
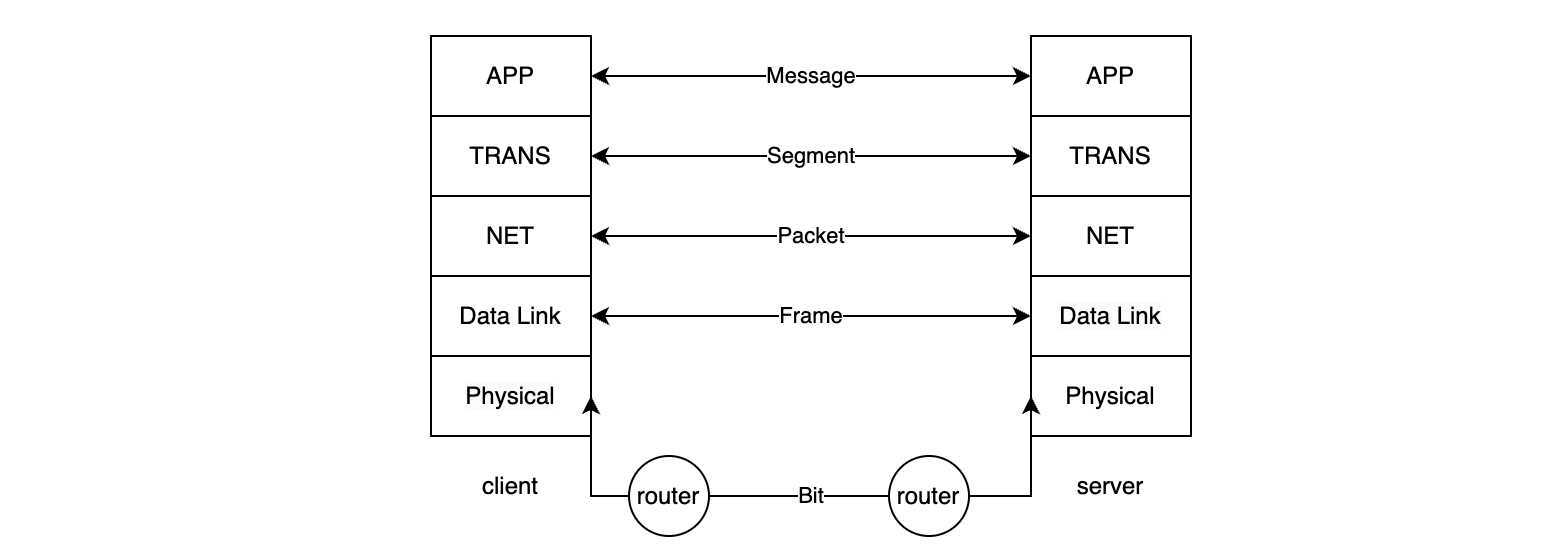
이전 시간에 배운 Application 계층의 전송 단위는 message라고 부릅니다. 마찬가지로 각 단계별로 전송 단위가 정해져 있는데 Transport 계층의 전송 단위는 segment입니다. Application 계층에서 넘어온 message는 segment(header + data)의 data 영역에 저장되어 집니다.
이번 시간에 배울 Transport 계층의 목적은 내 컴퓨터의 TCP 또는 UDP segment를 상대방 컴퓨터에 전달하는 것에 목적이 있습니다.
1. Multiplexing/Demultiplexing
Transport에서 사용하는 프로토콜은 TCP와 UDP가 있다고 했습니다. 어떤 프로토콜이든 상관 없이 있어야 할 기능인 multiplexing과 demultiplexing의 기능을 살펴보겠습니다.
1.1. Multiplexing
멀티플렉싱은 하나의 통신 채널을 통해 둘 이상의 데이터를 전송하는데 사용되는 기술입니다. 서버는 클라이언트에게 데이터를 송신하기 위해 클라이언트별로(다수의 사용자) 자식 프로세스를 생성하여 통신하는 방식을 사용할 수 있습니다. 이 기술이 멀티 프로세스방식으로 클라이언트와 서버간의 송수신 데이터의 용량이 큰 경우 사용하게 됩니다. 하지만 일반적으로 웹서버는 멀티 플렉싱 방식을 사용하게 되는데 하나의 프로세스가 여러 클라이언트의 요청을 하나의 통신로를 이용하게끔 합니다. 이 방식이 가능한 이유는 Transport 계층의 segment의 format은 헤더에 송신지와 수신지의 포트를 명시하기 때문에 가능합니다.
1.2. Demultiplexing
반대로 Transport 계층에서 Application 계층으로 데이터가 전달 될 때 올바른 소켓으로 전달하는 기술입니다. 이또한 헤더의 정보를 통해 수행됩니다.
Connectionless demux(UDP의 Demultiplexing)
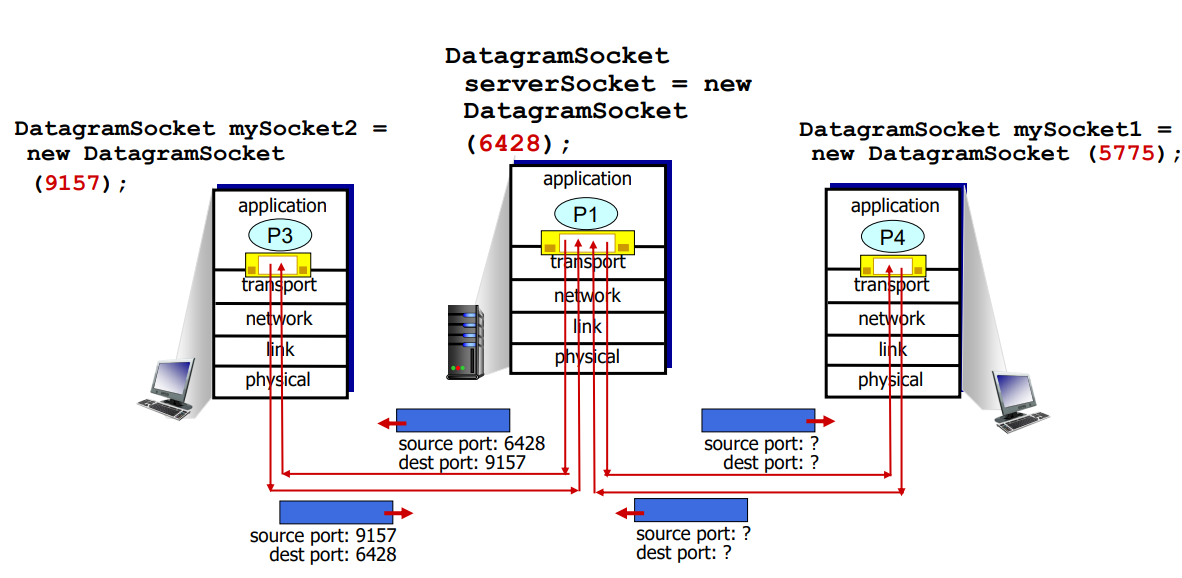
UDP는 들어오는 패킷 헤더의 source ip/port가 달라도 destination ip/port가 같다면 같은 소켓으로 전달됩니다.
