Virtual Memory System
버추얼 메모리는 왜 피지컬 메모리가 있는데 한번 매핑을 해서 버추얼이라는 개념을 만들었을까. 피지컬 메모리는 기본적으로 크기의 제한이 있습니다. 당연히 제한이 있죠. 본인이 달아놓은 메모리 스페이스만큼 물리적인 제한이 있습니다. 그런데 어떤 똑똑한 사람들이 어떤 프로그램을 돌려도 이 피지컬 메모리를 전부 한번에 사용하지 않고 프로그램을 돌릴때 모든 소스코드와 모든 데이터를 한번에 다 사용하지 않는다는 것을 알게되었습니다. 순차적으로 사용을 하든지 어떤 패턴을 가지고 사용을 하든지 일부분만 좀더 많이 사용하더라 이걸 로컬리티라고 하는데요. 그런 특성을 생각해보니 그러면 우리가 뭔가 매핑을 해서 관리를 하면, 물리적인 크기의 제한이 없는 것처럼 볼수 있겠더라, 이게 버추얼 메모리의 motivation입니다. 그래서 실제로 메모리가 1테라지만, 리눅스같은 운영체제를 설치해서 사용하다 보면, 1테라보다 많이 사용할 수 있어요. 디스크를 활용해서 버추얼 메모리라는 시스템을 구현해놨기 때문에 가능한 거고요, 이게 어떻게 동작을 하는지 이제 살펴봅시다.
디스크, 메모리 cpu 세개가 있고 정상적이면 디스크에 있는걸 바로 cpu 레지스터에 바로 갖고오면 되요. 그런데 왜 이렇게 안하냐, 너무 느리죠. 그래서 필요한 데이터들을 메모리에 한번 올리고 여기서 통신을 합니다. 간단하게 생각하면 그냥 바로 디스크-레지스터 통신을 하지 왜 한번 더거쳐서 더 느리게 된거 아니냐 이렇게 생각할 수 있는데, 아까 말한대로 로컬리티라는 특성때문이에요. 데이터를 한번 올려놓으면 한번 쓰고 끝나는게 아니에요. 대부분 중요한 데이터를 메모리에 올려놓으면, 재사용을 여러번해요. 그래서 재사용을 많이 하는 경우에는 메모리 속도 정도만 감수를 하면 되겠죠. 그런데 만약에 본인 프로그램이 워스트케이스, 즉 완전 랜덤이다. 데이터를 완전히 랜덤하게 엑세스 한다. 그러면 데이터를 여기다 올려놔도 재사용을 한번도 못하겠죠. 랜덤하게 한다는 소리는 같은 데이터를 높은 확률로 안쓴다는 소립니다. 그래서 로컬리티가 없는 프로그램일수록 느려집니다. 그런 특성 때문에 프로그램을 짜는 사람들은 시스템프로그램을 짜든 애플리케이션을 짜든 로컬리티를 높이려고 노력을 해요. 데이터를 한번 갖고 왔으면 재사용을 최대한 자주 하려고 노력을 합니다. 버추얼 메모리의 특성이었구요. 이제 버추얼 메모리를 어떻게 구현했느냐를 알아보겠습니다.
