이번 시간에는 개발자가 작성하는 소스코드를 어떻게 컴퓨터가 이해하는지 알아보겠습니다.
지금까지 컴퓨터는 0과 1만 이해할 수 있는 기계라고 설명했는데 소스코드를 어떻게 이해할까요?
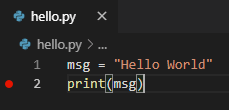
컴퓨터는 위와 같은 소스코드를 아래와 같이 기계어(저급언어)로 변환해야 이해할 수 있습니다.
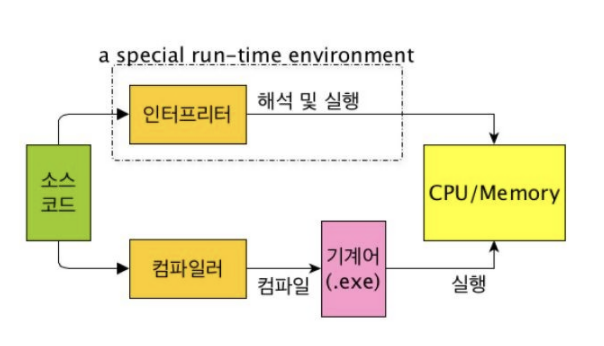
개발자들이 사용하는 C, C++, Java, Python 등은 개발자를 위한 언어로 보통 고급언어라고 부릅니다. 하지만 컴퓨터는 고급언어를 이해할 수 없기 때문에 기계어, 즉 저급언어로 변환하는 과정이 필요 합니다.
저급언어

-
기계어 : 2진수 또는 16진수로 표현된 저급언어(명령어)
-
어셈블리어 : 기계어를 사람들이 읽기 편한 형태로 변환한 저급언어(명령어)
고급언어
-
컴파일 언어 : 컴파일 언어는 소스코드 전체를 컴파일러가 기계어로 번역하고 실행하는 구조
-
인터프리트 언어 : 인터프리터가 소스코드 한줄씩 번역하여 실행하는 구조
컴파일 언어 vs. 인터프리트 언어
컴파일 언어는 실행되기 위해 전체 소스코드를 컴파일러가 해석하는 과정을 통해 오류를 발견하고 에러를 반환합니다. 인터프리트 언어는 오류 직전까지 실행이 가능합니다.
모든 고급 언어는 2가지로 구분되지는 않습니다. 앞서 소개드린 2가지 언어는 대표적인 방식일 뿐이며 Java의 경우에도 컴파일 언어와 인터프리트 언어를 혼합한 JIT 방식을 사용하고 있습니다.
명령어의 구조
명령어는 보통 무엇을 대상(오퍼랜드)으로 어떤 행동(연산코드)을 할지로 구성되어 있습니다.
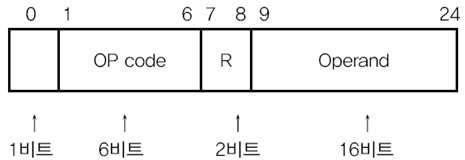
오퍼랜드(Operand)
오퍼랜드는 연산에 사용될 데이터 또는 데이터가 저장된 위치를 명시합니다. 하지만 저장된 위치를 명시하는 경우가 훨씬 많기 때문에 오퍼랜드의 필드를 주소필드라고도 표현합니다.
왜 위치를 나타내는 경우가 많을까?
오퍼랜드 필드에 데이터를 명시할 경우 표현 가능한 데이터가 한정적이기 때문에 주소를 명시하는게 효율적입니다.
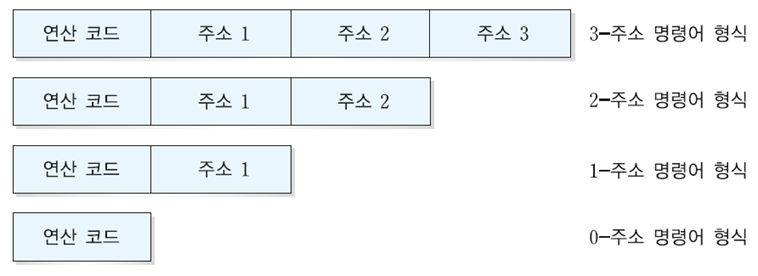
명령어의 구조에 오퍼랜의 개수는 하나도 없거나 하나 이상 일수 있습니다.
연산코드(Operation code)
연산코드는 기본적으로 CPU마다 다를 수 있지만 공통연산은 아래와 같습니다.