Connection-oriented demux(TCP의 Demultiplexing)
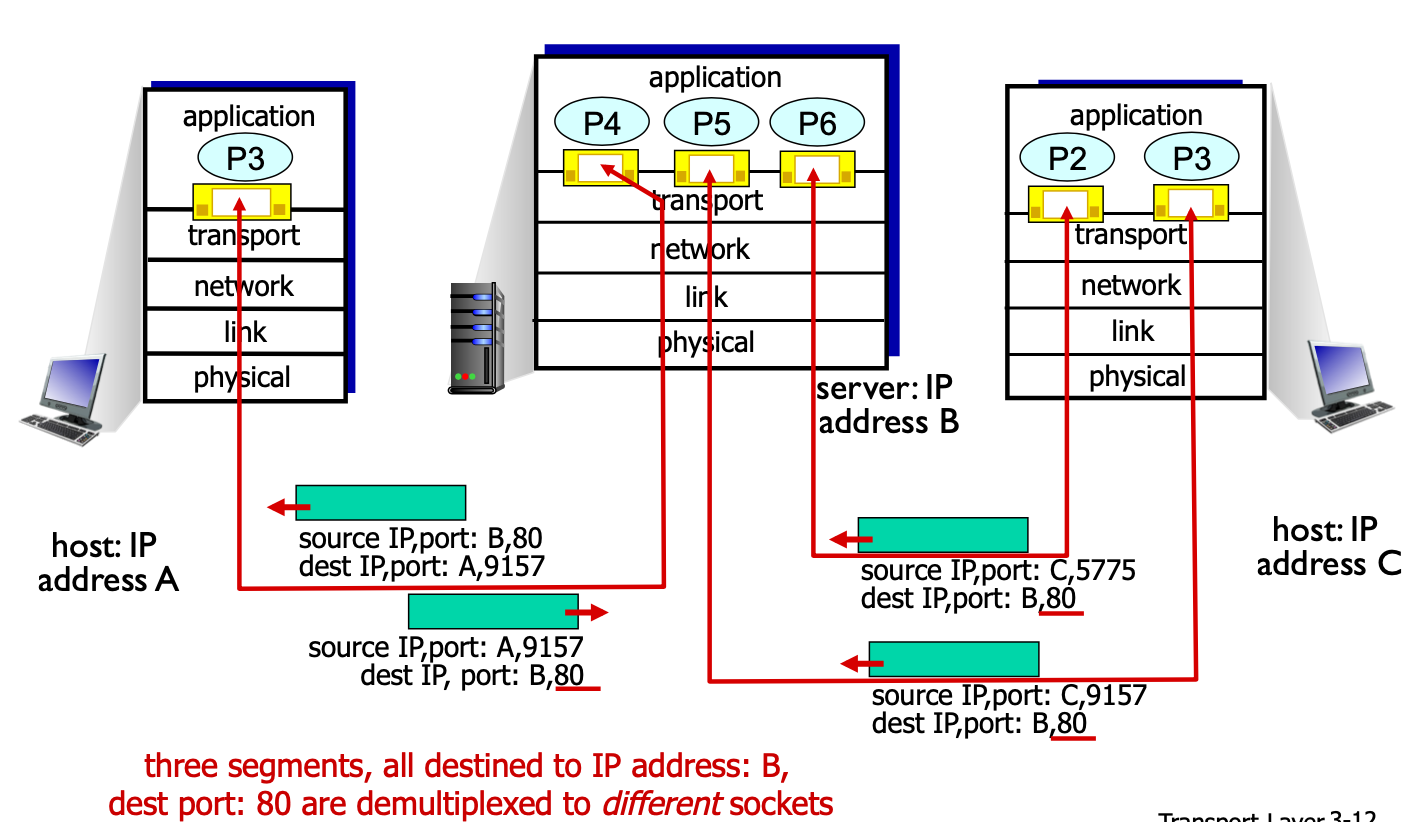
TCP는 source ip, source port, destination ip, destination port 4 가지 모두 고려하여 하나라도 다르면 다른 소켓을 가지게끔 하는 방식입니다.
2. Transport Header
각 계층 별로 담기는 헤더의 정보들을 파악해야 네트워크 통신이 어떻게 이루어지는지 파악할 수 있습니다. 특히 TCP, UDP, IP(네트워크 계층)에서 담기는 헤더 정보를 파악하는게 중요합니다.
2.1. UDP Header
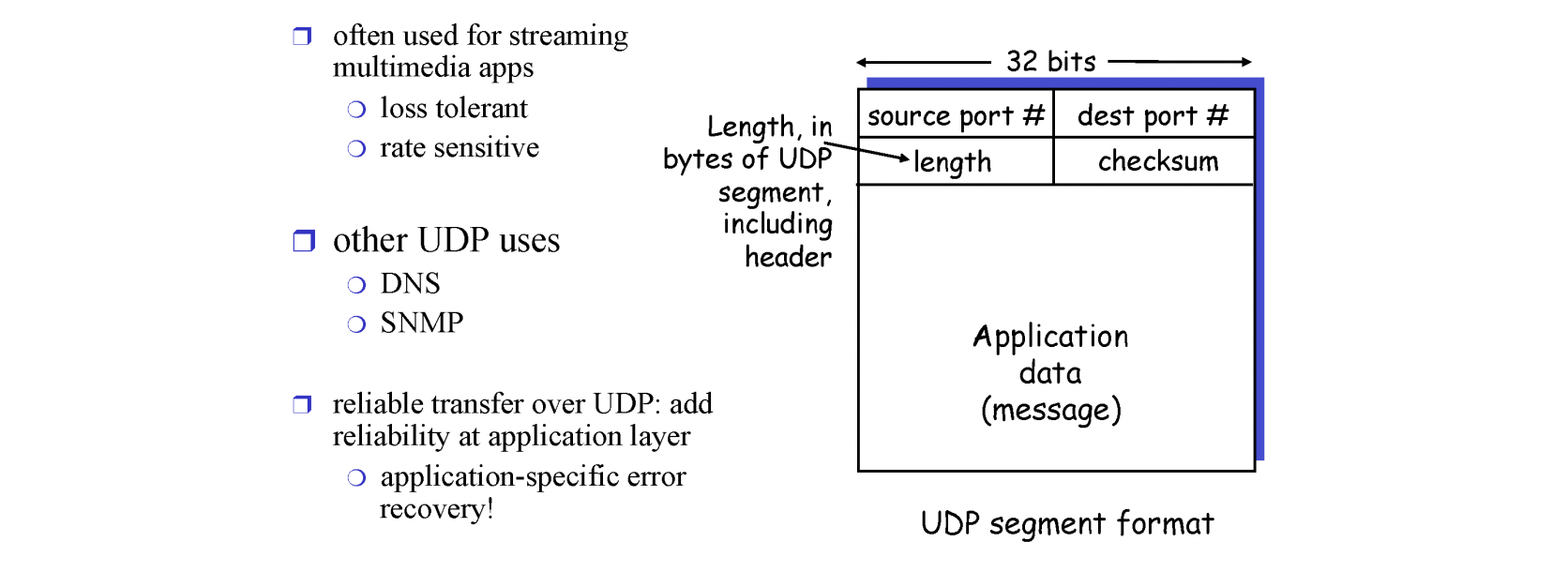
UDP의 헤더의 길이는 총 8 bytes(64bits) 입니다.
-
source port(16bits) : 송신지의 포트번호. 16비트로 이루어져 있기 때문에 한 컴퓨터는 이론상 65536개의 포트를 사용할 수 있다.
-
destination port(16bits) : 도착지의 포트번호
-
length(16bits) : 헤더와 데이터를 포함한 UDP 데이터그램의 전체 길이
-
checksum(16bits) : 헤더와 데이터를 포함한 데이터그램에 대한 오류 검사를 위한 필드
UDP의 기본적인 기능은 멀티플렉싱과 에러체킹입니다.
2.2. TCP Header

TCP의 헤더의 길이는 20 Bytes - 60 Bytes입니다.