Paging
- 피지컬 메모리를 고정된 블록(frame)으로 나눔
- 구조에 따라 512bytes~ 8192bytes
- 로지컬 메모리를 고정된 블록(page)로 나눔
- 현대 os는 4096-byte pages를 사용
어떻게 구현했는지 보기 전에 페이징이라는 용어가 나옵니다. 사실 메모리랑 디스크랑 동일하게 용어는 프레임이라고 부를수도 있고 페이지라고 부를수도 있고 블록이라고 부를수도 있고 책 쓰신 분마다 달라요. 회사에서 뭘 개발하시는 분인지에 따라 다르겠지만 우리는일단 용어를 페이지로 통일하겠습니다. 어떤 메모리 스페이스, 메인 메모리가 됐건 세컨더리 메모리가 됐건 페이지라는 일정 크기의 데이터로 나눠서 관리를 합니다. 이게 페이징이에요. 별거없어요 그냥 메모리 스페이스를 특정 사이즈로 나눠서 사용을 한다. 그리고 현재 아직까지는 이 사이즈가 4096이에요. 그래서 4096 구역으로 쪼개놓고 매핑을 합니다. 요사이를 매핑을 해요. 그게 페이징이에요

그림을 보시면 피지컬 메모리쪽은 프레임이라고 하고있죠. 프레임도 4096이고 페이지도 4096이에요. 그래서 가운데 매핑을 위해서 테이블을 하나 마련을 합니다. 운영체제가 그래서 테이블을 하나 갖다놓고 얘는 얘로, 얘는 애로, 그런식으로 매핑을 해놔요 이게 페이징이에요. 그러면 실제로 동작을 어떻게 하는지부터 봅시다.
page fault handling

메모리가 있습니다. 메모리가 페이지가 쭉 있어요. 그리고 피지컬 메모리가 있습니다. 근데 작아요 그 밑에 디스크도 있습니다. 디스크는 큰데 우리가 관심있는 어떤 부분이 있을거에요. 거기에 프로그램이 들어가있다고 합시다. 그래서 cpu에다가 어떤 프로그램을 돌리고 싶어 그래가지고 어떤 프로그램 코드를 실행시켰습니다. 그러면 프로그램은 디스크안에 있으니 디스크 안에 꺼내 실행을 시키려고 cpu로 가져가야죠. 그런데 아까 얘기했어요. 여기서 바로 갖고오면 로컬리티 특성을 못쓰니까 너무 느려집니다. 그래서 사실 이 로지컬 메모리는 존재하지 않아요 실제로 피지컬 메모리랑 cpu밖에 없는데 로지컬 소프트웨어를 만들어보자, 해가지고 여기에 로지컬한 page 테이블을 하나 둡니다. 이게 page table이라고 하는건데 cpu가 먼저 저 프로그램에 해당하는 page table에 가봅니다. 그러면 여기가 처음엔 비어있을 겁니다. 처음 access하는 거니까. 이 상황을 page fault라고 해요. 이때 hardware interrupt라는게 발생합니다. cpu가 데이터 없으니까 데이터좀 갖다놔줘 라고 알려줍니다. 그게 이제 page fault 핸들링이라는 거고요.

그러면 이제 앞주차에서 얘기했던 대로 브리지 통해가지고 버스 통해가지고 디스크 컨트롤러라는 애한테 알려줍니다. 주소를 알려줘요. 그러면 여기 비어있는 메모리에다가 올려놓고 원하는 데이터 여기있어, 하고 페이지 테이블에 등록을 합니다.

이 페이지 테이블은 cpu가 볼 수 있는 메모리 영역이기 때문에 cpu는 거기에 접근을 해서 실제 여기 주소에 해당하는 페이지 테이블을 쫓아가고 또 연결돼있는 실제 피지컬 메모리를 쫓아가서 가져옵니다.이 과정이 맨처음 한번 발생을 하고 그다음에 또 프로그램을 실행할 때에는 page fault가아니라 page hit이 일어납니다. page hit은 page table을 봤는데 데이터가 있는경우에요. 이경우엔 디스크로 갈 필요가 없으니까 바로 메모리에 가지고 오겠죠. 그래서 이제 재사용을 많이 할 수록 성능이 좋아지는 겁니다. 이게 기본적으로 운영체제 밑에서 돌아가고 있는 메모리 디스크로부터 데이터를 갖고 오는 방법이에요.
page table
- 모든 프로세스는 자기자신의 페이지 테이블을 가짐
- 각 프로세스가 full adress space를 가짐
- simplify 메모리할당, 공유, 링킹, 로딩

이제 페이지 테이블을 어떻게 구현했느냐. 이제 이 테크놀로지의 핵심인데 기본적으로 운영체제의 일부에요. 리눅스 같은애들이 이 테이블을 어떻게 만들었느냐, 윈도우에서 만들었느냐 등에 따라서 달라요. 기본적으로 우리는 유닉스 계열의 운영체제를 볼겁니다.
