비트, 바이트 데이터 타입
저희가 이제 수업에 들어가 얘기를 해야할 첫번째가 데이터 리프레젠테이션입니다. 비트, 바이트 그리고 데이터 타입스
비트가 뭐냐, 0과 1이죠 0아님 1을 저장할 수있는 최소 유닛이에요 . 이거보다 작은 것은 없습니다. 그리고 이거를 8개 붙여놓으면 바이트 이제 왜 8개냐 하는 거는 여러가지 썰이 있는데 사람들마다 뭐가 맞다라고 하는데 제가 생각하는 이유는 하드웨어적인 이유라고 생각해요. 바이트라는 특정 사이즈가 옛날에 생긴 초창기 컴퓨터에서는 8개를 한번에 처리할 수 있는게 최선이었다. 그래서 8개를 붙여서 처리한다. 그리고 다른 사람들은 또 이런 얘기도 해요. 캐릭터 문자 하나를 표현하기 위한 최소한의 사이즈다. 그래서 이 바이트 사실 바이트가 현재는 그렇게 의미는 없어요 왜냐하면 32bit, 64bit 머신이 대부분인데 거의 요즘 64bit 머신만 나오고 있죠 64bit 머신은 8바이트 머신이에요. 왜 64bit나면, 인스터럭션도 그렇고 하드웨어가 한번에 처리하는 데이터의 양이 저만큼이에요. 64bit을 한번에 처리해요. 그래서 상식적으로 많이 처리하면 빠르겠죠. 많이 처리해서 빠르다 말고 또 다른 장점이 데이터 리프레젠테이션입니다. 데이터 리프레젠테이션이 무슨말이나면 64bit로 2^64승의 데이터를 리프레젠테이션 할 수 있다는 거에요. 아무튼 이런 장점이 있어서 64bit을 사용하고요.
다음엔 32bit랑 64bit 관련해서 데이터 타입들을 정리를 해놨습니다.
| C data type | Typical 32-bit | Typical 64-bit | x86-64 |
|---|---|---|---|
| char | 1 | 1 | 1 |
| short | 2 | 2 | 2 |
| int | 4 | 4 | 4 |
| long | 4 | 8 | 8 |
| float | 4 | 4 | 4 |
| double | 8 | 8 | 8 |
| long double | n/a | n/a | 10 (AMD)/16 |
| pointer | 4 | 8 | 8 |
char, short, int까지는 숫자를 넣기위해서 만들어진 타입들이고요 그 뒤 double, float 이런 애들은 소숫점이 있는 숫자들을 넣기 위해서 만들어졌습니다. 사이즈를 보시면 몇가지 타입들은 32bit 머신이나 64bit 머신이나 동일하게 가는데 몇가지가 두배로 늘어났을 거에요. long 같은게 늘어났고 long double이라는게 없었던게 생겨났고 포인터도 이제 활발해서 늘어났죠. 포인터가 늘어나는 이유를 생각해 봐야돼요
포인터라는게 주소를 넣는 변수죠, C언어에서 메모리 주소를 넣기위한 변수가 포인터인데 4byte(2^32승)으로 했더니 메모리 사이즈가 점점 커지고 하면서 이 변수 사이즈 가지고 표현할 수 있는 주소가 모자라기 시작한거에요. 사실 여러분이 사용하고 있는 맥이나 데스크탑 같은 경우는 메모리 사이즈가 테라바이트 단위일 거에요. 기가바이트 단위가 대부분 8기가 16기가 이정도면 32bit 단위에서도 사실 충분한데 사실 이 system specification을 정의하는 사람들은 렙탑이나 데스크탑을 타깃으로 하지 않아요. 얘네들은 현존하는 가장 강력한 컴퓨터를 기준으로 합니다. 슈퍼컴퓨터 같은 것들을 기준으로 하는데 슈퍼컴퓨터들은 메모리 사이즈가 테라 후반이에요. 메모리 사이즈가 그러면 이제 모자란거에요. 그래서 이렇게 늘린거에요. 이것도 다른 이유중 하나에요 64bit 머신으로 가는.