-
source port(16bits) : 송신지의 포트번호
-
destination port(16bits) : 도착지의 포트번호
-
sequence number(32bits) : 바이트 단위로 순서화되는 번호 (신뢰성, 흐름제어 담당)
-
acknowledgement number(32bits) : 수신하길 기대하는 다음 바이트 번호 (송신자에게 받은 데이터 바이트의 + 1)
-
offset(4bits) : 헤더 길이 필드
-
reserved(6bits) : 예약된 필드
-
(receive)window size(16bits) : 자신의 수신 버퍼 여유 용량 크기를 통보하여 얼만큼의 데이터를 받을 수 있는지 상대방에게 알려주어 흐름제어를 하는 필드
-
TCP 제어 플래그
-
URG (Urgent) : 긴급 비트, 지금 보내는 데이터가 우선순위가 높음
-
ACK (Ack) : 승인 비트, 물어본거에 대한 응답을 해줄 때 사용
-
PSH (Push) : 밀어넣기 비트, TCP 버퍼가 일정한 크기만큼 쌓여야 하는데 이거와 상관없이 데이터를 계속 밀어 넣을때 사용
-
RST (Reset) : 초기화 비트, 상대방과 연결이 되어있는 상태에서 문제가 발생하여 연결 상태 리셋
-
SYN (Sync) : 동기화 비트, 상대방과 연결을 시작할 때 사용되는 플래그
-
FIN (Finish) : 종료 비트
-
-
Urgent pointer(16bits) : 어디서부터 긴급한 데이터인지 알려주는 포인터 (URG 플래그와 세트)
3. RDTP(Reliable Data Transfer Protocol)
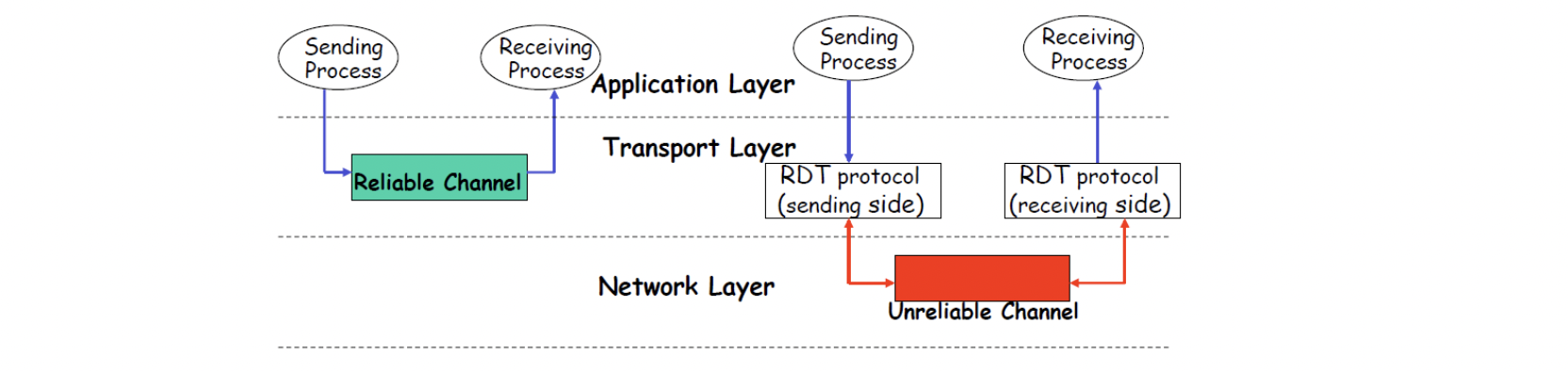
Reliable은 Application 계층부터 전달된 데이터가 어떠한 유실 없이 수신지에 도착하는 특성입니다. 하지만 실제로 네트워크를 보게 된다면 Transport는 하위 계층으로 segment를 전달하여 데이터를 전달하게 되는 방식입니다. 따라서 하위 계층에서 충분히 데이터 유실(라우터의 가득찬 queue)이 일어날 수 있습니다.
Transport 계층에서는 하위 계층에서 데이터 유실이 일어나더라도 그것을 처리할 만한 방법을 적용해 reliable 한 방식을 디자인 하는게 rdt(reliable data transfer)에 대한 내용입니다.
하위 계층에서 일어날 수 있는 문제는 크게 error와 loss입니다. 이 문제들을 해결하기 위한 rdt를 디자인 해보겠습니다.
3.1. 하위 계층에서 error만 발생할 수 있다고 가정
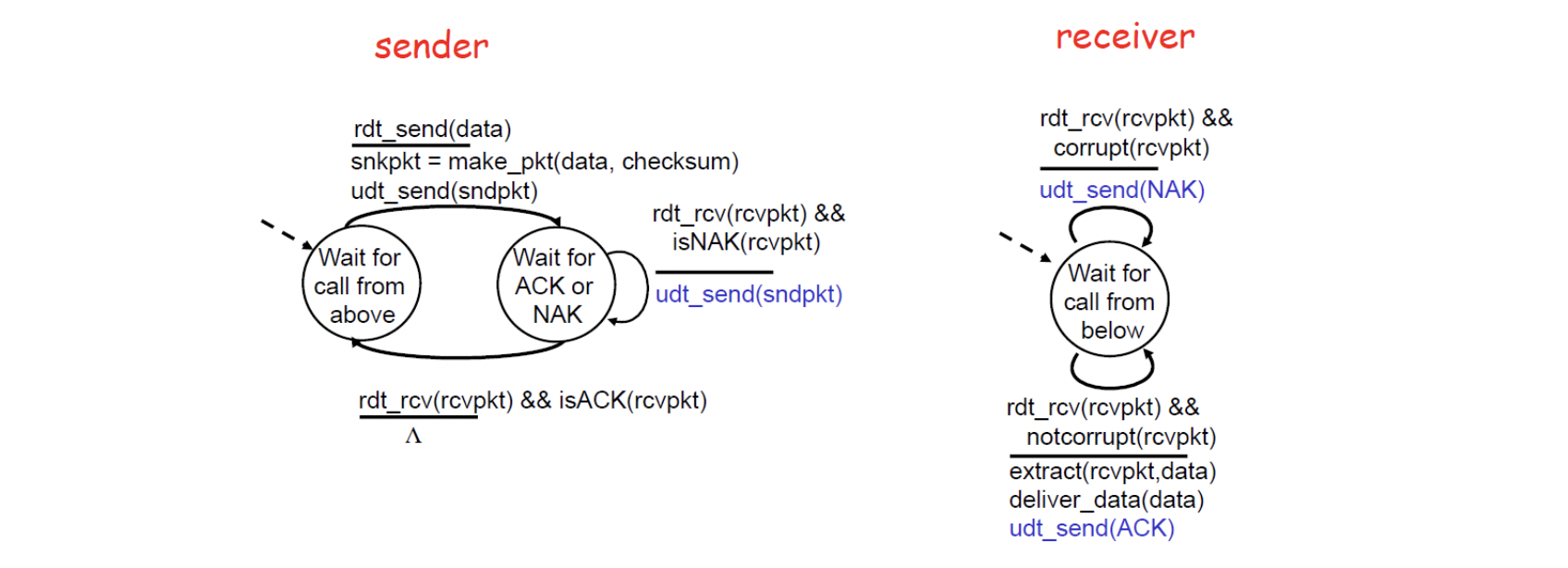
-
Error detection : Add checksun bits
-
Feedback
-
ACK : 올바른 데이터를 받았다고 응답해주는 bit
-
NAK(Negative ACK) : 올바르지 않은 데이터를 받았을 때 사용하는 bit
-
-
Retransmission : NAK을 판단하여 재전송
예를 들어, 우리가 다른 사람과 전화통화를 할 때 우리의 귀(receiver)가 상대방의 말에 대해 error detection을 합니다. 보통 상대방의 말(sender)을 이해하고 있다는 뜻으로 "응. 어."와 같은 대답(ACK, 피드백)을 하게 되고 상대방의 목소리가 잘 안들렸다거나 무슨 말인지 이해를 못했다면 "응?. 뭐라고?"와 같은 대답(NAK, 피드백)을 주게 됩니다. 그리고 상대방은 했던 이야기를 다시(retransmission) 해줍니다.
