이번 포스트에는 한정된 시간안에 어떻게 CPU가 메모리에 저장된 명령어들을 처리하는지 알아보겠습니다.
명령어 파이프라인
명령어 파이프라인은 현대 CPU에서 없어서는 안될 중요한 개념입니다.
하나의 명령어가 처리되는 과정은 기본적으로 명령어 인출, 해석, 실행, 결과 저장 4단계로 나눌 수 있으며 전공서에 따라 인출과 실행 또는 명령어 해석, 실행, 접근, 결과 저장으로 나누기도 합니다.
여기서 중요한 점은 같은 단계가 겹치지만 않는다면 CPU는 명령어를 동시에 실행할 수 있다는 점입니다.
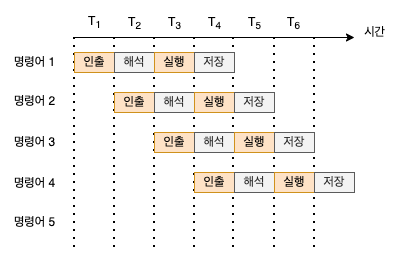
위의 그림에서 시간별로 여러개의 명령어를 실행할 수 있습니다. 이렇게 명령어를 동시에 병렬로 처리하는 방식을 명령어 파이프라인이라고 표현합니다. 만약 명령어 파이프라인을 사용하지 않는다면 하나의 명령어가 끝나고 나서야 다음 명령어를 처리하기 때문에 비효율적입니다.
명령어 파이프라인은 항상 이상적으로 실행할 수 있는건 아닙니다. 즉 동시에 명령어를 처리할 수 없는 경우가 존재하는데 이런 상황을 파이프라인의 위험이라고 말하며 크게 3가지 경우가 있습니다.
-
데이터 위험 : 명령어 간의 의존성에 의해 야기 (이전 명령어를 끝까지 실행해야만 비로소 실행해야 하는 경우)
-
제어 위험 : 프로그램 카운터의 갑작스러운 변화에 의해 야기 (JUMP, CALL, INTERRUPT 등), 이런 상황을 방지하기 위해 PC를 예측하는 분기 예측 기술이 존재
-
구조적 위험 : 서로 다른 명령어가 같은 CPU 부품(ALU, 레지스터)를 쓰려고 할 때
슈퍼스칼라
슈퍼스칼라는 CPU 내부에 여러 개의 명령어 파이프라인을 포함한 구조입니다.
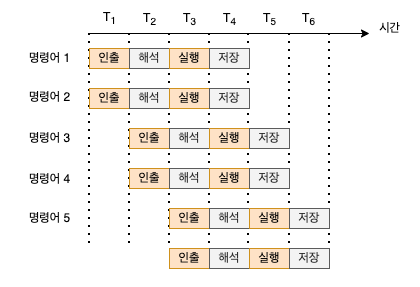
앞선 포스트에서 하드웨어적 스레드에서 멀티스레드는 하나의 코어는 동시에 여러개의 명령어를 처리할 수 있다고 했습니다. 이런 경우에 사용할 수 있는게 슈퍼스칼라 구조입니다.
이론적으로 파이프라인 개수에 비례하여 처리속도가 증가하지만 파이프라인 위험도도 같이 증가하기 때문에 파이프라인 개수에 비례하여 처리 속도가 증가하진 않습니다.
비순차적 명령어 처리
명령어를 순차적으로 실행했을때 파이프라인 위험이 발생하는 상황이라면, 순서를 적절히 바꿔 비순차적으로 실행시켜 성능 향상을 시킬 수 있다.
- 100번지에 1을 저장하라
- 101번지에 2를 저장하라
- 100번지 + 101번지 값을 103번지에 저장하라
- 104번지에 1을 저장하라
- 105번지에 2를 저장하라
위와 같은 명령어가 있을때 1번과 2번 명령어는 명령어 파이프라인을 적용할 수 있지만 3번 명령어는 1번과 2번 명령어가 전부 끝날때까지 실행될 수 없습니다. 따라서 서로 영향이 없는 4번과 5번 명령어를 먼저 실행하고 마지막으로 3번 명령어를 실햄함으로 성능을 향상 시킬 수 있습니다.
중요한건 아무 명령어나 순서를 바꿀 수는 없으며 순서를 바꿨을때 전체 프로그램 실행 흐름에 영향이 없을 경우에만 가능합니다.
