두 테이블이 있다.
첫번째는 동별 생활인구를 날짜, 구, 동과 함께 집계한 표이다.
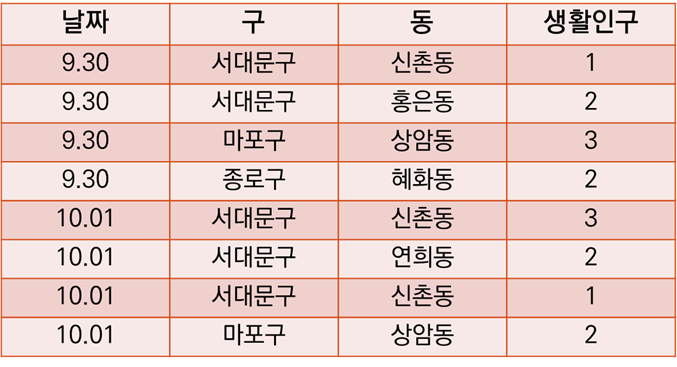
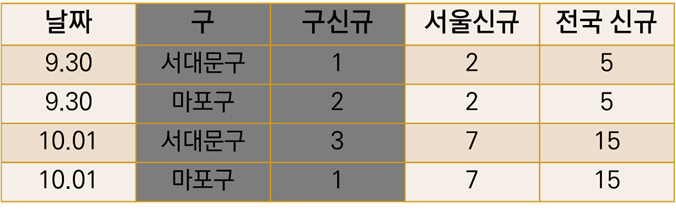
두번째는 구, 서울, 전국의 신규 코로나 확진자수를 날짜, 구와 함께 집계한 표이다.
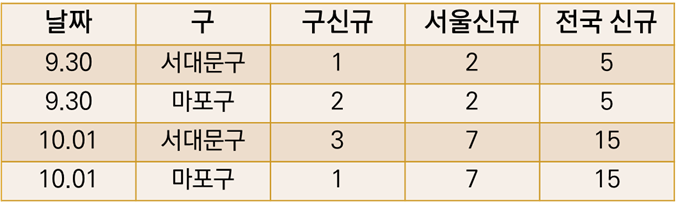
데이터프레임의 이름을 living과 corona로 지정해보자.
두 표를 합치려면 어떤 코드를 써야할까?
이런 코드나
living.merge(corona, how="left")이런 코드가 생각난다.
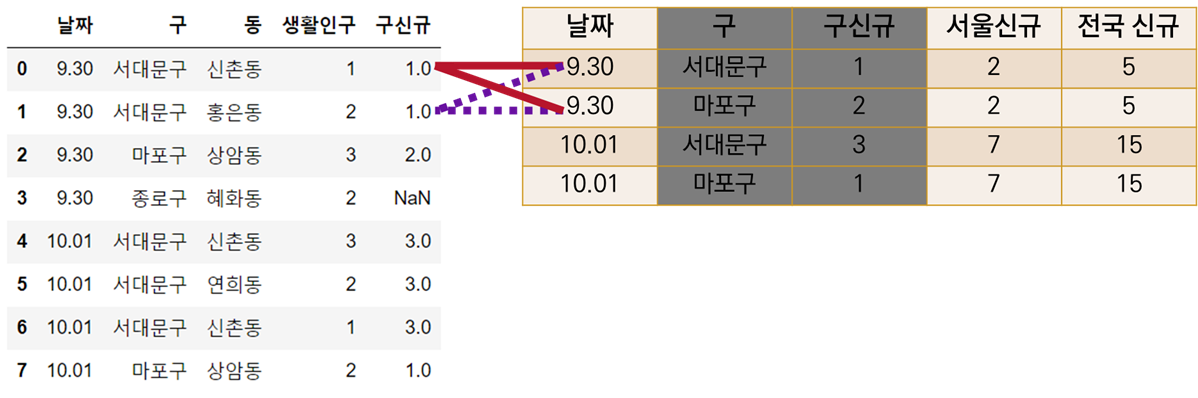
living.merge(corona, on=["날짜", "구"], how='left')날짜와 구 정보가 두 테이블에 공통적으로 존재하니, 그 값을 기준으로 붙이면 되겠다고 생각했다. 그런데 이 코드에는 문제가 있다.
