paper : Yoon Kim(2014)
원래 CNN은 컴퓨터 비전을 위해 발명되었지만 이후 NLP에서도 효과적인 것으로 나타났으며 다양하게 이용되고 있다.
이 논문에서는 문장의 분류를 위해 CNN을 사용한 실험에 대해서 설명하고 있다.
model
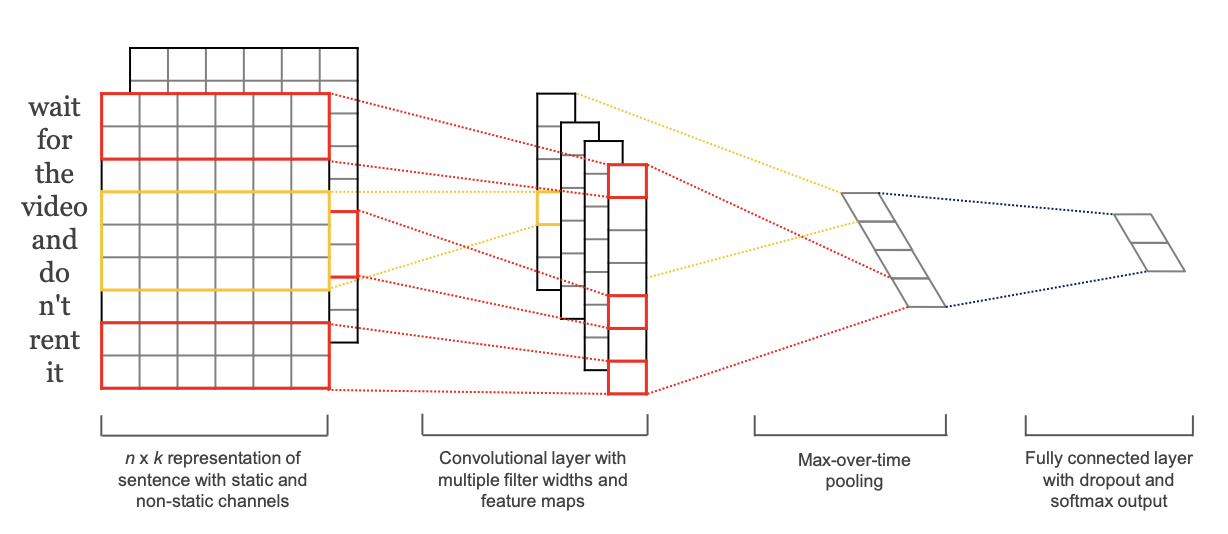
이미지 처리에서는 2D CNN을 수행한다. 보통 이미지 처리에서는 필터가 상하좌우로 움직이며 특징을 추출한다.
자연어 처리에서는 1D CNN을 수행한다. 위의 사진처럼 단어는 어떠한 차원을 가진 벡터로 표현이 된다.
이 연구에서 사용한 word vector는 사전 학습된 word2vec(static)와 추가적으로 학습이 이루어지는 벡터(non-static)등을 사용하고 있다.
이렇게 표현된 단어들의 특징을 추출하기 위한 필터 크기는 (filter_size, word_dimention)으로 사용되기 때문에 이 필터는 위, 아래로 움직이며 특징을 추출하기 때문에 1D CNN이라고 표현한다.
예를들어 5개의 단어로 이루어져 있는 문장이 128차원으로 표현이 되고 filter는 (2,128)을 가지고 있다면
1D CNN을 통한 output은 n-h+1차원인 (4,) 의 크기를 가진 벡터를 얻을 수 있다.
( stride = 1일 경우 )
여러가지 필터를 통해 생성된 각각의 feature map에서 가장 중요한 특징 ( max-over-time pooling)을 추출하는 연산을 거친다. 이 과정을 거치게 되면 길이가 서로 다른 feature map들을 처리할 수 있다.
이 특징들이 모인 층은 fully connected layer층으로 전달되어 softmax를 통해 확률 분포로 출력이 된다.
처음에 언급했듯이 이 논문에서는 학습하는 동안 변하지 않는 static, 학습이 진행되며 같이 튜닝이 되는 non-static vector를 사용하며 그림에서 알 수 있듯이 2가지의 채널을 사용하고 filter가 둘다 적용되는것을 볼 수 있다.
정규화
정규화를 위해 가중치 벡터의 끝에서 두 번째 layer에 드롭아웃을 사용한다.
드롭아웃은 순전파-역전파 중 숨겨진 유닛들의 비율 p를 임의로 드롭아웃(0으로 설정)하여 숨겨진 유닛들의 co-adaptition (같은층의 노드들이 같은 입력과출력의 강도를 가지게 되는 것, 노드들이 같은일을하게 되고 결국 컴퓨팅 파워, 메모리 낭비로 이어짐)을 방지한다.