마찬가지로 rdt를 송신하는 쪽은 수신하는 쪽의 메세지 보고 checksum으로 error를 판단해 ACK 또는 NAK을 송신하는 쪽으로 보내어 재송신을 해야하는지 구별하게 됩니다.
하지만 receiver가 sender로 데이터를 보내는 와중에 error가 발생할 수 있습니다. sender 입장에서는 현재 상태가 ACK인지 NAK인지 판단할 수가 없기 때문에 재전송을 수행하게 됩니다. 실제로 receiver는 제대로 데이터를 전송받아 ACK를 피드백한 상황이라면 중복 데이터가 생기는 문제가 발생합니다. 그렇기 때문에 rdt는 데이터에 일련의 sequence number를 부여하고 데이터 전송시 해당 데이터 번호를 같이 보내게 됩니다. receiver 입장에서 지금 가지고 있는 sequence number 데이터가 전달되어 왔다면 해당 데이터는 단순히 버리는 절차를 통해 중복 데이터가 생기는 것을 방지합니다.
지금까지 내용을 정리해보면 rdt의 header에는 checksum, ACK, NAK, sequence number가 필요합니다. header의 비트를 줄이기 위해 NAK 없애고 ACK와 sequence number를 같이 사용하여 NAK 역할을 하게 만든게 다음 버전의 rdt입니다. 예를 들어, 송신자는 1번 데이터를 보냈고 피드백을 기다리고 있는데 수신자로 부터 [ACK 0]이 왔다면 보낸 데이터가 제대로 전달되지 않았다고 판단하여 재전송을 수행하게 됩니다.
3.2. 하위 계층에서 error와 loss 둘다 발생할 수 있는 경우

데이터가 loss가 되는 상황은 sender가 보낸 데이터가 receiver에게 가지 않던지 receiver가 보낸 데이터가 sender로 오지 않는 경우입니다. 이 문제를 해결하기 위해서는 Timer를 사용해서 일정 시간이 지나도 피드백이 오지 않는다면 데이터를 재전송하게끔 구현할 수 있습니다. 여기서 Timer의 시간을 결정하는 것을 엔지니어링적인 측면에 따라 결정하는게 올바른 방법입니다.
4. TCP
TCP는 위에서 디자인 했던 rdt의 기능들을 담고 있습니다. 하지만 rdt는 하나의 데이터를 보내고 정상적으로 받았다면 다음 데이터를 보내는 것을 가정으로 한 프로토콜입니다. 실제로는 수많은 데이터들이 지속적으로 전달되고 하나의 컴퓨터가 sender, receiver 둘다 될 수 있는게 현실입니다.
4.1. TCP 특징
-
point-to-point : 프로세스의 소켓끼리의 TCP connection이 맺어지게 되면 이 한 쌍의 소켓을 위해서만 동작한다.
-
reliable, in-order byte stream : 신뢰성이 높고, 순서를 지켜가며 데이터 전송이 이루어 진다.
-
pipelined : 데이터를 하나씩 보내고 받는게 아니라 한꺼번에 보낼 수 있다.
-
full duplex data : sender, receiver의 기준이 없다.
-
connection-oriented : 연결의 지향하는 프로토콜이다.
-
flow controlled : 소켓을 통해 내려오는 데이터는 자유롭지만 segment를 보내는 속도는 상대방 컴퓨터의 맞는 속도로 전송을 제어한다.
-
congestion controlled : 네트워크 상황에 맞게 보내는 속도를 제어한다.
4.2. TCP reliable

TCP도 sequence number를 사용하는데 현재 데이터를 담고 있는 segment의 sequence number에는 데이터의 시작 byte를 담고 있기 때문에 byte stream number라고 합니다. 또한 ACK도 사용하는데 ACK#100은 100sequence number의 데이터를 기다린다는 의미로 사용됩니다.
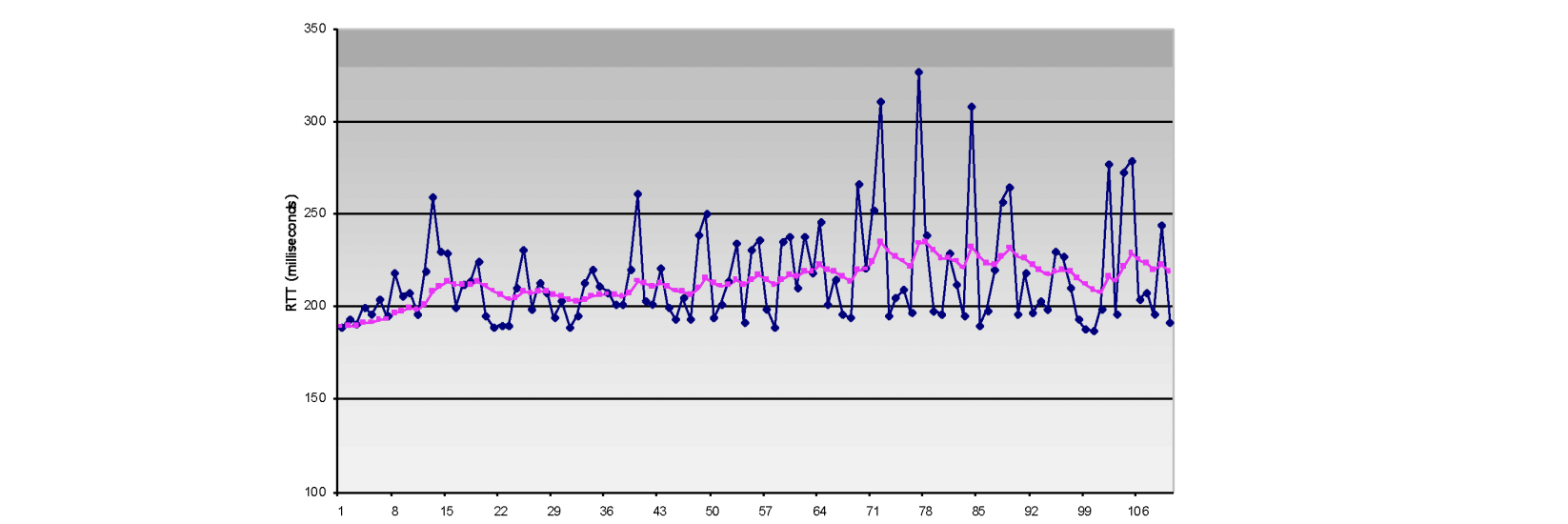
TCP도 loss에 대한 처리를 하기 위해 Timer를 사용하게 됩니다. Timer는 갔다가 돌아오는 시간 즉, RTT(Round Trip Time)를 측정하여 약간의 마진을 두어 설정합니다. TCP는 매번 segment를 보낼때 마다 RTT를 측정하게 되는데 이를 SampleRTT라고 합니다. 단 재전송된 segment에 대해서는 SampleRTT를 측정하지 않습니다.
하지만 각 segment가 겪에 되는 네트워크 환경(라우터의 queue)이 다르기 때문에 SampleRTT를 사용하기에는 적절하지 않아 EstimatedRTT를 사용합니다.
여기에 마진을 더하여 Timer로 사용합니다.