리눅스라고 이름을 붙이고 있는애들은 모두 동일하게 각 프로세스가 자기 테이블을 갖고있어요. 자기가 프로세스를 새로 만들면 프로세스 fork를 하든 아니면 새로운 프로그램을 실행을 하든 뭘하든 프로세스가 하나 생기면 자기 테이블이 생깁니다. 그래서 그림을 보시면 프로세스 1이랑 2가 logical 스페이스를 따로 가지고있어요. 이때 이 주소를 보면 0부터 가지고 있죠. 이게 무슨소리냐면 만약 cpu에서 다른 프로세스를 실행시켜서 로지컬 메모리가 또 생겼다. 그리고 페이지 테이블도 또생겼다. 그러면 얘도 0부터 시작하는 겁니다. 그래서 같은 페이지인데도 프로세스가 달라지면 다른주소에 매핑이 될 수 있습니다. 이게 핵심이에요. 이게 뒤에서 나올 장점 중에 하나 인데 일단 구조는 이렇게 돌아갑니다. 중요한건 같은 데이터 페이지가 디스크에서 메모리로 올라왔는데 다른 프로세스가 실행한다고 해서 두번 갖고 오지 않아요. 이게 페이지 테이블을 각자 갖고잇는 장점 중에 하나죠.
이런 시스템이 버추얼 메모리 시스템이에요. 이제 디스크도 들어갔고, 메모리도 들어갔고 운영체제도 지금 테이블이라는 걸 만들고 있고 cpu가 마지막으로 데이터를 가져가고 컴퓨터 시스템 통틀어서 대부분의 컴퍼넌트가 다 들어가있죠. 여기에 이제 운영체제를 구현하는 사람들이 가장 첫번째로 구현해야 되는 뼈대가 되는 시스템이에요. 지금 까지는 어떻게 동작을 했는지 알려줬고 이제는 왜 만들었는지를 얘기할 거에요.
Problems solved by virtual memory
- 메모리 공간은 모든 프로그램을 로드하기에 충분히 크지 않다.
- 자주 사용하는 hot pages들만 cache에 올려놓는다.
- 자주 사용하지 않는 cold pages들은 disk로 보낸다.
버추얼 메모리 시스템을 만들어서 세가지 문제를 해결했어요. 첫번째로 무슨 문제를 해결했냐면 옛날에는 컴퓨터가 메모리가 굉장히 작았죠. 메모리가 바이트 단위였어요. 가격도 비싸고 만들기도 힘들고. 이런데 프로그래머 입장에서 나는 하고싶은게 너무 많아 뭔가 내 프로그램이 이렇게 크고 데이터도 뭔가 계속 늘어나고 있고 뭔가 큰 걸 돌리고 싶은데 메모리가 이거밖에 안돼 그러니까 이제 다 갖고 올 수가없는 거에요. 그러면 프로그램 1,2,3,4,5가 있다고 할 때 피지컬 메모리에 5개 프로그램이 다 안들어가니까 1,2,3,4만 올려놓는다고 할때 쓰다가 5번 프로그램이 필요할 때가있을거 아니에요. 그래서 1번자리에 대신 5번을 놔서 쓰면 5,2,3,4가 돼죠. 그래서 피지컬에다가 그대로 놓아서 쓰면 쓸수가 없어요. 데이터 순서가 바뀌기 때문에 로지컬리하게 순서를 바꿔주는 거에요. 매핑을해서. 그게 그래서 이런 구조를 통해서 해결하는 첫번째 문제가 굉장히 큰 프로그램이나 데이터 같은 것들을 시퀀셜하게 그러니까 순차적으로 접근하지 않아도 실행할 수있도록, 즉 일부분만 갖다놓고 실행할 수 있도록 해줬다 입니다.