두 번째 레이어에서
위의 식을 적용하는 대신
위와 같은 식을 사용하는데 여기서 는 요소별 곱셈을 뜻한다.
은 확률 가 1인 베르누이 랜덤 변수의 "마스킹"벡터이다.
기울기들은 마스크되지 않은 유닛들을 통해서만 역전파된다.
테스트 시간에 학습된 가중치 벡터는 가 되도록 p로 스케일링되고 은 보이지 않는 문장의 점수를 매기기 위해 (드롭아웃없이) 사용된다.
경사 하강 단계 이후 일 때마다 w를 가 되도록 재조정하여 가중치 벡터의 을 추가로 제한시킨다.
하이퍼파라미터들과 학습
모든 데이터 세트에 대해서 각각 100개의 feature map이 있는 filter window(h) 3, 4, 5 과 0.5의 드롭아웃 비율(p), 제약 조건 3, 50의 미니 배치 크기를 사용한다. 이 값은 SST-2 개발 세트에서 그리드 검색을 통해 선택되었다.
사전학습 워드벡터
비지도 신경 언어 모델에서 얻은 단어 벡터를 초기화하는 것은 대규모 지도 학습 세트가 없을 때 성능을 향상시키는 방법이다.
google의 word2vec을사용했고 벡터들의 차원은 300이며 CBOW 아키텍쳐를 사용하여 학습되었다.
사전 훈련된 단어 세트에 없는 단어들은 랜덤하게 초기화시킨다.
모델 변형
이 연구에서는 모델에 여러가지 변형을 실험했다.
-
CNN-rand : 모든 단어들을 랜덤하게 초기화하고 학습하며 수정하는 기본 baseline
-
CNN-static : word2vec으로부터 사전학습된 벡터들을 가진 모델. (랜덤하게 초기화 되어진 단어들을 포함, 단어세트에 없는 단어들) 모든 단어들은 바뀌지 않고 오직 모델의 다른 파라미터들만 학습된다.
-
CNN-non-static : 위와 같지만 사전 학습된 벡터들을 task에 맞게 fine tuning함
-
CNN-multichannel : 2개의 워드벡터 세트를 가진 모델. 벡터들의 각각의 세트들은 channel로써 다루어지고 각각의 필터에 둘다 적용된다. 하지만 기울기들은 이 channel들중 하나를 통해 역전파 되어진다.
따라서 이 모델은 다른 한 세트를 정적으로 유지하면서 한 세트의 벡터를 미세 조정할 수 있다.
두개의 채널은 word2vec으로 초기화된다.
결과 고찰
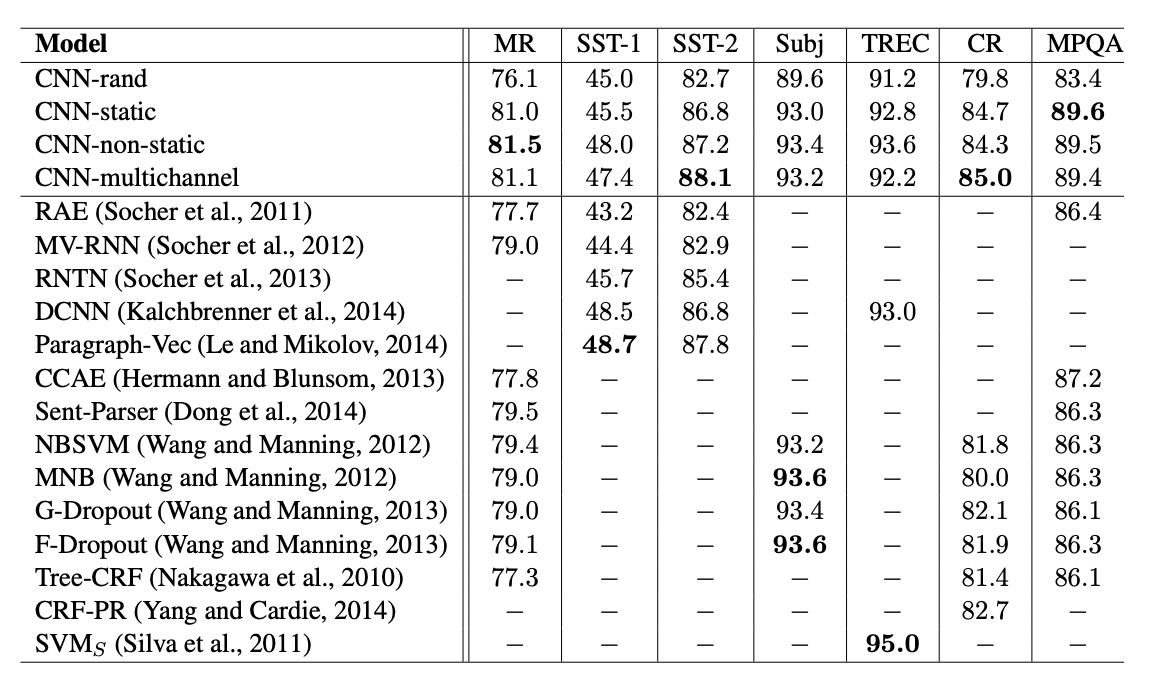
기준모델(cnn-rand)은 성능이 뛰어나지 않았다.