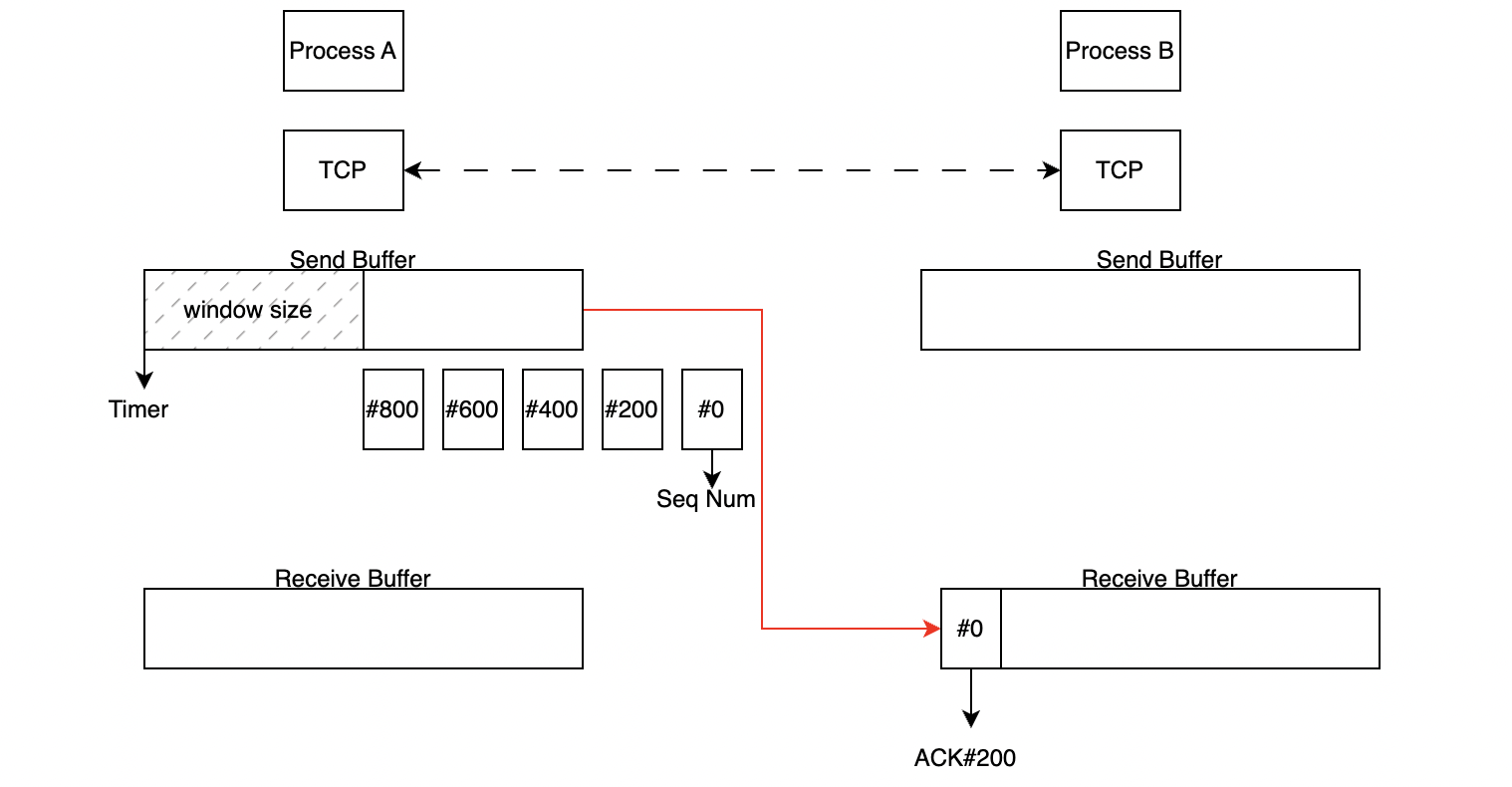
조금 더 구체적으로 알아보겠습니다.
Process 소켓 별로 담당하고 있는 TCP에 의해 send buffer와 receive buffer 자료구조를 사용하여 데이터 전송을 관리하게 됩니다.
TCP가 한번에 데이터를 보낼 수 있는 크기를 window size라고 합니다. 위의 그림은 이해를 돕기 위해 1000 bytes, TCP segment의 크기는 200bytes라고 가정한 상황입니다. Application으로 부터 온 데이터가 TCP send buffer에 쌓이게 되고 이를 segment 단위로 전송하게 됩니다. 이때 Timer는 첫 segment에 물리게 된 상태로 있습니다. 이 상태에서 상대방이 안전하게 seq num이 0인 데이터 #0를 받았다면 다음 데이터를 요청하기 위해 ACK#200을 피드백하게 됩니다.
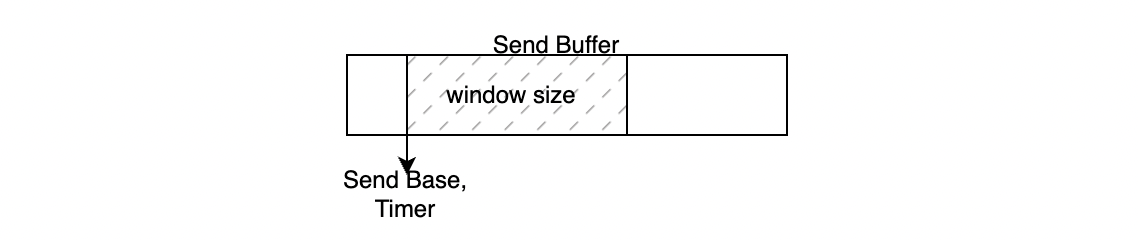
send base는 window의 제일 앞부분을 가르키는데 이 값이 200으로 이동하게 되고 #1000의 sequence num을 가진 segment를 전송할 수 있습니다.
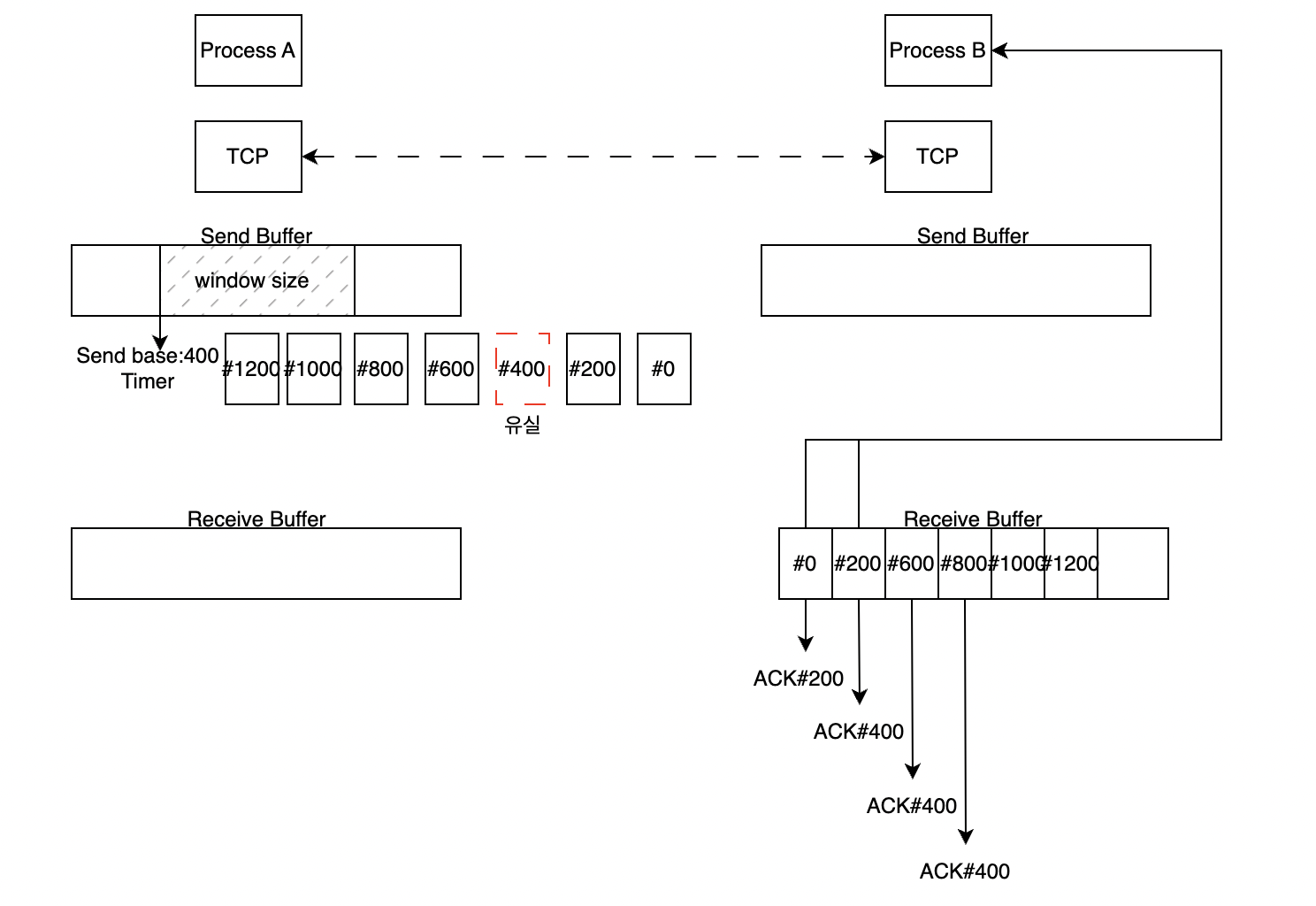
만약 중간에 #400데이터가 유실 되었다면 #0과 #200 데이터는 아무 이상없이 상위 계층으로 이동하고 적절한 ACK를 전송하여 send base와 timer는 400번으로 이동합니다.