불린, 로지컬, 쉬프트, 산술 연산
일단 여기까지가 C언어에서 데이터를 어떻게 리프레젠테이션 하는지에 대해 짧게 설명을 했고요, 그다음엔 C언어에 있는 오퍼레이션들에 대해서 볼거에요.
boolean algebra
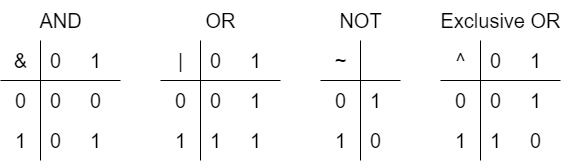
다음은 비슷하게 생긴 로지컬 오퍼레이션이라는게 있어요
| Operator | Description |
|---|---|
| && | Logical AND |
| || | Logical OR |
| ! | Logical NOT |
두 종류가 있는데 AND가 두개인 거랑 OR가 두개있는거. 여기서 Early termination이라고 하는게 있는데 이게 C가 가지고있는 굉장히 특수한 기능이에요. Early termination이 뭐냐면 C언어는 기본적으로 호스트 랭기지라서 효율성을 굉장히 중요시합니다. 효율성이라고 하면 시간이 짧은 걸 효율적이라고 하셨죠. 예를들어 if(false && true)가 있다고 할때 두개를 보고 AND를 해서 결과를 보면 false니까 넘어가야지, 이렇게 동작하지 않아요. C는 컴파일 타임에 먼저 operation이 뭔지 봅니다. operation이 뭔지 보고 AND라고 operation을 먼저 확인했어요. 그 다음에 순서대로 봐야겠어요. 변수를 여기 봤는데 false야, 그러면 뒤에 뭐가나올지 상관없이 그냥 false로 리턴해요. 뒤에거 안봐요 이게 early termination 인데 이게 굉장히 유용한 트랙이에요. 그래서 그 뒷장에 얘를 한 5개 써놨는데 아웃풋은 당연히 계산해 보면 알텐데 얼리 터미네이션 칼럼에 왜 Y하고 N이 됐는지 확실하게 이해하고 넘어가면, 굉장히 유용할 거에요.
| Expression | Output | Early termination |
|---|---|---|
| 0x11 && 0x00 | 0 | N |
| !0x23 && 0x1 | 0 | Y |
| 0x00 || 0x01 || 0X00 | 1 | Y |
| !0x00 && 0x01 | 1 | N |
| 0X00 && 0x12 || 0X01 | 1 | N |
다음은 Shift operation이에요 이거는 별거 아니고요 left shift, right shift 이름 그대로 하면돼요. left shift는 왼쪽으로 밀고 right shift는 오른쪽으로 밀고. 이때 3개를 shift한다고 했을 때 어떤게 들어오느냐 에따라 shift 종류가 달라집니다. 일단 left shift는 0만 들어옵니다. right shift는 0만 들어올 수도 있고, most significant bit에 따라 들어오는게 달라질 수도 있습니다. 0만 들어오는 것을 logical shift라고 하고 msb가 들어오는 걸 arithmetic shift라고 해요. 이게 왜 arithmetic shift냐면 산술 쉬프트가 뭐냐면 이 most significant bit은 부호를 나타낼 수 있어요. 데이터를 어떻게 보느냐에 따라서 이거를 숫자로 안보고 데이터 비트로 보면 0으로 들어가는게 맞아요 그래서 이걸 logical shift라고 보고 얘를 그냥 밋밋한 데이터가 아니라 숫자로 보겠다 음수, 양수로 보겠다 라고하면 arithmetic shift를 합니다.
| Data type | Bytes | Data range |
|---|---|---|
| char | 1 | -128 ~ 127 |
| unsigned char | 1 | 0 ~ 255 |
| short | 2 | -32,768 ~ 32,767 |
| unsigned short | 2 | 0 ~ 65,535 |
| int | 4 | -2,147,483,648 ~ 2,147,483,647 |
| unsigned int | 4 | 0 ~ 4,294,967,295 |
| long | 8 | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 |
| unsigned long | 8 | 0 ~ 18,446,744,073,709,551,615 |
그 다음장에 보면 integer가 있습니다. integer를 왜 따로 슬라이드를 하나를 가지고 있냐, integer는 기본이에요. integer는 숫자를 나타내고 discrete한 숫자를 나타내는 representation이고요 여기 보시는대로 몇가지 타입이 있는데 그냥 4개밖에 없어요
1byte, 2byte, 4byte 이렇게 있는데 부호를 신경쓸거냐 안쓸거냐에 따라서 unsigned가 붙습니다. 거기다가 위에 숫자 승 하면 몇가지 데이터를 리프레젠테이션 할 수 있는지 나오죠, 그래서 예를들어 char, 1byte니까 2의 8승, 및 256이죠 그래서 256까지 다른 데이터들을 리프레젠트 할 수 있습니다. 그래서 밑에 short, int , long은 그냥 길이가 늘어나는 거니까 단순한 수 계산해보면 보이겠죠.