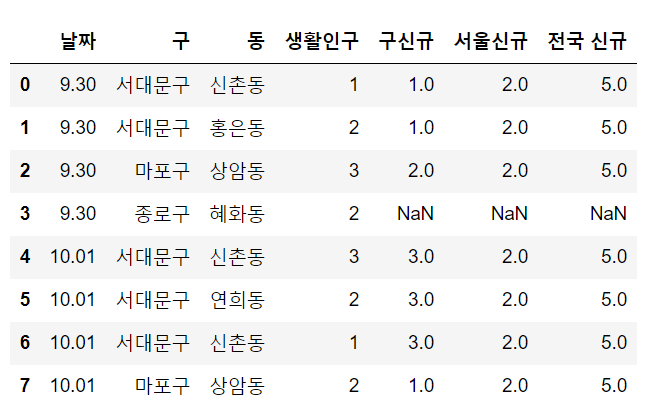
실행한 결과를 보면, 서울 신규와 전국 신규 열에 NaN 값이 존재한다. 그러나 9.30일에는 분명 서울, 전국 신규 확진자가 있었다. 그렇다면 왜 NaN값이 자리잡고 있을까?
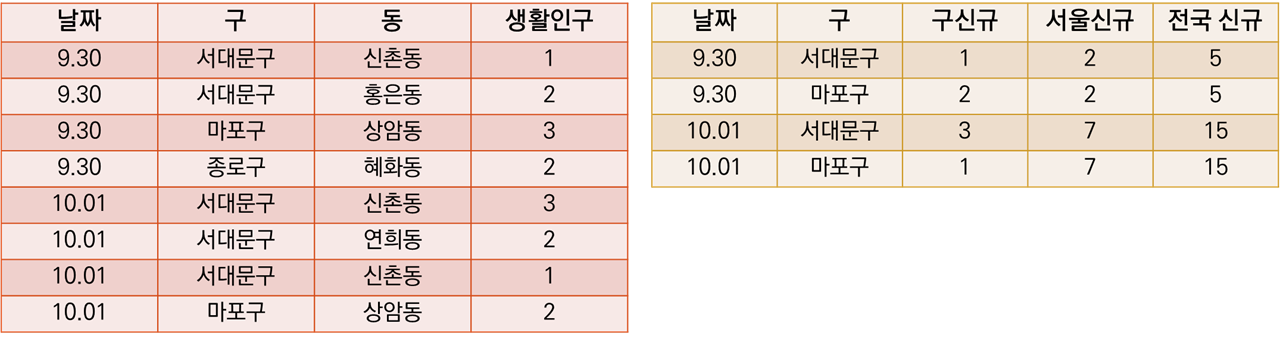
corona 표는 해당 날짜에 구 안에서 확진자가 있었던 경우에만 구를 포함한다.
9.30일엔 종로구에 확진자가 없었고, 그래서 corona 표에는 9.30 종로구의 정보가 없다.
living 표에 left join 할 종로구 구 신규 확진자수 정보가 없고, 이에 따라, merge 과정에서 서울, 전국 신규 확진자 수 정보 또한 없는 것처럼 나오게 된다(!)
🌝 어떻게 해결할 수 있을까?
가장 먼저 생각난건 두번 나눠서 merge하기였다.
구 정보가 필요한 부분은 구 신규 확진자수 뿐이고, 나머지 서울, 전국 신규 확진자수의 경우는 날짜만 동일하면 된다.
그렇다면 merge할 기준 값으로 [구, 날짜] 모두 필요한 경우와 [날짜]만 필요한 경우로 나눌 수 있다.