receive buffer는 #600번 데이터를 상위 계층으로 올리지 않고 ACK#400을 요청하여 TCP의 in-order를 보장합니다. #800번 데이터도 마찬가지로 buffer에 대기하고 ACK#400을 요청합니다.
여기서 Timer에 설정한 시간이 지나면 #400번 데이터를 재전송하게 되고 이때는 400번 데이터부터 1200번 데이터까지가 한번에 상위 계층으로 올라가기 때문에 ACK#1400을 요청하게 됩니다.
여기서 알 수 있듯이 보내는 쪽의 send buffer와 받는 쪽의 receive buffer는 보내는 쪽의 데이터를 트래킹하고 받는 쪽도 데이터를 보내줘야 하기 때문에 결국 send와 receive의 구분이 없습니다.
그렇기 때문에 TCP의 Header에는 sequence number, acknowledgement number를 구분하여 현재 자신이 보낼 데이터를 위한 번호와 받은 데이터를 위한 번호를 한번에 작성하여 보내게 됩니다.
Timer보다 빨리 유실을 발견하는 법

위의 그림에서 알수 있듯이 데이터 유실이 일어나면 같은 ACK 요청이 일어나게 됩니다. 필수적으로 있어야 하는 기능은 아니지만 보통 같은 요청을 4번(처음은 정상적 응답)이 일어나면 재전송을 해주는 triple duplicate ACK를 방법을 사용하기도 합니다.
데이터의 이동
-
receive buffer에서 상위 계층 : Application이
read()하는 순간 -
상위 계층에서 send buffer : Application이
write()하는 순간
4.3. TCP flow control

위의 그림을 이해해보자면 Application 계층에서 process가 실행중이고 그 아래에 socket을 사용하고 있습니다. 그 아래에서 부터는 운영체제인데 각각 Transport, Network 계층으로 나누어져 있습니다.
맨 위의 빨간색 화살표는 Application이 read()할 때, receive buffer에 있는 데이터를 가져가고 있는 상황입니다. 결국 buffer의 데이터를 가져오는 것은 전적으로 Application이 결정하게 됩니다. 만약 receive buffer에 데이터가 들어오는 속도보다 read()하는 속도가 더 느리거나 read()를 너무 가끔씩 한다면 buffer가 꽉차게 되어 문제가 발생합니다.
따라서 send buffer에서 보내는 데이터의 속도는 받는 쪽의 read()하는 속도에 맞춰서 보내줘야 합니다. 이 문제는 receive buffer의 빈공간을 상대방에게 알려주는 방식으로 해결할 수 있습니다. 이 역할을 담당하는 헤더의 필드는 receive window size입니다. 결론적으로 receive window size에 따라 send buffer의 window size를 조절하게 됩니다.
고려 해야될 상황
TCP 통신은 send buffer에 보낼 데이터가 있거나 상대방으로 부터 데이터를 받았을때 피드백하는 2가지로 이루어집니다. 만약 send buffer는 비어있고 receive buffer가 가득차서 receive window size를 0으로 피드백 한 상황이라면 상대방은 receive buffer가 비어있는지 알 수 없기 때문에 데드락 현상이 일어날 수 있습니다. 이런 상황을 방지하기 위해 receive window size를 0으로 받았다면 send buffer에서 대기중인 데이터의 1byte를 지속적으로 보내는 방식으로 buffer가 비었는지 확인합니다.
segment의 크기를 결정하는법
segment의 크기는 클수록 오버헤드가 줄어들기 때문에 좋다고 볼 수 있습니다. 그렇다고 maximum size가 채워질때 까지 send buffer에서 기다릴 수는 없습니다.
-
첫번째 segment는 그 크기가 얼마가 되었든 우선 보낸다.
-
만약 보낸 데이터의 피드백이 돌아오기전에 maximum size가 채워졌다면 피드백 전에 데이터를 보낸다.
-
피드백이 돌아올때까지 maximum size가 안채워졌다면 그만큼 보낸다.
위의 3개의 말은 매우 단순해보이지만 합리적인 의미를 가지고 있습니다.
피드백이 돌아올때까지 segment의 maximum size까지 데이터가 안채워졌다는 Application의 write()보다 네트워크 상황이 더 좋기 때문에 segment의 크기가 작아도 상관없고 반대로 피드백이 돌아올때 데이터 많이 채워졌다는 말은 네트워크 상황보다 write()가 더 빈번하게 일어난다고 생각하여 segment의 크기가 커지게 됩니다.
4.4. connection management
위에서 TCP의 다양한 동작들을 알아보았는데 이런 동작들을 하기 위해 TCP가 어떻게 서로 연결되는지 알아보겠습니다.
3-way handshake

TCP는 서로 연결을 하기 위해 3-way handshake를 방법을 사용합니다. 상식적으로 내가 모르는 사람에게 전화를 걸었을 때(1) 받는 사람은 여보세요(2)라는 응답을 하고 나도 거기에 대해 여보세요(3)를 통해 서로 잘 들린다는 의사소통을 한다.
TCP에서는 연결을 요청하기 위해 헤더에 SYN 비트를 1로 하고 최초의 seq num를 담아 보냅니다. 이것의 응답으로 SYN과 ACK 플래그를 1로 담아 보내고 ack num을 보냅니다. 이 두가지 통신은 헤더의 정보만을 담아 통신하지만 마지막 메세지는 일반적인 ack segment이기 때문에 연결이 잘 되었다는 ACK비트와 데이터를 담아서 전송할 수 있습니다.
4-way handshake

Application에서 close()를 수행했을 때 TCP 연결을 해지하게 됩니다. 이때 클라이언트는 FIN비트를 담아 보내고 서버에는 아직 데이터를 보내야할게 있다면 ack segment를 보내고 FIN을 보냅니다. 클라이언트는 이 FIN에 대한 응답으로 ack segment를 피드백을 보내게 되는 4-way handshake를 사용합니다.
마지막에 클라이언트가 응답을 하고 대기하는 시간이 있습니다. 만약 마지막 ack segment를 보내고 연결을 바로 끊었는데 데이터가 유실되었다면 서버입장에서는 FIN이 유실되었다고 생각하여 FIN을 계속 보내는 상황이 생길 수 있기 때문에 일정시간 대기하게 됩니다.