다음은 음수입니다. 음수를 어떻게 표현하는지에 대해 여러가지 방법이 있는데 현재 모든 컴파일러에서 사용하고 있는 Two's complement를 보고 넘어갈 거에요. 왜 Two's complement라 하냐면 음수를 계산할 때 그냥 음수를 딱 쓰는게 아니라 양수에서 complement를 합니다. 양수를 뒤집어요 그리서 complement라고 하는데 step이 3개에요.
일단 양수를 써요 그다음에 뒤집어요 비트를 모두 뒤집어요 그다음 맨마지막에 1을 더해줍니다. 끝이에요. 이게 Two's complement고요 그럼 이걸 왜쓰냐 두가지 이유가 있습니다. 하나는 하드웨어 측면에서 구현하기가 쉬워요. 그냥 딱 봤을 때 그냥 뒤집고 1 더하면 되잖아요.
두번째는 덧샘 뺄셈이 엄청나게 쉬워요. 여기 Example 1,2,3이 있는데 이게 다 덧셈이에요. 덧셈인데 보시면 다른 로직이 별도로 없고 그냥 더하면 됩니다. 진짜로 마이너스 1이랑 1이랑 더하고 싶으면 Two's complement 써놓고 그냥 더하면 별도 로직없이 음수 덧셈이 됩니다. 음수 덧셈은 뺄셈이죠. 뺄셈을 별도 로직없이 덧셈 로직 가지고 구현할 수 있다. 그래서 Two's complement는 여러가지 이유로 효율적이어서 사용한다.
여기까지해서 C언어랑 유닉스 기반 시스템들이 제공하는 operation들을 봤습니다. 그래서 본인들이 어떤 코딩을 하든 무슨 프로그램을 짜든지간에 여지껏 살펴봤던 오퍼레이션들 중에서 골라서 사용을 해서 코딩을 할 거에요.
이제 세번째 주제인데 메모리와 포인터입니다. C언어의 철학은 자유에요. 니가 뭘 하든 나는 신경 안쓸테니까 잘 써라에요. 그래서 메모리를 할당도 네 마음대로 하고, 다 니 마음대로 하는데 문제생기면 니탓이다. 이게 C에요. 이게 무슨 소리냐면, C프로그램이 유닉스 기반의 시스템에 돌아갈 때 메모리를 어떻게 쪼개는지부터 봅시다. 일단 프로그램 하나를 돌렸다고 해요. 이게 진짜 중요한 기초 개념인데요,
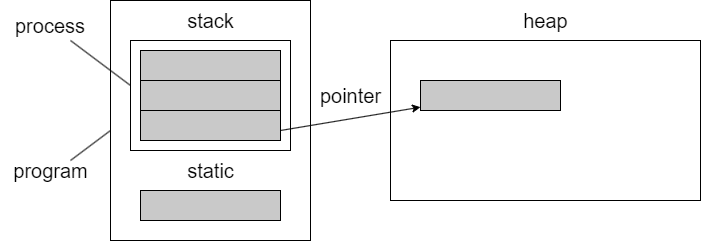
이 그림은 본인이 그냥 그리라고 하면 그릴 수 있을 정도로 기억을 해놓으세요. 요즘 세상에 프로세스 하나인 프로그램은 거의 없습니다. 멀티 프로세스죠 근데 그래서 메모리도 프로세스 각각 가지고 있는 메모리가 있고요. 그 여러개의 프로세스들이 공유하는 메모리가 있어요 여기 공유하는 메모리 공간을 static이라고 합니다. 그리고 프로세스 specitic한 메모리 공간을 stack이라고 해요. 그래서 지금 두개 나왔습니다. stack, static. 그리고 프로그램 외부에 운영체제가 관리하는 커다란 메모리가 있어요. 이게 heap이에요. 그래서 여기 슬라이드를 보면 이제 코드를 가지고 변수 하나 둘 추가하면서 어디에 저장이 되는 지를 그려놨으니까 한번씩 보시고요.
