서 메모리 크기를 확인해 보면 init 파일은 data 영역이 매우크고, bss 영역이 작으나 noninit.c 파일의 data영역의 크기는 작지만 bss영역의 크기는 큰 것을 알 수 있음.
5.1 Review of the notation of a process
- process관련 시스템 콜들
Process
- 간단히 말하면 실행되고 있는 프로그램을 의미 (프로그램 = 실행 파일)
- process는 코드, data value(program variables), hardware register, Program stack으로 구성됨
- process는 pid라는 특정 번호를 부여해 관리받음
- shell은 새로운 프로세스를 만듬
- ex) cat file1 file2 (user shell이 cat 프로세스를 생성)
5.2 Creation process
System Call: getpid(2), getppid(2)
# include <unistd.h>
pid_t getpid(void);
pid_t getppid(void);- getpid는 자신의 pid를 리턴
- getppid는 부모 프로세스의 pid를 리턴
System Call: fork(2)
# include <unistd.h>
pid_t fork(void);- 나와 똑같이 생긴 프로세스를 하나 더 만드는 것
- 리턴을 두번 하기 때문에 이를 구분하기 위해 두 프로세스의 리턴값이 다름
- process가 fork()를 해서 자식 process를 만들때, 자식 process는 0을 return하고, 부모 process는 자식 process의 pid를 리턴함. 그리고 return -1 on error
- Limit error (EAGAIN)
- process의 maximum수가 존재
System Call: fork(2)
-
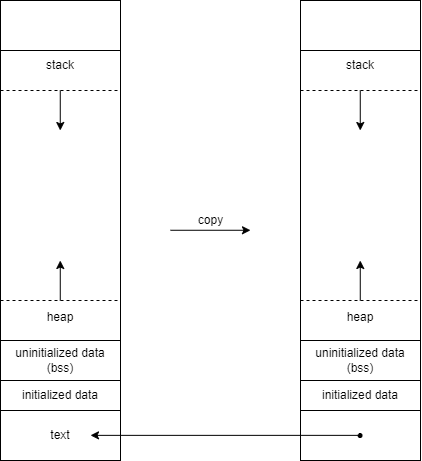
복사된 프로세스는 거의 똑같은 프로세스지만 약간 다른면이 있음 ex) pid
-
자식 프로세스는 부모 프로세스의 데이터 영역, 힙, 스택을 복사함
-
자식과 부모는 메모리를 공유하지는 않음
-
대신 부모와 자식은 text segment를 공유함
-
부모와 자식중 어떤것이 먼저 수행 될지는 아무도 모름 (커널의 스케쥴링 알고리즘에 달려있음)

-
부모는 자식 프로세스의 pid를 리턴, 자식은 0을 리턴(0번 process는 존재하지 않기 때문에) 여기서 헷갈리지 말아야 할 점은 return value의 변수 이름이 pid 라고해서 return 값이 프로세스의 pid를 의미하는 것은 아님.
5.3 Running new program with exec
- fork()를 통해 process를 복제하는것 자체는 사실 크게 의미는 없고 비효율적인 활동이라고 볼 수 있음. 왜냐면 똑같은 프로세스가 의미없이 두개의 메모리를 차지하며 돌아가는 것이기 때문. 따라서 복제된 프로세스가 기존 프로세스와 다른 일을 하도록 exec을 호출해야 fork를 하는 의미가 생김. 결국 fork를 통해 프로세스를 복제하고 exec을 통해서 새로운 일을 하도록 해서 새로운 프로세스를 생성 하는 것임.
- 왜 이런식으로 새로운 프로세스를 만들까? -> 아예 처음부터 만드는 것보다 기존의 것을 복제하고 덮어 씌우는 것이 오버헤드가 훨씬 적기 때문.
The exec family
- exec family는 새로운 프로그램의 실행을 의미. (execl,execv,execle,execve,execlp,execvp)
- pid는 바뀌지 않으며 그냥 해당 프로세스에서 돌아가는 프로그램이 바뀌는 것임
- 따라서 exec은 현재 프로세스의 text, data, heap, stack 영역을 바꾸는 활동을 의미함.
- 다양한 exec이 있지만 결국엔 execve 형태로 바꿈

The exec family
# include <unistd.h>
int execl(const char *pathname, const char *arg0, …, NULL);
int execv(const char *pathname, char *const argv[]);
int execle(const char *pathname, const char *arg0, …, NULL, char *const envp[]);
int execve(const char *pathname, char *const argv[], char *const envp[]);
int execlp(const char *filename, const char *arg0, …, NULL);
int execvp(const char *filename, char *const argv[]);※ l: list of argument
※ v: vector of argument
※ e: environment -> 환경변수를 추가
※ p: with path environment -> 파일 이름을 줌
ex) non p -> ./ls , /bin/ls
p -> ls 그러면 ls가 어디있는지 찾아야하는데, 어디있는지는 환경변수를 통해 알아옴
환경 변수는 PATH = :/bin:/usr/bin 이런 형태로 되어있는데 콜론은 경로를 구분하는 것을 의미함. 따라서 /bin에서 먼저 찾고 없으면, /usr/bin에서 찾고, 여기서도 없으면 error를 리턴
- no return on success, -1 on error