4.5. congestion control
congestion control은 네트워크 상황을 고려한 데이터 통신 방법입니다.
congestion scenario 1
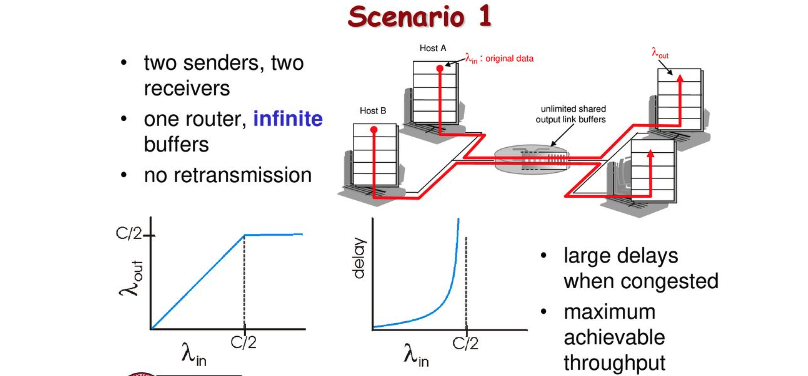
만약 위의 시나리오처럼 queue의 크기가 무제한인 하나의 라우터가 있고 재전송이 없는 2개의 프로세스가 데이터를 전송하는 상황이라면 하나의 프로세스가 보내는 양()이 증가하면 받는 프로세스의 양()도 증가하게 됩니다(최대 , ). 여기서 보내는 데이터의 양이 증가할 수록 delay도 같이 증가하게 됩니다.
congestion scenario 2
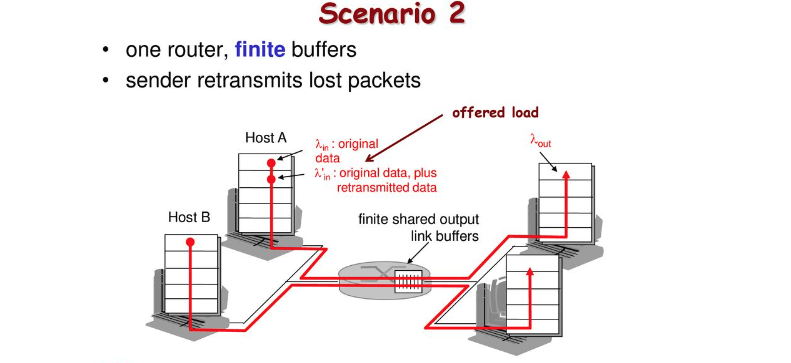
조금 더 현실적으로, queue의 크기가 제한되어지고 재전송이 있는 상황으로 바꿔보겠습니다.
이 상황에서는 재전송이 있기 때문에 application에서 보내는 데이터양( 보다 TCP에서 보내는 데이터양(이 더 많습니다.

실제로는 불가능하지만 라우터에 있는 queue가 비어있는지 알 수 있다고 가정하면 여유 공간이 있을때만 데이터를 보내면 되기 때문에 문제가 되지 않습니다.
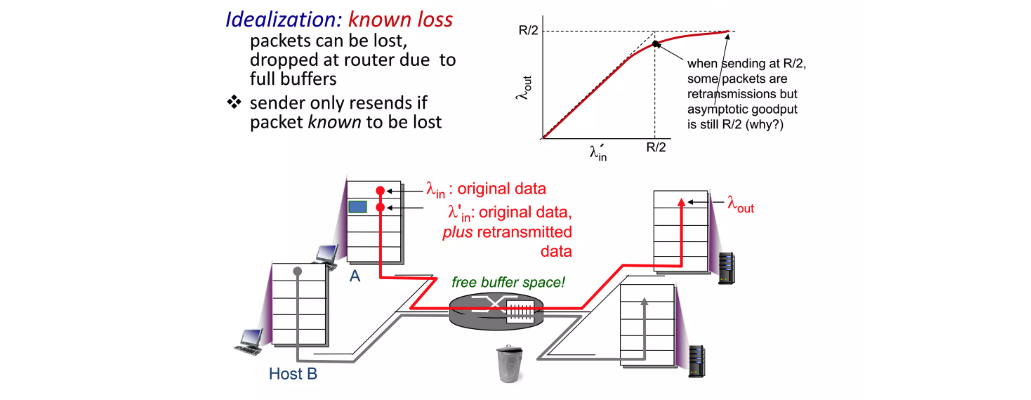
실제 상황은 queue에 공간이 있는지 알 수 없기 때문에 loss가 발생하게 되고 결국 TCP가 보내는 데이터 양은 더 증가하게 됩니다.
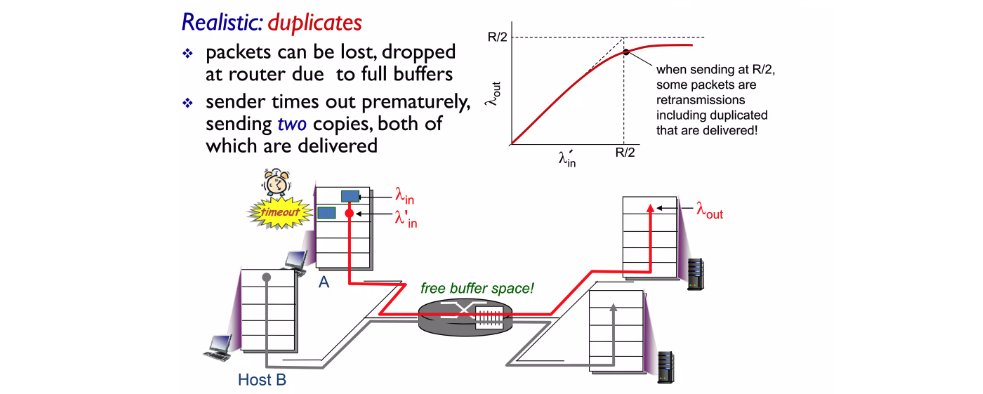
또는 loss가 일어나지 않았더라도 timeout으로 인해 중복된 데이터를 보낼 수도 있습니다.
congestion scenario 3
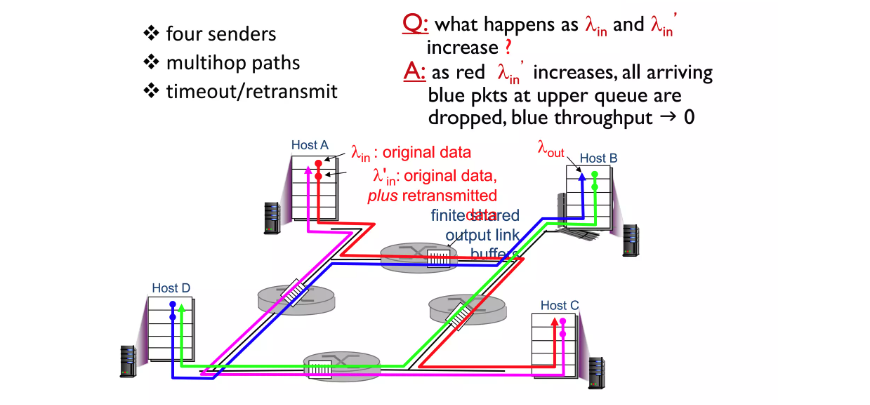
senario 2보다 조금 더 구체적으로 데이터들이 2개의 라우터들을 거쳐서 전달되는 상황입니다.