1) 구 신규 확진자 수 붙이기 [구, 날짜]
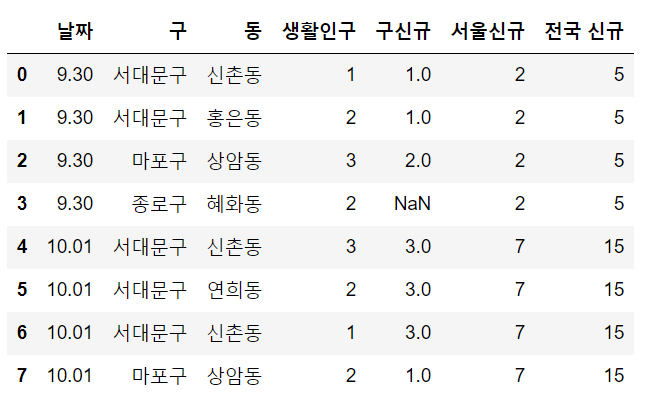
until_gu = living.merge(corona[["날짜", "구", "구신규"]], how='left')이때는 corona 표에서 사용할 정보가 구 위의 셋 뿐이기 때문에 merge할 대상을 위와 같이 한정해주었다.
2) 서울, 전국 신규 확진자 수 붙이기 [날짜]
all = until_gu.merge(corona[["날짜", "서울신규", "전국 신규"]], how='left')결과를 보면 잘 돌아갔다. 혜화동이 위치한 종로구 구 신규 확진자에 대해서만 NaN 값이 있고, 서울, 전국 신규 열에는 숫자가 잘 들어가있다.
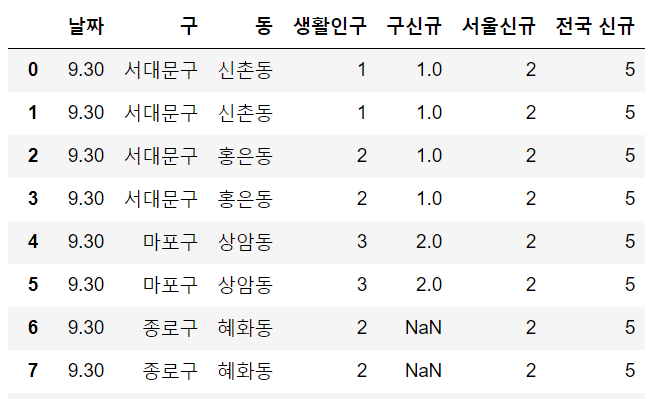
그럼 이제 행복하게 발 뻗고 잘 수 있을까?
🌝 아니다.
실제로 나는 위 방식으로 여러 데이터프레임을 사용해서 merge를 줄줄이 하다가 500MB로 시작한 데이터가 17GB로 불어나는 기적을 봤다.
실수를 방지할 수 있는 기본적인 습관은 merge 전/후 데이터의 row 수를 보는 것이다.
사실 위의 예시는 데이터가 작아서 눈으로도 금방 살펴보고 실수를 찾을 수 있다. 그렇지만 몇천, 몇만개의 행을 다루다보면 그게 쉽지 않다.
큰 데이터의 경우 head()나 sample()로 결과를 확인하는 경우가 많은데, 그러면 틀린 것을 바로 포착하는 것은 거의 불가능하다.
그렇기 때문에 결과물의 행 수를 확인하는 과정이 필요하다.
우리가 left join의 틀로 삼았던 living의 행 수는 8개이다.

최종 결과물(로 착각...) all의 행 수는 16개이다.
🌝 그렇다면 왜, 우리의 결과물은 두배로 불어났을까?