두번째 문제는 프라그멘테이션이라는 용어가 있습니다. 프라그멘테이션이 뭐냐하면 메모리가 네칸이죠. 이렇게 네칸의 메모리가 있는데 예를들어서 첫번째 하나를 썼어요. 그 이후에 다른 프로그램을 돌려서 두개를 썼습니다. 이렇게 됐는데 첫번째 프로그램이 끝났어요. 끝나서 이제 첫번째 부분은 없어요 사실 데이터는 남아있지만 쓸 수 있는 영역이에요. 이제 세번째 프로그램을 실행하고 싶은데 세번째 프로그램은 두칸이 필요해. 그러면 공간은 두칸이 있는데, 정작 쓸수가 없는거죠 서로 떨어져서. 이렇게 메모리가 갈라져있어서 쓸수 없는걸 프라그멘테이션이라고 해요. 이런 이슈가 있었는데 버추얼 메모리로 해결을 했습니다. 왜냐면 아까 말했듯이 여기다가 넣을 필요없이 그냥 연결만 하면 되는거니까. 그러면 cpu 입장에서는 두칸이 있는거죠. 그럼 그거 쓰면돼요. 이게 두번째 해결하는 문제입니다.
사실 프라그멘테이션은 두가지 종류가 있습니다. 블록 하나 사이즈가 4096이라 했는데 만약 내가 4096말고 조금만 쓰고싶다. 그럼에도 불구하고 메모리는 4096단위로 제공이됩니다. 이때 나머지 구역은 못써요. 이걸 internal 프라그멘테이션이라고 하고요. 아까 말했던 두칸이 있는데도 못쓰는게 익스터널 프라그멘테이션이라고 합니다.

세번째 문제는 안전성 문제를 해결했어요. 기본적으로 컴퓨터는 멀티 프로세스 환경이에요. 그래서 프로세스 한놈 두놈이 있고 일단 두놈만 봅시다. 근데 두번째 실행한 애가 첫번째 프로세스가 가지고 있는 페이지 하나를 지우고 싶어요. 근데 만약에 버추얼 메모리도 없이 피지컬 메모리를 직접 보고 있었으면 프로세스 1이 사용하고 있는데 프로세스2가 남의 페이지를 맘대로 write해도 이걸 막을 방법이 없어요. 그래서 안전하지가 않아요. 자기가 의도했든 의도하지 않았든 메모리를 조금만 넘어가면 남의 프로세스를 건드려버리는 문제가 있어서 어떻게 해결했냐면, 아까처럼 테이블을 가지고 매핑을 합니다. 프로세스가 각각 가지고있는 테이블은 운영체제가 관리하고 있어서 만약 한 프로세스가 남의거 페이지를 건드리고 싶어도 운영체제가 허락을 안해요. 그래서 안정성이 향상됐다. 이런 남의 프로세스를 건드릴 수있는 상황이 없어졌다 입니다.
Page Eviction
- 메모리가 없을 때 page를 하나 쫓아내야한다.
- page들은 os eviction algorithm에 따라 내보내진다.
- FIFO (First-in, First-out)
- LRU (Least Recently Used)
- MRU (Most Recently Used)
- 만약 빠진 페이지가 수정된적 없는 페이지면, 그냥 삭제한다. 반면 수정된적 있으면, disk space에 write it back 하고 삭제한다.