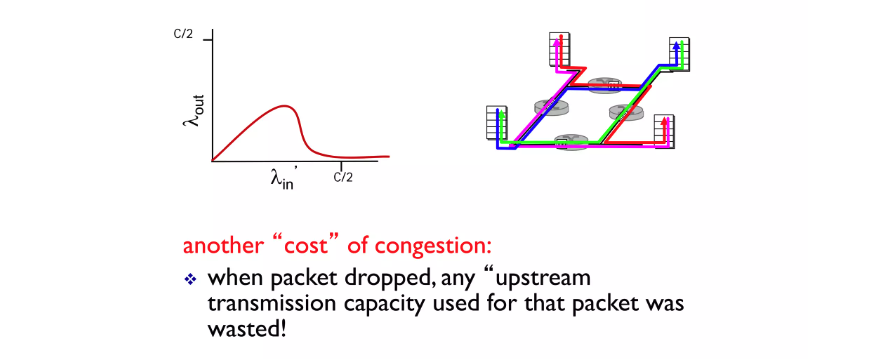
이런 상황에서 모든 HOST들이 같이 데이터를 보내는 양을 증가시키게 되면 어느 시점부터는 데이터 전송이 이루어지지 않는 상황이 발생합니다. 그 이유는 만약 A가 B로 데이터를 전송하고 D도 B로 전송하는 상황이라면 공통된 라우터에서 D의 데이터들은 우선순위가 계속 밀리게 됩니다. 데이터는 물이 흐르듯 upstream router에서 downstream router로 전송되는데 downstream에서 데이터가 유실되면 현재 거쳐온 네트워크 자원들이 낭비되고 있는 상황입니다.
위와 같은 상황을 방지하기 위해 현재 내가 보낼 수 있는 데이터양을 최대로 사용하지 않고 적절히 조절하는 사용하여 모든 사람들이 네트워크를 이용할 수 있도록 조절합니다. 결국 congestion control를 하기 위해서는 현재 네트워크 상황을 어느정도 인지해야 합니다.
Congestion control
데이터를 보내는 양을 조절하기 위해 Send buffer의 window size를 조절하는 방법으로 receive window size를 이용한다고 했습니다. 여기서 congestion window size를 추가해 둘 중에 더 작은 값을 send buffer window size로 설정합니다.
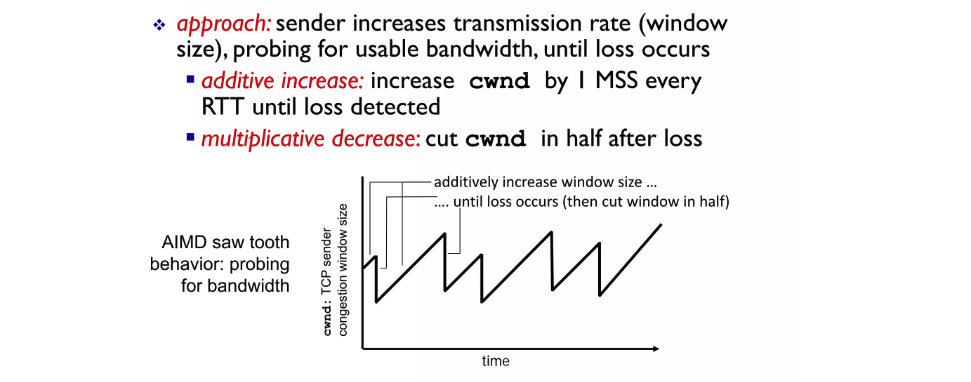
additive increase
congestion window를 조절하는 방법은 segment를 보내고 그것에 대한 피드백을 제대로 받으면 congestion window를 1 MMS(maximum segment size) 늘리는 작업을 합니다.
multiplicative decrease
congestion window를 계속 늘리다 보면 어느 순간 Loss가 발생(Timer, dup ACKs) 하게 되고 이때는 절반으로 줄이게 됩니다. 늘릴 때는 다른 네트워크들에 영향을 최소화 하기위해 조금씩 늘리지만 문제가 생겼을때는 과감히 데이터 양을 줄입니다.
slow start
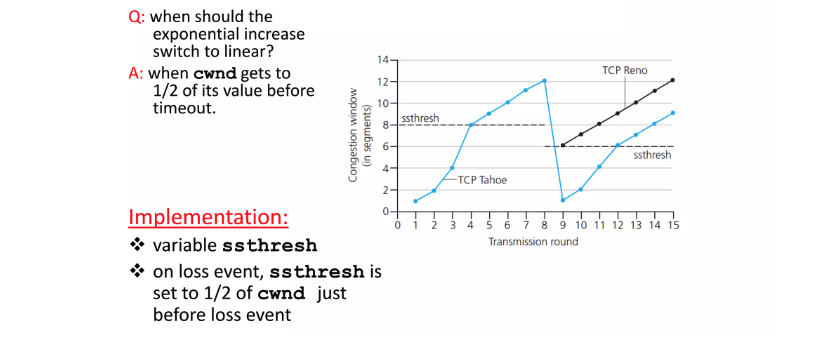
congestion window의 초기크기는 1 MMS로 시작하게 됩니다. 작은 값으로 시작하기 때문에 초기에는 지수적으로 증가하게 되고 어느 임계점(ssthresh)에 도달하게 되면 1 MMS씩 증가(additive increase)시키게 됩니다.
Loss라고 판단하는 2 가지 상황은 Timer와 Duplicate ACK 입니다.
Duplicate ACK는 특정 segment가 유실되어 그 뒤의 segment들이 반복적으로 피드백을 주는 상황이기 때문에 전적으로 네트워크의 문제라고 보지 않습니다. 반면에, Timer같은 경우는 어떠한 피드백도 오지 않는 상황이기 때문에 네트워크에 큰 문제가 생겼다고 추측할 수 있습니다.
위의 그림에서 파란색 그래프는 최초의 TCP Tahoe입니다. Tahoe는 위 2가지 상황에 대해서 구분하지 않고 무조건 congestion window를 1 MMS로 줄였습니다. 그 이후 버전인 TCP Reno는 Timer는 Tahoe와 같지만, Duplicate ACK 상황에서는 congestion window를 절반으로 줄입니다.
4.5. TCP Fairness

TCP는 결국 모든 사용자 별로 독립된 버퍼와 공용의 네트워크 상황을 고려하여 데이터 전송을 조절하게 됩니다. 위와 같은 상황에서 각각 씩 데이터를 보낼 수 있게 보장되어야 합니다.
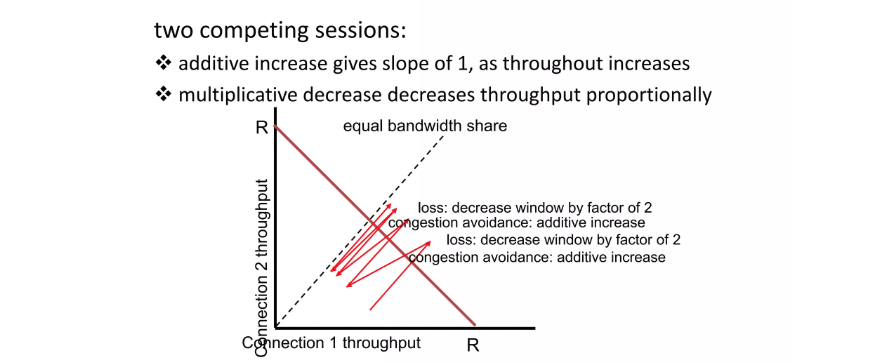
공평함을 보장하기 위해서 점선으로 표현된 위치에 위치하는 것입니다. TCP를 사용하면 이 위치로 수렴하는 것을 보장할 수 있습니다.
빨간색 화살표의 시작부분(connection 1의 양 R/2, connection 2의 양 R/4)은 현재 네트워크가 이상이 없기 때문에 둘이 같이 데이터 양을 늘리게 됩니다. 어느 정도 늘린 후 그 양을 벗어나게 되면 둘다 절반으로 줄어들게 되는데 이 과정을 반복하게 되면 결국 최적의 위치를 향해 수렴하게 됩니다.