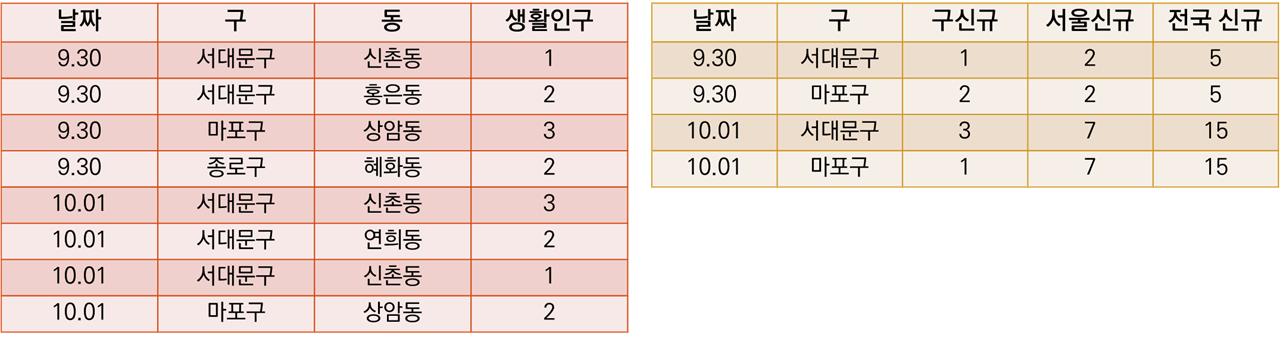
데이터를 다시 보자.
코드도 다시 보자.
until_gu = living.merge(corona[["날짜", "구", "구신규"]], how='left')
all = until_gu.merge(corona[["날짜", "서울신규", "전국 신규"]], how='left')첫 merge에서 [날짜, 구, 구신규] 정보만 활용해서 living에 붙인 건 문제가 없다.
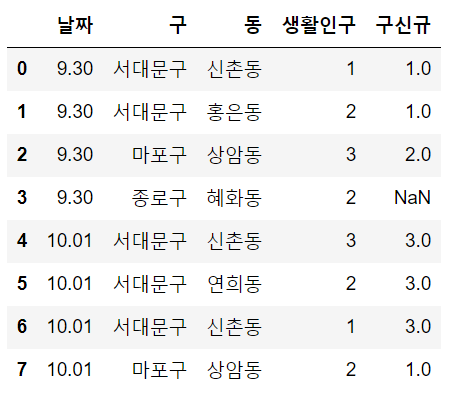
그러나 두번째 merge 과정을 잘 생각해보자.
[날짜, 서울신규, 전국신규] 정보를 활용했다. 그렇다면 아래와 같은 데이터프레임을 merge하는 것이다.
corona표에서 구 정보를 빼면, 남는 건 날짜별 서울, 전국 신규 확진자 수이다. 그런데 중복으로.
all = until_gu.merge(corona[["날짜", "서울신규", "전국 신규"]], how='left'두번째 merge는 until_gu의 한 행에 대해 corona의 서울, 전국 신규 확진자수를 중복해서 merge하는 것이 된다.
🌝 이를 어떻게 해결할 수 있을까?
drop_duplicates 함수를 사용하면 된다.
우리가 사용하려는 [날짜, 서울 신규, 전국 신규] 데이터 프레임에 중복값을 제거하는 함수를 적용하면 된다.
corona[["날짜", "서울신규", "전국 신규"]].drop_duplicates()
# 여담이지만 중복값 제거 후 결과의 index가 마음에 들지 않는다면
# ~duplicates()뒤에 .reset_index(drop=True)를 붙여주면 깔끔하다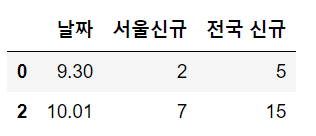
이 데이터프레임을 merge 해주면 결과가 잘 나온다.
all_correct = until_gu.merge(corona[["날짜", "서울신규", "전국 신규"]].drop_duplicates(), how='left')
# 아래와 같이 나눠서 적으면 가독성이 좋다
removed_dup = corona[["날짜", "서울신규", "전국 신규"]].drop_duplicates()
all_correct = until_gu.merge(removed_dup, how='left')
<이번주의 교훈>
🤦 주피터 노트북의 모래시계가 지나치게 오래 움직인다면,
🤦 간단한 데이터 처리도 시간이 오래 걸린다면,
🤦 데이터를 저장하고 봤더니 눈에 띄게 크다면,
merge를 의심해보자
데이터를 잘 파악하자
결과를 바로 확인하자