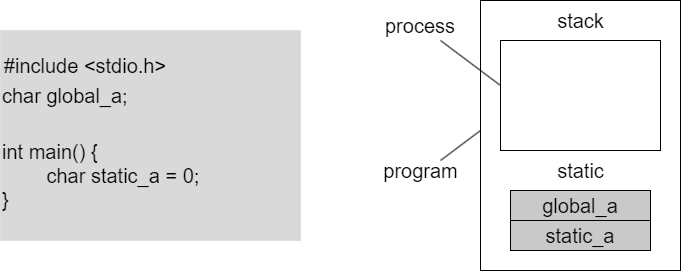
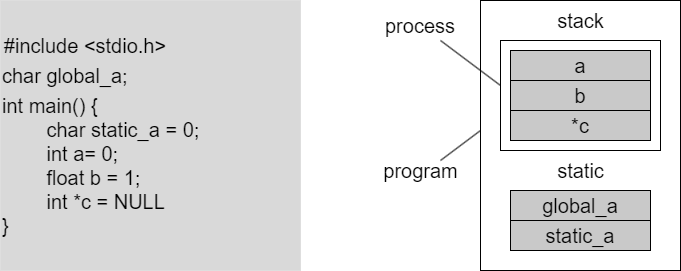
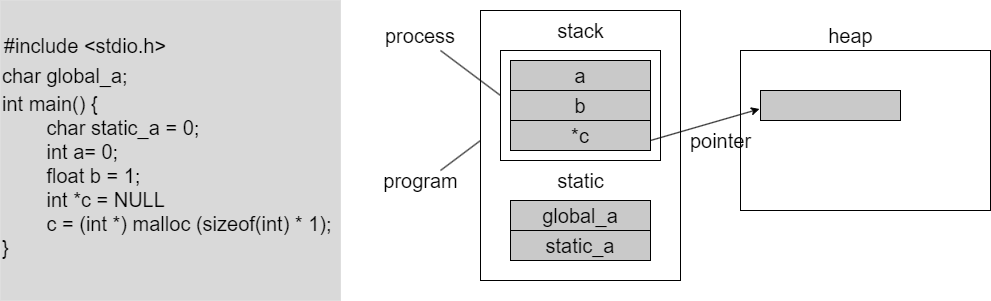
stack의 역할은 내부 함수 안에 있는 이 프로세스가 정의하고 있는 함수안에서 선언된 변수들은 stack으로 갑니다. 예를들어서 메인 함수 안에서 int a;를 했다. 이런거죠. 그리고 static은 두가지가 있을 수 있는데, 내가 이름에다가 static이나 global을 붙여 주면 static으로 갑니다. 차이는 stack은 주소가 continious하게 늘어나고요, static은 그런거 없어요 그냥 어디든 생길 수 있어요. 근데 큰 차이점은 static 변수들은 다른 프로세스들이 다 볼 수 있어요. 프로세스2가 하나 더 있으면 이 프로세스도 볼 수 있습니다. 근데 프로세스가 가지고 있는 각자의 stack은 보지 못합니다. 이게 큰 차이 입니다.
그래서 내가 어디서 선언하는 변수가 어디가서 저장되는지를 알고 잇어야 나중에 디버깅을 할 수 있습니다. 이걸 모르면 디버깅을 못해요. 간단한 수준의 소프트웨어에서는 메모리 데이터가 어디갓 박혀있는지 몰라도 기본이 되는데 굉장이 복잡한 소프트웨어들을 만들고 디버깅 할려면 변수가 어디가서 막혀 있는지를 알아야 돼요.
그래서 stack에 있는지 static에 있는지 마지막에 heap이 뭐냐면 운영체제가 관리하는 메모리라고 했죠. 이 프로세스 각 프로세스들이 요청을 하면 줍니다. 그래서 여기다가 예를들어 포인터를 하나 만들었다. p라고 해놓고 malloc을 받았어요 그러면 요청한 사이즈 만큼 저희 공용 풀에서 쭉 빼가지고 여기다 주소를 줍니다. 그 얘기는 무슨소리냐면 이건 내거가 아니기 때문에 쓰고 돌려줘야 돼요. 한 프로세스가 사용하고 있으면 저 heap에 있는 공간은 다른 프로세스가 쓰면 안돼요. 하지만 못쓰는건 아니에요. 그러니까 이게 중요한건데 다른 프로세스가 쓴다고 해도 시스템 에러도 안나고 워닝도안뜨고 아무 문제가 없어요. 그래서 C를 사용할 때나 C++을 사용할 때 메모리는 fully manual입니다. 본인이 잘 써야돼요.
