기존 무중단 배포 기능만 있던 cloudserver-web에 오토스케일링 기능을 추가할것이다.
여기서 오토스케일링이란?
오토스케일링은 Kubernetes에서 파드의 수를 자동으로 조정하여 애플리케이션의 성능과 가용성을 보장하는 기능입니다. Kubernetes는 두가지 주요 오토스케일링 기능을 제공합니다.
1) Horizontal Pod Autoscaler(HPA): CPU 사용량, 메모리 사용량 또는 사용자 정의 메트릭스를 기준으로 파드의 수를 자동으로 조정
2) Vertical Pod Autoscaler(VPA): 각 파드의 리소스 요청 및 제한을 조정하여 파드의 성능을 최적화
사용이유
- 자원최적화: 클러스터의 리소를 효율적으로 사용하여 필요에 따라 리소스를 할당하거나 해제할수 있음
- 비용 절감: 수요에 맞게 리소스를 조정하여 불필요한 비용을 줄일 수 있음
- 애플리케이션 가용성: 사용자 수요에 따라 자동으로 확장함으로써 애플리케이션의 가용성을 유지
- 성능 향상: 부하가 증가할 떄 필요한 파드 수를 자동으로 늘려 성능 저하를 방지
장점
- 자동화: 수동으로 파드 수를 조정할 필요 없이 자동으로 관리 되므로 운영 부담이 줄어듬
- 탄력성: 부하의 변동에 유연하게 대응할 수 있어 사용자 경험을 개선
- 효율성: 클러스터의 리소르르 최적화하여 운영 비용을 절감
- 스케일 아웃/인: 수요에 따라 파드를 동적으로 추가하거나 제거 할수 있음
사용방법
사용방법은 매우 간단하다. HAP 설정 파일은 만들어주고 배포해주면 된다.
sudo nano HPA.yml #HPA.yml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: cloudserver-web-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: cloudserver-web
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 30 # CPU 사용률이 50% 이상이면 스케일링1) apiVersion: autoscaling/v2는 HPA를 정의하는 API 버전입니다. v2는 더많은 기능을 지원하며, 사용자 정의 메트릭스를 포함한 여러 가지 메트릭 기반 스케일링을 지원합니다.
2) kind: HorizontalPodAutoscaler: HPA 리소스를 정의
3) metadata: HPA의 이름을 지정
4) scaleTargeRef: 오토스케일링할 대상을 지정, 여기서는 cloudserver-web 이라는 배포를 대상으로 함
5) minReplicas,maxReplicas: 최소 및 최대 파드수를 정의, 최소 3개 최대 10개의 파드를 설정
6) metrics: 오토스케일링 기준이 되는 메트릭을 정의. cpu 사용량을 기준으로 하며, 평균 사용량이 30%에 도달하면 파드 수를 조정.
이제 작성완료했으면 저장하고 적용해주고
kubectl apply -f HPA.yaml확인해보면 잘되고 있는것을 확인할수 있다.
kubectl get hpa
마무리했으면 이제 잘 실행이 되나 확인 해보기 위해서 성능테스트를 진행해서 일부로 cpu 사용량을 높여봐서 오토스케일링 기능이 잘되나 확인 해볼수 있다.
나는 Locust 를 선택했다. Locust는 python 으로 작성된 오픈 소스 성능 테스트 도구로, 사용자 시나리오를 정의하고 다양한 부하테스트를 수행하는데 사용된다.
