Improving Language Understanding by Generative Pre-training
Abstract
자연어 이해는 광범위한 tasks(semantic similarity, document classification...)를 구성한다. 라벨링되지 않은 대용량 데이터는 충분하지만 특정 tasks 학습을 위한 라벨링된 데이터는 부족하기 때문에 모델을 적절하게 수행하기 위한 학습에 어려움이 있다. 이 연구에서는 라벨링되지 않은 text에 대한 언어모델의 gpt(generative pre-training)와 특정 task의 discriminative fine-tuning을 통해 큰 이점을 얻을 수 있다는 것을 보여준다.
Introduction
raw text로부터 효과적으로 학습하는 능력은 자연어처리의 지도학습에 의존성을 완하하는데 중요하다.
대부분 deep learning methods는 많은 양의 라벨 데이터를 필요로 하며 라벨 데이터가 부족한 영역에서는 depp learning methods를 적용가능성을 제한한다.
이런 상황으로 인해, 라벨링되지 않은 데이터로 부터 언어적인 정보를 활용할 수 있는 모델들은 시간과 비용이 많이 드는 데이터를 모으는것에 대해서 가치가 있는 대안을 제공한다.
라벨링되지 않은 text로부터 word-level이상의 정보를 활용하는 것은 아래와 같은 2가지 이유 떄문에 어렵다.
-
어떤 종류의 optimization objective가 전이학습에 효과적인 text representations를 학습하는데 효율적인지 명확하지 않다.
-
이렇게 학습된 representation을 효과적으로 target task에 이동시키는 방법에 대한 합의가 없다
GPT 논문에서는 unsupervised pre-training과 supervised fine-tuning을 조합을 사용하여 언어 이해의 tasks에 대한 semi-supervised approach대해 알아본다.
이 연구의 목표는 광범위한 tasks에 범용적인 representation을 학습하는 것이다.
연구를 하기위한 데이터로는 라벨링되지 않은 대용량 말뭉치와 target tasks를 위한 몇개의 라벨링된 데이터를 사용히며 라벨링되지 않은 데이터는 target task와 같은 영역일 필요가 없다.
훈련은 두가지의 절차를 통해 진행된다.
-
모델의 초기 파라미터를 학습하기 위해 라벨링되지 않은 데이터에 대해 language modeling objective를 사용한다.
-
그 후 지도학습을의 상응하는 objective를 사용하여 target task에 대해 fine-tuning한다.
연구에 사용되는 모델은 다양한 task에서 강력한 성능을 보여준 Transformer를 사용한다.
RNN과 달리 Transformer는 긴 text를 다루는건에 대해 더 나은 구조적인 메모리를 제공해준다.
task에 agnostic한 모델은 각 task에 대해 특별하게 설계된 구조를 가진 모델보다 더 나은 성능을 보여준다.
추가적으로 pre-trained된 모델에 대해 zero-shot behaviors에 대해서도 분석한다.
Related Work
Semi-supervised learning for NLP
sequence labeling, text classification와 같은 tasks에 적용할 수 있는 semi-supervised learning은 큰 관심을 끌고있다.
초기의 approach는 word or phrase 수준의 통계치를 계산하기 위해 라벨링되지 않은 데이터를 사용했다.
하지만 최근의 연구들은 다양한 tasks에서 성능을 향상시키기 위해 라벨링되지 않은 데이터로부터 훈련된 word embedding을 사용한 이점을 증명했다. 하지만 이런 approach는 주로 word-level의 정보만을 transfer하는 반면 이 연구에서는 더 높은 수준의 의미를 담는데 목표를 둔다.
Unsupervised pre-training
Unsupervised pre-training은 supervised learning objective를 수정하는것 대신 좋은 초기point를 찾기 위한 목표를 가진 semi-supervised learning의 특별한 하나의 케이스이다.
이 논문의 연구와 가장 비슷한 연구는 language modeling objective를 사용한 신경망의 사전학습을 포함하고 그 다음 target task에 맡게 supervision의 fine-tuning을 하는 부분이다.
Dai et al. and Howard and Ruder는 이 방법을 사용해 text classification의 성능을 향상시켰다. 하지만 pre-training 단계가 언어적인 정보를 포착하는데 도움을 주지만, LSTM을 사용한 그들의 모델은 예측하는 능력을 짧은 범위로 제한한다. 대조적으로 이 연구에서는 transformer를 선택하여 긴 범위의 언어적인 정보를 포착할 수 있음을 실험을 통해 증명했다.
Auxiliary training objectives
다양한 연구에서 부수적인 objective를 사용하여 성능을 높였고 이 연구에서도 사용하지만, 비지도 학습 단계에서 이미 target tasks와 관련된 언어적인 측면을 학습한다.
Framework
훈련 절차는 2가지 stage로 구성된다.
-
대용량 말뭉치에 대한 높은 수준의 언어 모델을 학습시킨다.
-
fine-tuning stage로 라벨링된 데이터로 모델을 task에 적응시킨다.
Unsupervised pre-training
주어진 tokens 에 대해 likelihood를 최대화 시킬 수 있는 표준 language modeling objective를 사용한다.
여기서 k는 context window size를 의미하며 조건부확률 P는 파라미터 의 신경망을 사용하여 모델링된다.
이 파라미터들은 확률적 경사하강법으로 훈련된다.
이 연구에서는 언어모델링을 하기 위해 multi-layer Transformer decoder를 사용한다.