포인터 포인터는 C를 써봤으면 써봤을 거에요. 포인터는 heap에서 메모리를 갖다 쓸 수 있는 수단입니다. 데이터가 아니라 주소가 들어가요. 근데 C는 fully manual이라고 했죠 저기다 데이터를 넣으라면 넣을 수는 있어요. 예를들어 int *p라고 하고 malloc 받으면 여기에 주소가 들어갈텐데, 만약 여기에 1이라고 data를 넣어요. Warning은 뜰 수 있는데 에러는 안나요.
static int ath3k_load_firmware(struct usb_device *udev,
const struct firmware *firmware)
{
u8 *send_buf;
int err, pipe, len, size, sent = 0;
int count = firmware->size;
BT_DBG("udev %p", udev);
send_buf = kmalloc(BULK_SIZE, GFP_KERNEL);
if (!send_buf) {
BT_ERR("Can't allocate memory chunk for firmware");
return -ENOMEM;
}다음 슬라이드를 보시면 example이 하나 있는데 제가 실제 코드를 찾아서 넣어놧어요. 그래서 리눅스 디바이스 드라이버중에 최신버전에 있는 블루투스 디바이스라고 코드를 가지고 왔습니다. 거기서 보면 kmalloc이라는 것을 쓰는데요 아까 얘기했듯이 kmalloc은 kernel이 쓰는 malloc이에요. 그래서 send_buf라는 변수에서 어떤 특정 사이즈를 kmalloc 받아오고요 그리고 malloc 함수를 요청해 메모리 요청을 하면 만약 받아올 때 에러가 나면 0이 리턴돼 에러 처리를 하는 거에요.
Preprocessors
여기까지가 메모리랑 포인터 내용이었고요 뒤에 preprocessor에 대해 알아봅시다. preprocessor를 넣은 이유는 이게 C의 굉장이 특이한 feature에요 다른 언어들 중에 제가 써온 언어중에 preprocessor라는걸 갖고 있는게 C하고 C++밖에 없어요. preprocessor 네임이 말해주듯이 미리미리 뭔가를 하는거에요. 미리 뭘 하냐면 실행하기전에 컴파일 하기전에 뭔가를 해요. 컴파일러는 예를들어서 어떤 부분에 preprocess를 넣으면 컴파일 하기전에 그 부분을 특정 변수나 상수로 대체합니다. 이런 컴파일 이전에 뭔가 이제 사용자 편하라고 넣은 기능이에요. 사실 이거 자체로는 시스템의 기능을 활용한 내용은 아니고 코딩하는 사람들이 편리하고자 만든 기능인데 일단 뭔지 살펴보죠.
Small code snippets that run before compilation.
- Macros
- File inclusions
- Conditional compilations
지금 세개정도 말하는데 매크로라는게 있고, 파일 인클루션, 컨디셔너 이렇게 3개가 있어요. 근데 셋중에 파일 인클루션은 당연히 쓰겠죠, 처음에 stdio.h쓰조 그게 사실 굉장히 큰일이에요. 이게 여기다가 include 해놓으면 그안에 들어있는 header파일 전체를 몇백라인을 이 한줄이랑 바꾼거에요. 그래서 preprocessing이 끝난상태에서 파일을 보면 소스 코드가 훨씬 길어져 있는걸 볼 수 있어요. 자기는 한두줄 썼는데 프리프로세싱 끝나고 나면 저 헤더들이 다 들어와가지고 소스코드가 굉장히 길어집니다. 그게 파일 인클루션이고요.
매크로는 아주 대표적인 매크로 누구나 썼을것 같은데 디파인. 이게 어쩔 때 쓰이냐면 상수인데 상수를 내가 자주 써요 근데 숫자로 써놓으면 좀 자주쓰이는데 숫자 쓰기도 좀 그렇고 내가 이 값을 코드 여기저기다 다 변해놓으면 나중에 바꾸고 싶을 때 어떡할까 다 찾아다니면서 바꿔야되죠 근데 이렇게 define해놓고 코드에다가 a를 막 적어놨어요 b 대신에 그러면 b를 바꾸고 싶을 때 여기만 바꾸면되요.
마지막으로 컨디셔널 컴파일 대표적인 예가 뭐냐 ifdef에요. 귀찮아서 쓰는것도 있고, 버그나 아니면 약간 문제 생길 여지를 없애는 용도도 있어요. 예를들어 ifdef a endif가 되어있으면 a부분을 컴파일러가 컴파일하기 전에 싹 훑어보고 여기를 넣을 지 말지 결정해요.