마지막으로 페이지 이빅션이라는게 있어요. 페이지 이빅션이라는게 뭐냐면 메모리 페이지가 4개 있는데 꽉 찼다고 합시다. 근데 우리가 다른 프로그램을 실행시키고 싶어 새로운 프로세스를 실행했어요. 그러면 한놈을 빼야되죠. 페이지 이빅션은 이 넷중에 뭘 빼야 하는지가 중요한겁니다. 이제 여러가지 알고리즘이 있는데 지금 여기는 3개를 넣어놨어요. 운영체제에 따라서 다른걸 여러가지 알고리즘들을 제공합니다. 근데 이세가지만 넣어놓은 이유도 사실 셋도아니고 이중에 하나만 써요. 일단 유명한거 3개를 다 보죠. FIFO 말그대로 머저 온거 먼저 나가라는거에요 1 2 3 4 순서대로 들어왔으면 1이 먼저 나가는거에요 그게 FIFO에요. 말이 되죠 어느정도 먼저 들어온 애가 여지껏 오래 있었으니까 이제 너 나가라. 두번째 알고리즘은 LRU라고 해서 순서상관 안하고 어떻게 사용되고 있는지를 보는거에요 예를 들어서 1,2,3,4 가있는데 1,2,3번만 주구장창 쓰고 4번을 잘 안쓴다고 합시다. 그러면 4번 얘기 나와야 돼요. 최근에 1,2,3을 많이 썼으니 앞으로도 1,2,3을 더 많이 쓰지않겠냐 이거에요. 이것도 말이되죠. 마지막으로 MRU 이건 반대경우에요 1,2,3,4 중에 1번을 제일 많이 쓴다고 할때 1번을 여지껏 많이 썼으니 1번을 빼자는겁니다. 셋다 말은되요 근데 모든 컴퓨터는 LRU를 사용합니다. 로컬리티 때문에 그래요. 그래서 이 3개중에 실험적으로, 경험적으로 LRU가 가장 성능이 좋더라. 사실 수학적으론 FIFO랑 LRU가 비슷한데 경험적으로는 LRU가 좋더라, 그래서 LRU 알고리즘이 사용됩니다. 그리고 이제 페이지가 이빅션하면 끝나는게 아니고 얘를 뺀다음에 어떡할까. 만약 내가 이 페이지를 메모리에 올리고 아무것도 안하고 읽기만 했어요. 그러면 디스크에는 얘랑 똑같은거 이미 있기 때문에 그냥 버려도 되요. 근데 만약 내가 메모리에서 이 데이터를 수정한적 있다. 그러면 얘가 이빅트 될때 수정된게 다 날아가버리죠. 디스크에는 수정된게 없으니까. 그래서 그때는 이제 다시 라이트백 해줘야돼요. 이게 굉장히 오래 걸리는 동작중에 하나이기 때문에 운영체제들이 대부분 저런거는 백그라운드에서 알아서 해줍니다. 여기까지가 버추얼 메모리 시스템이에요.
Dynamic Memory Allocation
Memory allocation in C
- Static allocation
- 전역 번수
- Static local or global 변수 (with file scope)
- Dynamic allocation (필요한 만큼만 요청)
- Automatic variables (함수 arguments)
- Manually allocated variables
c에선 메모리 할당방법이 두가지가 있습니다. 스태틱, 다이내믹이 있어요 그냥 말그대로 스태틱이면 내가 한번 얼로케이트 해놓으면 그대로 있는거에요. 사이즈도 바꿀수 없고 딱 그 정해진 사이즈를 메모리 스페이스를 그대로 사용할 수 있는게 스태틱이고요, 다이내믹은 내가 필요할 때 필요한 만큼 요청할 수 있는거에요. 얼로케이트 받고 나서 사이즈도 바꿀 수 있고. 쉽게 말하면 스태틱 얼로케이션은 그냥 변수고요, integer아니면 또 calloc. 다이내믹 얼로케이션은 malloc 말록 받아온걸을 또 realloc이라는 걸로 사이즈를 바꿀 수 있어요. 그리고 또다른 다이내믹얼로케이션이 뭐냐면 function call할 때 argument들. 예를들어 function 안에 integer 세개를 넣어준다 생각하면 이미 들고있는 integer 넘겨주니까 integer 필요 없지않냐 라고 생각할 수 있는데 필요해요. 운영체제 입장에서 보면 context가 바뀌는 거에요 그래서 내가 넘겨준 데이터를 어디다 들고 있다가 새로운 함수 context에 다 넣고 다시 넣어줘야 돼요. 그래서 메모리가 필요합니다. 그런 부분은 우리가 아무것도 안하죠 그래서 automatic variable이라고 불러요. 그래서 여러가지 얼로케이션들이 있는데 우리는 manually allocated variables를 집중해서 볼거에요.