설치
pip install locustsudo nano locust-script.py#locust-script.py
from locust import HttpUser, task, between
class WebsiteUser(HttpUser):
wait_time = between(1, 5)
host = "http://자신의 웹 페이지 접속 url or ip" # 프로토콜을 포함한 올바른 URL
@task(1)
def index(self):
self.client.get("/")
@task(2)
def login(self):
# 1. 로그인 URL에 이메일을 포함하여 GET 요청을 보냄
login_url = "/cloudapp/login/?email=asd000930@naver.com"
response = self.client.get(login_url)
# 2. 로그인 페이지로 접속한 후, 비밀번호를 입력하여 로그인
if response and response.status_code == 200:
login_data = {
"email": "asd000930@naver.com", # 이메일 (이미 URL에 포함되어 있으므로 굳이 필요는 없음)
"password": "password123", # 가상의 비밀번호
}
login_response = self.client.post("/cloudapp/login/", data=login_data)
# 3. 로그인 요청의 성공 여부 확인
if login_response and login_response.status_code == 200:
print("Login successful!")
else:
print(f"Login request failed with status code: {login_response.status_code if login_response else 'No Response'}")
else:
print(f"Failed to access login page. Status code: {response.status_code if response else 'No Response'}")나는 사이트 접속 뿐만아니라 사이트에서 접속해서 가상의 사용자가 로그인 해보는 시나리오까지 작성해봤다. 내용은 솔직하게 맞는지 몰르겠는데 되긴해서 사용중에 있다.
이제 저장하고 실행하면 된다.
locust -f locust-script.py
이제 웹 인터페이스에 접근 할수 있다.
http://localhost:8089
최대 사용자 수와 증가될 사용자수를 입력해주면 된다.
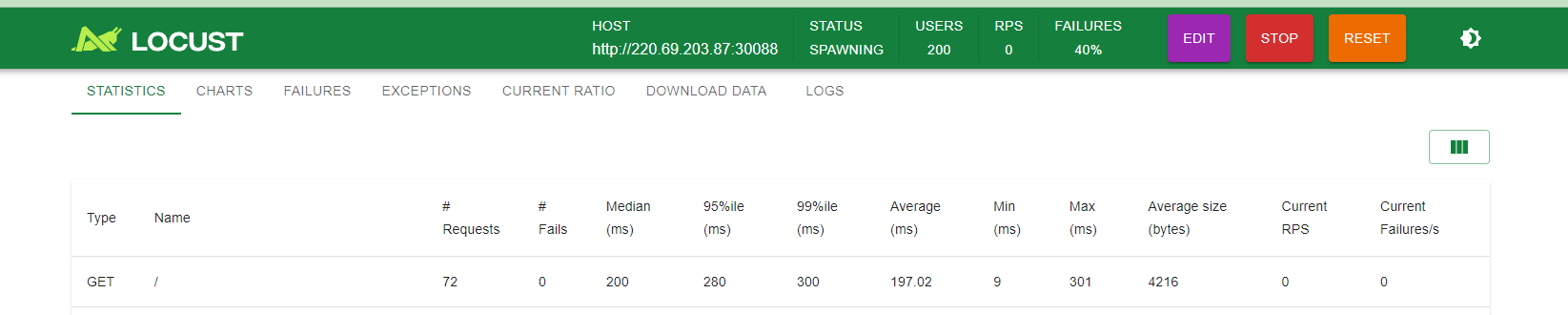
계속 cpu 사용량이 증가 하게 되는걸 확인할수 있다.
나는 따로 모니터링을 해놔서 그라파나로 확인할수 있다
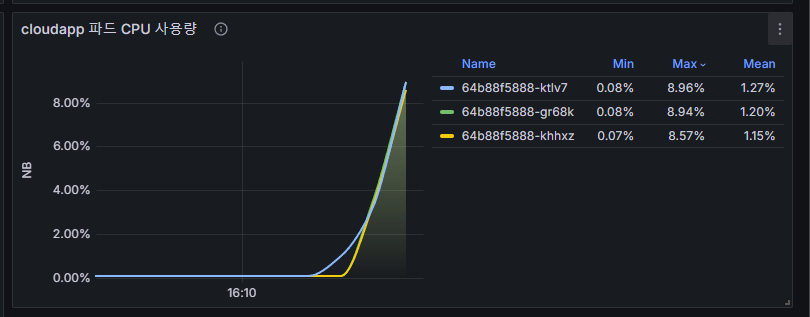
계속 증가하다 보면 임계값을 넘어서게 되면 파드가 증가되는것을 확인할수 있다.