MLflow 개념
MLflow가 없던 시절
- 사람들이 각자 자신의 코드를 작성하고 학습시 수행한 Parameter, Metric을 따로 기록
- 개인 컴퓨터, 연구실 서버를 사용하다가 메모리 초과로 Memory Exceed 오류 발생
- 학습하며 생긴 Weight File을 저장해 다른 동료들에게 공유
- Weight File 이름으로 Model Versioning을 하거나 아예 하지 않음
MLflow가 해결하려고 했던 pain Point
- 실험을 추적하기 어렵다.
- 코드를 재현하기 어렵다.
- 모델을 패키징하고 배포하는 방법이 어렵다.
- 모델을 관리하기 위한 중앙 저장소가 없다.
MLflow
- 머신러닝 실험, 배포를 쉽게 관리할 수 있는 오픈소스
- 관련 오픈소스 중 제일 빠르게 성장 중
- CLI, GUI환경 지원
핵심 기능
- Experiment Management & Tracking
- 머신러닝 관련 실험들을 관리하고 각 내용을 기록할 수 있다.
- 실험에 사용한 메타정보나 부산물을 저장할 수 있다.
- Model Registry
- MLflow로 실행한 모델을 Model Registry(모델 저장소)에 등록할 수 있다.
- 모델 저장소에 모델이 저장될 때마다 해당 모델에 버전이 자동으로 업데이트 된다.
- 모델 저장소에 등록된 모델은 다른 사람에게 쉽게 공유 가능하고 활용할 수 있다.
- Model Serving
- 모델 저장소에 등록한 모델을 REST API 형태로 Serving할 수 있다.
- 직접 Docker image를 만들지 않아도 생성할 수 있다.
MLflow Component
-
MLflow Tracking
- 머신러닝 코드 실행, 로깅을 위한 API, UI 제공
- MLflow Tracking을 사용해 결과를 local, server에 기록하여 다른 실험과 비교할 수 있다.
-
MLflow Project
- 머신러닝 프로젝트 코드를 패키징하기 위한 표준
- MLflow Tracking API를 사용하여 MLflow는 프로젝트 버전을 모든 파라미터와 자동으로 로깅
-
MLflow Model
- 모델은 모델 파일과 코드로 저장
- 다양한 플랫폼에 배포할 수 있는 여러 도구 제공
- MLflow Tracking API를 사용하여 자동으로 프로젝트에 대한 내용을 사용한다.
-
MLflow Registry
- MLflow Model의 전체 Lifecycle에서 사용할 수 있는 중앙 모델 저장소
MLflow 사용하기
설치
-pip install mlflow
MLflow Tracking - Experiment
- MLflow에서 제일 먼저 Experiment 생성
- 하나의 Experiment는 진행하고 있는 머신러닝 프로젝트 단위로 구성
- 정해진 Metric으로 모델을 평가(RMSE, MSE, Accuracy ...)
- 하나의 Experiment는 여러 Run(실행)을 가짐
mlflow experiments create --experiment-name my-first-experiment: 생성하기ls -al를 하면 mlruns라는 폴더가 생긴다. 이 폴더에 실험에 대한 정보를 기록mlflow experiments list: Experiment 리스트 확인
MLflow Project
- MLflow를 사용한 코드의 프로젝트 메타 정보 저장
- 프로젝트를 어떤 환경에서 어떻게 실행시킬지 정의
- 패키지 모듈의 상단에 위치한다.
- 프로젝트 상단에
MLProject파일 생성 (DockerFile과 유사함)
name: tutorial
entry_points:
main:
command: "python train.py"MLflow Tracking - Run
- 하나의 Run은 코드를 1번 실행한 것을 의미
- 보통 Run은 모델 학습 코드를 실행
- 한번의 코드 실행 = 하나의 Run을 생성
- Run을 하면 여러가지 내용이 기록됨
Run에서 로깅하는 것
- Source: 실행한 Project 이름
- Version: 실행 Hash
- Start & End time
- Parameters: 모델 파라미터
- Metrics: 모델의 평가 지표
- Tags: 관련된 Tag
- Artifacts: 실행과정에서 생기는 다양한 파일들(이미지, 모델 Pickle 등)
Run
mlflow run logistic_regression --experiment-name my-first-experiment--no-conda: 콘다없이 실행할 수 있음
MLflow Tracking - UI
-
mlflow ui: UI환경으로 기록을 확인하기 -
localhost:5000번으로 접속할 수 있으며 커맨드나 artifact 등 다양한 정보를 확인
MLflow autolog
-
기존 코드에서는
mlflow.log_param("name", value)식으로 직접 명시를 해주어야 한다. -
autolog를 활용 하면
mlflow.sklearn.autolog()와with mlflow.start_run():문을 활용하여 그 안에서 fit을 수행하여 자동으로 log를 남길 수 있다. -
주의사항으로 모든 프레임워크에서 사용 가능한 것은 아니며(torch.nn.Module는 적용안되지만 lighting은 지원함)
-
자세한 내용은 공식홈페이지를 통해 확인
MLflow Parameter
-
MLProject 파일 내의 parameter인자에 대한 정보를 추가하고 sys.argv로 사용할 수 있다.
-
run할 때,
-P param1=a -P param2=b와 같이 파라미터를 제공할 수 있다.
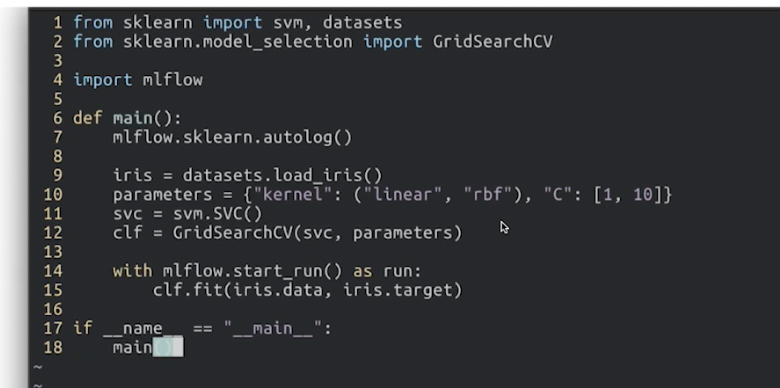
MLflow Hyper Parameter Tuning
- autolog와 함께 사용하여 튜닝도 가능하다.
MLflow 서버로 배포하기
MLflow Architecture
mlruns 폴더에서 확인가능
- 파이썬 코드(with MLflow package)
- 모델을 만들고 학습하는 코드
- mlflow run으로 실행
- Tracking Server
- 파이썬 코드가 실행되는 동안 Parameter, Metric, Model 등 정보 저장
- 파일 혹은 DB에 저장
- Artifact Store
- 파이썬 코드가 실행되는 동안 생기는 Model file, Image등의 아티팩트 저장
- 파일 혹은 스토리지에 저장
흐름

-
run
-
Tracking Server에 기록요청
-
Server가 DB에 기록. 외부 DB랑 연동할 수 있다.
-
Artifact Store 아티팩트 저장

지식 공유