The Dynamic Allocators
- 많은 malloc series 함수들이 있다.
- malloc()
- calloc()
- realloc()
- os 커널은 4kb 할당만 지원한다.
그래서 우리가 잘 알고있는 3가지 함수가 있습니다. 어떤 라이브러리를 사용하느냐에 따라 다른 메모리 함수들이 있을 수 있는데 3개만 알고 잇으면 충분해요. malloc은 알다시피 새로운 메모리를 요청하는 거고요 calloc은 초기화를 0으로 바꾸는거고, realloc은 사이즈 바꾸는거. 그리고 운영체제는 기본적으로 4096byte만 할당해줘요. 그래서 내가 1byte를 요청하면 1byte를 주는데 실제로는 4kb 받아서 1byte만 주는거에요 4095byte가 낭비됩니다. 그래서 인터널 프라그맨테이션이 발생하고 있다.
The System Break
- os 힙은 bss 공간 위에서 올라간다.
- os는 커다란 메모리 블록을 보는데, dynamic allocator들은 이를 관리해야 한다.
- os는 이를 위해 하나 제공하는 툴이 있는데 그것이 system break이다.
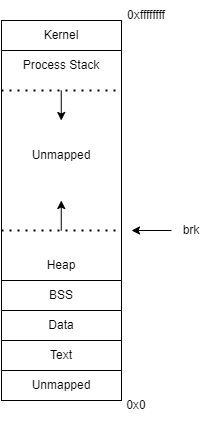
그리고 또 그림이 있는데 메모리 스페이스고 리눅스 계열 그러니까 유닉스 계열 운영체제는 커널 소스 코드를 부팅 타임의 맨 끝에다 갖다놔요. 이거는 운영체제를 구현하기를 그렇게 갖다 놓은 거니까 저 영역은 내가 못 써요. 내가 유저로서 프로그램을 써봤자 저기는 못쓰고요. 이 그림은 뭐냐면 지금 메모리가 0부터 0xfffff까지 로지컬 메모리 스페이스에요. 프로세스 하나에 각 프로세스들의 세계에요. 프로세스가 하나 생기면 이렇게 생긴 메모리 스페이스를 봅니다. 그래서 이제 가장 중요한 2개가 있는데 가운데가 비어있는 unmapped가 있죠 여기를 쓰는거에요. 실제로 텍스트는 소스코드고요, 데이터는 그 안에 들어가는 데이터들 아니면 상수같은 것들 bss는 초기화된 전역번수들. 얘네는 실제로 내가 쓸 공간이 아니라 자동으로 들어가는 공간이에요. 중요한게 스택이랑 힙인데, 실제로 프로세스들이 사용하는 공간이에요. 스택은 local variable, 메인 함숭 안에다가 내가 int, 이런식으로 선언 해놨죠. 함수 안에서 선언된 애들은 다 스택으로 가요. 힙은 말록. 내가 어디서 부르든 간에 말록을 실행시키면 힙이라는 어떤 커다란 메모리에서 어떤 공간을 똑 떼어다가 필요한 만큼 줍니다. 그게 힙이에요. 근데 여기성 이제 중요한 포인트 하나를 관리하는데 여기를 우리가 운영체제가 관리해요. 브레이크라고 하는데 여기를 관리하는 이유가 사실 스텍은 많이 안쓰여요. 대부분 힙에다 갖다 놓습니다. 그래서 힙은 브레이크라고 힙의 마지막 어드레스를 시스템이 관리합니다. 이 브레이크는 프로세스가 시스템의 메모리를 얼만큼 쓰고 있느냐늘 보여주는 지표에요. 그래서 두가지 시스템 콜이 나오는데 brk(x)와 sbrk(x)를 사용해 얘를 관리합니다. brk(x)는 brk를 x값으로 바꿔라. sbrk(x)는 상대 값이에요 x만큼 증가시켜라. brk,sbrk는 시스템 콜이에요 malloc은 gnu library의 glibc에 구현이 돼있고 실제 시스템 콜은 brk, sbrk들이에요.