-
데이터 전송 : 데이터를 옮기고(MOVE), 메모리에 저장하고(STORE), 메모리에서 CPU로 데이터를 가져오고(FETCH), 데이터를 스택에 저장하고(PUSH), 스택에서 데이터를 가져오는(POP) 명령어
-
산술/논리 연산 : 4칙연산, AND/OR/NOT 논리 등
-
제어 흐름 변경 : 특정 주소로 실행(JUMP), 특정 조건시 특정 주소 실행(CONDITIONAL JUMP), 실행을 멈추기(HALT), 되돌아올 주소를 저장하고 특정 주소 실행(CALL), CALL을 호출할 때 저장했던 주소로 돌아오기(RETURN)
-
입출력 제어 : 특정 입출력 장치로 부터 데이터 읽기(READ), 쓰기(WRITE), 입출력 장치 시작(START IO), 상태확인(TEST IO)
위의 내용을 외울 필요는 없으며 이해를 위해 이런 연산코드가 있다는 것을 알고 있으면 됩니다.
명령어 주소 지정 방식
주소 지정 방식에 대해 알아보기 전 유효주소라는 용어는 연산에 사용 될 데이터가 저장된 위치를 의미합니다. 앞선 내용에서 오퍼랜드 필드에 저장되는 내용을 데이터, 데이터가 저장된 주소라고 했는데 추가적으로 데이터가 저장된 주소는 메모리의 주소와 특정 레지스터의 이름으로 나눌 수 있습니다. 그렇다면 명령어가 주소를 지정하는 방식에 대해서 알아보겠습니다.
즉시 주소 지정방식
오퍼랜드 필드에 데이터를 직접 명시하는 방식입니다. 데이터를 표현할 수 있는 크기가 제한된다는 단점이 있지만 데이터를 찾는 과정이 없어 빠르다는 장점이 있습니다.

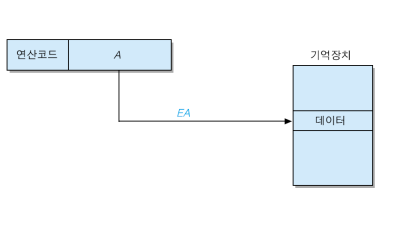
직접 주소 지정방식
오퍼랜드 필드에 유효주소를 직접적으로 명시하는 방식입니다. 이어서 설명한 간접 주소 지정방식 보다는 빠르지만 메모리의 용량이 큰 경우 오퍼랜드의 길이가 길어지는 단점이 있습니다.
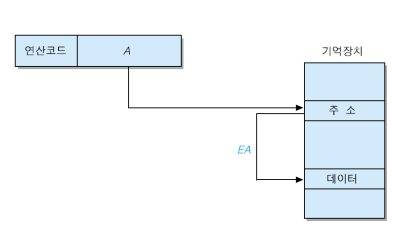
간접 주소 지정방식
오퍼랜드 필드에 유효주소를 가르키는 유효주소를 명시하는 방식입니다. 이 방식은 기억장치의 용량만큼 주소를 표현할 수 있다는 장점이 있지만 2번 접근한다는 단점이 있습니다.
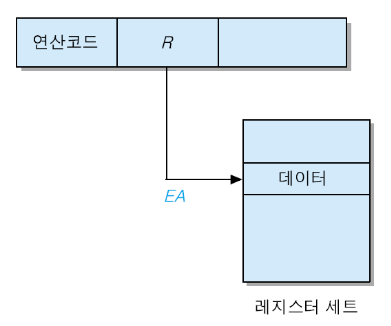
레지스터 주소 지정방식
오퍼랜드 필드에 데이터가 저장된 레지스터의 번호를 명시하는 방식입니다. 기본적으로 CPU는 메모리 접근 보다 레지스터에 접근하는 것이 빠릅니다. 하지만 데이터가 저장될 수 있는 공간이 CPU내부 레지스터들로 제한됩니다.
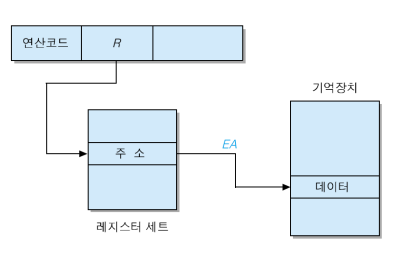
레지스터 간접 주소 지정방식
오퍼랜드 필드에 유효주소를 가르키는 레지스터 번호를 명시하는 방식입니다. 이 방식은 주소를 지정 할 수 있는 기억장치의 영역이 확장되는 장점이 있습니다.
위에 설명한 주소 지정방식 이외에도 다양한 지정방식이 있지만 현재는 이정도만 이해해도 충분합니다.