반면에 사전학습 벡터를 사용하는것을 통해 성능 향상을 기대했고, 그 결과는 놀라운 성능 향상이 있었다.
정적벡터를 가진 간단한 모델도 놀랄만하게 잘 성능이 좋으며, 복잡한 풀링 설계나 미리 계산해야 하는 parse trees을 활용하는 복잡한 딥러닝 모델의 반해 경쟁력있는 결과를 주었다.
- 멀티채널 vs 싱글채널 모델
처음에는 멀티채널구조(학습된 벡터가 원래 값에서 너무 많이 벗어나지 않도록 함으로써)가 오버피팅을 방지하고 특히 적은 양의 데이터 셋에 성능도 싱글채널보다 좋을 거라고 기대했지만 결과는 달랐고 fine tuning 프로세스 정규화를 위한 추가 작업이 필요함
예를들어 non-static 부분에 대한 추가적인 채널을 사용하는 것 대신에 싱글채널만 유지하고 학습하는 동안 변경할 수 있는 추가 차원을 적용할 수 있다.
- static vs non-static
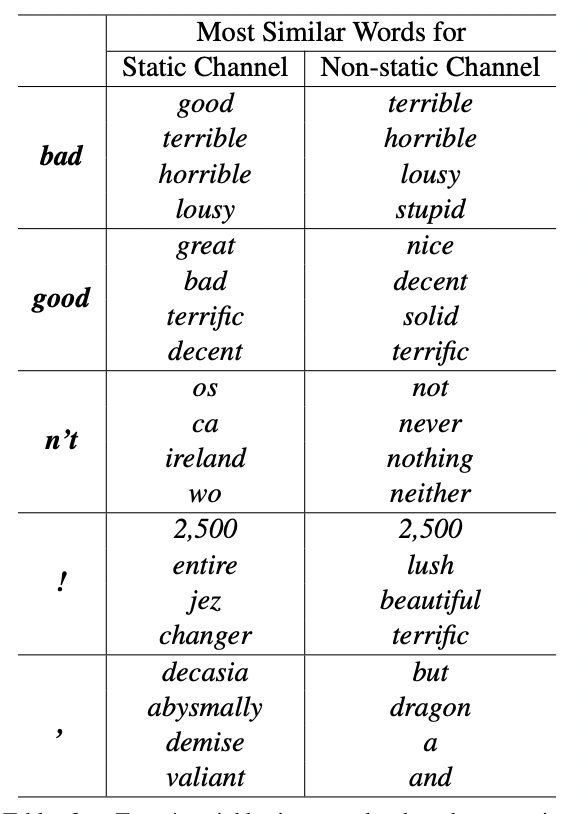
싱글채널 비정적 모델의 경우와 마찬가지로, 멀티채널모델은 non-static 채널을 미세 조정하여 task게 맞게 구체적으로 만들 수 있다.
예를들어 word2vec에서 good은 bad와 가장 유사하다. 아마도 이 단어들이 구문적으로 동등하기 떄문이다.
하지만 SST-2데이터 셋에서 파인튜닝된 non-static에서의 벡터들은 이렇지 않다.
이와 같이, good은 틀림없이 감정을 표현하는것에 대하여 great 보다 nice와 가깝고 실제로 학습된 벡터에 반영되어진다.
사전학습된 벡터세트에 없는 무작위로 초기화된 토큰의 경우, 파인튜닝을 통해 더 의미있는 표현으로 학습할 수 있다. 네트워크는 느낌표가 과장된 표현과 연관되고 컴마(,)들은 접속,결합적인 것을 학습한다.
결론
이 연구에서 우리는 word2vec위에서 구축한 CNN을 사용한 일련의 실험들을 설명하였다.
하이퍼파라미터들의 튜닝을 거의 하지 않았음에도 불구하고, 한개의 컨볼루션 레이어를 가진 단순한 CNN은 놀랄만게 좋은 성능을 발휘한다.
이 결과는 단어 벡터의 비지도 사전 훈련이 NLP 딥러닝에 중요한 요소라는 증거로서 추가되었다.