Memory allocations
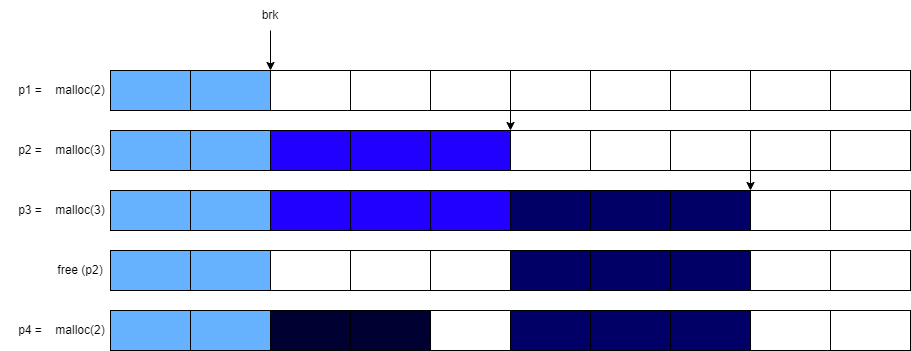
그림을 통해 brk와 malloc이 어떻게 이루어지는지 보겠습니다. 말록을 세번 요청을 합니다. 첫번째에 두개를 부르고, 두개를 해서 요청 받으면 brk가 업데이트 되고, 그다음 말록이 3개를 요청하면 brk는 또 3개가 요청이되서 뒤로가겠죠. 그다음에도 또 요청하면 brk는 뒤로가고. 근데 free를 하나 합시다. free를 두번째거를 사용해요. 그러면 두번째거는 3개를 사용했으니 3개가 비겠죠 마지막으로 malloc 두개짜리를 하나 더 요청합니다. 그러면 비게된 공간을 쓰겠죠. 그러면 brk는 어떻게 될까요 brk는 안의 비어있는 공간은 신경쓰지 안씁니다. 이게 비어있어도 바뀌지 않아요. 왜냐면 홀이 있든 없든 로지컬리하게 내가 이만큼 사용하고 있다에요.
Performance: Throughput
- n개의 malloc, free requests가 있다고 할때
- R0,R1,.....Rn-1
- Throughput = ΣRi/T
- throghput과 peak utilization을 최대화하는 것이 목적
- 하지만 이 두가지 속성은 서로 상충된다.