따라서 input context tokens에 대해 Multi-headed self-attention을 적용하며 뒤이어 position-wise feedforward layer를 적용하여 target tokens에 대한 분포를 생성한다.
transformer_block
softmax
여기서 는 token들의 context 벡터이고
은 layer 수, 는 토큰 embedding matrix, 는 position embedding matrix이다.
Supervised fine-tuning
pre-training후 target task에 파라미터들을 적응시키기 위한 단계이다.
라벨 를 따라 로 이루어진 input token들로 구성된 라벨링된 데이터셋 를 사용하며 이 input들은 사전학습된 모델을 통과하고 마지막 transformer block을 출력값을 이용한다. 마지막 출력에 linear를 추가하여 label 를 예측하도록 한다.
softmax
아래의 수식을 최대화하는 방향으로 학습된다.
최종적으로 아래의 objective를 최적화 하게 된다.(with weight )
전체적으로, fine-tuning동안 필요로하는 추가적인 파라미터는 이고 토큰들을 구분하기 위한 embeddings 이다. (아래의 그림 참고)
Task-specific input transformations
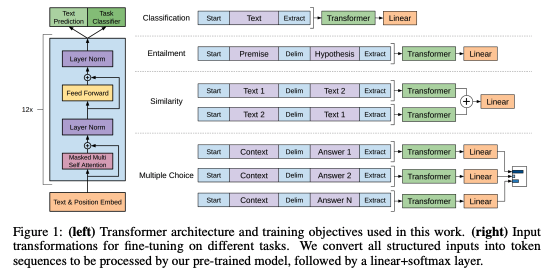
text classification과 같은 tasks에서는 바로 fine-tune이 가능하다.
그외의 task들에서는 사전훈련시 이어져있는 text로 훈련을 시켰기 때문에 약간의 수정이 필요하다.
이전의 연구들은 task specific한 구조를 사용했기 때문에 많은 양의 cutomization과 전이학습을 사용할 수 없었지만 GPT연구에서는 traversal-style approach로 접근하여 정렬된 input seqeunce로 구성하여 사전훈련된 모델에 적용하여 처리할 수 있다.

Experiments
12개의 데이터셋에서 9개 부문에서 SOTA를 달성했다.
Model specifications
largely model : follows original transformer work
masked self-attention을 가진 12개의 디코더 Layer ( 768차원, 12개의 attention head)
position-wise feed-forward : 3072 차원
optimizer : Adam ( max learning rate : 2.5e-4 )
scheduler : cosine annealing ( 0에서 max learning rate로 증가 2,000 updates )
mini-batch : 64
epochs : 100
contiguous sequences : 512 tokens
layernorm : N(0, 0.02)
vocab : using BPE, 40,000 merges
dropout : 0.1
L2 regularization : 0.01
activation function : GELU
fine-tuning details
dropout of classifier : 0.1
learning rate : 6.25e-5
batchsize : 32
epochs : 3
learning rate decay schedule with warmup : 0.2%
0.5
명시되지 않은 부분은 사전학습과 동일
Analysis
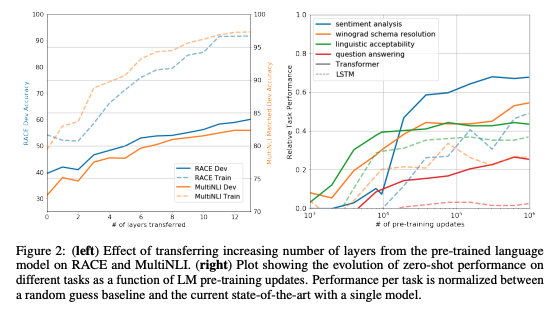
Impact of number of layers transferred
사전학습 단계에서 layer의 수를 변화시키며 그 영향을 살펴봤다.
위의 그림의 왼쪽 그래프를 살펴보면 layer수가 증가함에 따라 성능이 향상되는 것을 발견할 수 있고 layer가 12개 정도일때 그 값이 수렴하는것으로 보인다.
이 결과는 사전학습된 모델의 layer들은 target task를 풀기위한 효율적인 기능을 가지고 있음을 가르킨다.
Zero-shot Behaviors
supervised finetuning 없이 tasks를 수행하는 것을 관찰하여 transformer와 LSTM의 성능을 살펴본다.
위 그림의 오른쪽을 보면 전체적으로 transforemr가 우수한 성능을 나타내고 있다.
Ablation studies
3가지 다른 ablation 실험을 진행한다.
- fine-tuning에서 LM objective없음.
- auxiliary objective는 NLI, QQP task에서 도움을 주는것을 볼수 있다.
- 전체적으로 큰 데이터셋에서는 효과적이나 작은 데이터셋에서는 아닌것을 볼 수 있다.
- 동일한 framework를 사용하여 single layer 2048 unit LSTM과 Transformer를 비교
- LSTM을 사용할때 성능이 평균적으로 5.6% 하락
- 하나의 데이터셋(MRPC)에서만 Transformer를 능가함.
- GPT모델을 사전훈련없이 바로 supervised target tasks에 적용했을때를 관찰
- 모든 tasks에서 성능하락을 보임
- 결과적으로 약 15%의 성능하락.
Conclusion
라벨링되지 않은 긴 문장으로 이루어진 대용량 corpus로부터 모델은 전반적인 지식을 습득이 가능함을 보여줌