- 스루풋은 unit time당 완료된 요청들의 수
- ex) 5000 malloc, 5000 ree in 10 seconds
->throughput = 1000 operations / second
- ex) 5000 malloc, 5000 ree in 10 seconds
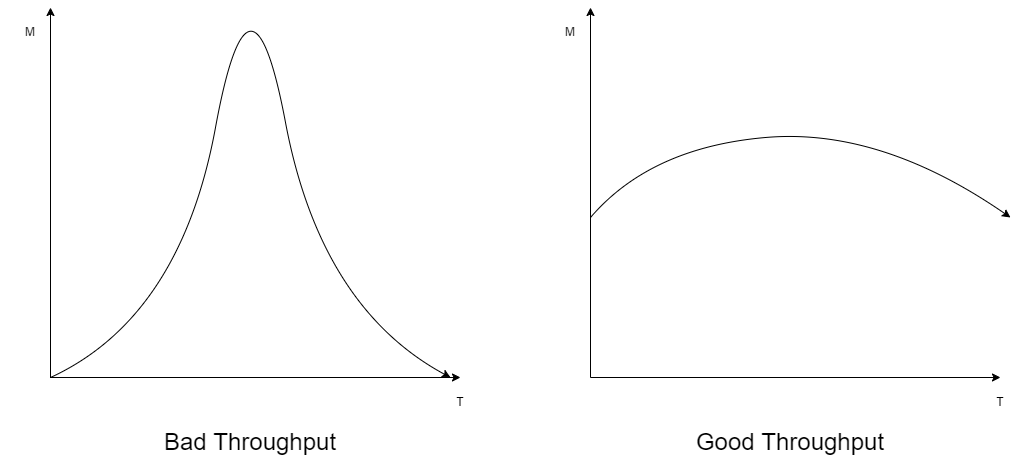
이제 메모리 얼로케이션을 했을때 성능이 어떻게 나올까를 보겠습니다. 성능을 두가지 방법을 사용해서 얘기하는데 하나가 스루풋이라는 거고요, 하나가 peak 퍼포먼스에요. 일단 throughput을 먼저 보겠습니다. n개의 malloc또는 free 요청이 있다고 합시다. 그래서 우리가 가지고 있는 프로그램이 만약에 n개의 이런 요청을 가지고 있다. 그래서 걔네가 이제 순서대로 실행될거다 라고 문제를 정의를 합니다. 그래서 스루풋은 뭐냐면 얘네의 사이즈를 다 더해요. 다 더하고 그걸 시간으로 나눈게 스루풋이에요. 스루풋이 좋아야 된다는 것은 무슨 얘기냐면 동시에 서비스 되는 애가 많아야 된다에요. 그래서 이게 그래프를 하나 그려보면 , 왼쪽보다 오른쪽이 더 좋은 스루풋을 보인다는 의미입니다.
왜냐면 스루풋이 좋다라는 건 내가 언제 어떤 리퀘스트를 주더라도 평균적으로 좋은 성능을 기대할 수 있다 이게 스루풋이 좋은거에요. 예를들어 온라인 게임 서버를 봅시다. 온라인 게임 서버에서 스루풋이 안좋으면 어떻겠어요. 특정시간에 들어가면 안되고, 특정시간에 들어가면 엄청 빠릅니다. 이게 좋은 성능을 보이는 거라고 볼 수 있을까요. 아니죠 언제들어가도 적당한 성능을 보이는게 좋은 거라고 볼 수 있죠. 그얘기입니다.
Performance: Peak Utilization
- Aggregated payload P = 실제로 얼만큼의 메모리를 쓰고 있는가
- Current heap size H = 현재 힙 사이즈
- 절대 줄어들지 않음
- malloc이 리턴 될때마다 계속 늘어남
- Peak Utilization U = (최대 P)/H
Peak은 두가지를 정의할거에요 하나는 페이로드 하나는 커렌트 메모리 스페이스. 이 두가지를 정의할 건데 P는 request를 받고있을 때 특정 시간을 딱 찍었을 때 그 시간 까지의 리퀘스트들이 있겠죠 이때 free한 부분이 아니라 실제 내가 쓰고있는 메모리 공간의 sum을 P라고 합니다. 두번째 힙은 실제로 힙사이즈. 그래서 P를 H로 나누면 되는데 이게 max가 붙습니다. 그래서 만약 특정 타임 k를 딱 찍었을 때 k 시간 이전에서 P값중 최댓값을 찾고 이것을 Hk로 나눈것을 말하는 겁니다. 이게 어떤 의미냐면 최고 성능 대비 내가 지금 얼만큼 나와있냐에요. 이게 크면 클수록 현재보다 피크때가 성능이 많이 높다는 것을 의미해요. 이게 언제 좋아야되냐면 얘를들어 수강신청 시스템을 쓸때 수강 신청 시스템은 평소에는 안쓰거든요. 그런데 수강신청 하는 두주 동안만 몰리죠. 그래서 제일 빠를때 이게 빠르면 되요. 그래서 이 두가지가 메모리의 성능을 나타낼 수 있는 지표였습니다.
